

還記得安德烈·卡帕西(Andrej Karpathy)在上個月帶火的上下文工程嗎?他曾盛讚上下文工程“是一門精心設計、科學填充上下文窗口的精密藝術。”

圖 | 安德烈·卡帕西(Andrej Karpathy)在 2025 年 6 月發表的 X 貼文(來源:X)
時隔不到一個月,上下文工程更是被一衆科學家正式定義爲一門學科。日前,來自中美澳累計 6 家高校科研機構的 15 名研究人員,通過分析 1400 多篇研究論文,首次將上下文工程作爲一門正式學科加以全面探討,並指出它能夠系統性地設計、優化和管理大模型的信息有效載荷。

(來源:https://arxiv.org/pdf/2507.13334)
論文作者們分別來自中國科學院計算技術研究所、美國加利福尼亞大學默塞德分校、澳大利亞昆士蘭大學、北京大學、清華大學和中國科學院大學。論文中,研究人員將上下文工程確立爲開發複雜 AI 系統的關鍵基礎,並指出這類複雜 AI 系統的特徵在於能夠有效整合外部知識、維持持久記憶,以及能與複雜環境進行動態交互。
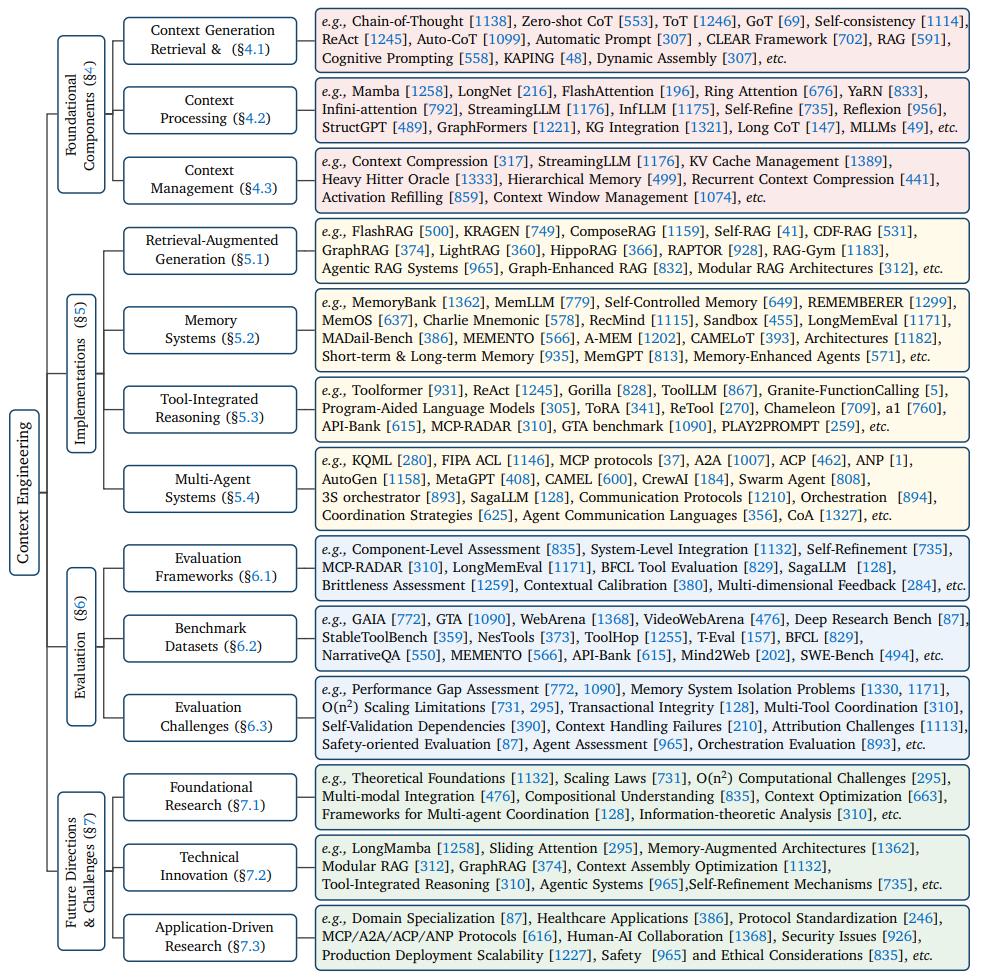
本次研究的主要貢獻在於提出了一個統一的分類框架,該框架將上下文工程技術分爲基礎組件和系統實現方法兩大塊。通過這一系統性的研究,他們得出了以下關鍵見解。
- 第一,儘管大模型在理解複雜語境上有着出色表現,但是在生成同樣複雜的輸出時卻存在侷限性,而這兩者之間存在根本性的不對稱,這種理解與生成之間的差距是大模型領域面臨的最關鍵挑戰之一。
- 第二,本次研究表明多種技術正在以日益複雜的方式進行協同融合,這種集成模式所產生的綜合能力已經超越各獨立組件的簡單疊加。研究人員所觀察到一個明顯趨勢是:模塊化和組合性不斷增強,使得架構能夠靈活適應各種應用,同時還能保持系統的一致性。
總的來說,通過系統地分析 1400 多篇論文,本次綜述論文不僅爲該領域確立了技術路線圖,還揭示了一個關鍵的研究空白:即模型能力之間存在根本性的不對稱。儘管當前模型通過先進的上下文工程得到了增強,在理解複雜上下文方面也有着出色表現,但在生成同樣複雜的長篇輸出時卻存在明顯的侷限性,而填補這一空白是未來領域內的首要任務。
(來源:https://arxiv.org/pdf/2507.13334)

將上下文工程進行概念化
很多人都知道,大模型的性能和效能從根本上取決於它們所接收的上下文。這種上下文——從簡單的指令提示到複雜的外部知識庫,是引導其行爲、擴充其知識和釋放其能力的主要機制。隨着大模型從基本的“指令遵循系統”演變爲複雜應用的“核心推理引擎”,設計和管理其信息載荷的方法也相應地演變爲上下文工程這樣一門正式學科。
當前,上下文工程領域正以爆炸性的速度擴展,催生了衆多專業且分散的研究方向。如前所述,研究人員將這一領域進行了概念化,進而指出上下文工程由以下兩個部分組成:基礎組件和系統實現方法。
基礎組件通過三個關鍵階段構成了上下文工程的系統性流程:
1.第一個階段是上下文檢索與生成,包括基於提示的生成和外部知識獲取;
2.第二個階段是上下文處理,這涉及到長序列處理、自我完善機制和結構化信息整合;
3.第三個階段是上下文管理,這涉及到內存層次結構、壓縮技術和優化策略。
這些基礎組件催生了更復雜的面向應用的實現方式,進一步地這些實現方式能夠將大模型與外部現實聯繫起來。
系統實現方法主要包括:
1.第一種是高級檢索增強生成,該技術目前已經發展爲模塊化、智能體驅動的架構,能被用於動態知識注入;
2.第二種是模擬人類認知能力以便實現持久信息保留的顯性內存系統;
3.第三種工具集成推理,它能將模型從被動的文本生成器轉變爲能夠動態利用工具和操縱環境的主動世界交互者。這種實現方式使模型能夠通過函數調用機制、集成推理框架和複雜的環境交互能力,突破其固有的侷限性。
4.第四種是基於智能體系統的完整生態系統,這種技術代表着目前上下文工程的巔峯技術,它能讓智能體利用函數調用和工具集成推理來與世界進行交互,並能夠通過依賴於複雜的智能體通信協議和上下文編排,進而在多智能體配置中實現複雜目標。
(來源:https://arxiv.org/pdf/2507.13334)

上下文工程的基礎組件、系統實現和評估
研究人員指出,當前大模型領域的碎片化發展掩蓋了技術之間的根本聯繫,也給業內人士帶來了研究障礙和使用障礙。因此,該領域迫切需要一個統一的框架來系統性地整合這些技術,進而闡明其基本原理,以及揭示它們之間的相互依賴關係。
隨着大模型從簡單的指令遵循系統演變爲複雜、多應用的核心推理引擎,與之交互的方法也必須隨之發展。
研究人員認爲,提示工程固然很重要,但是已經無法全面涵蓋現代 AI 系統所需的信息載荷的設計、管理和優化。關於此,在本文開頭的 X 貼文截圖中卡帕西也表達了類似觀點。原因在於,這些 AI 系統並非基於單一、靜態的文本字符串進行操作,它們利用的是動態、結構化且多方面的信息流。爲了彌補這一關鍵空白,本次綜述論文首次針對大模型的上下文工程進行了全面且系統的回顧,同時引入並規範了上下文工程這一學科。
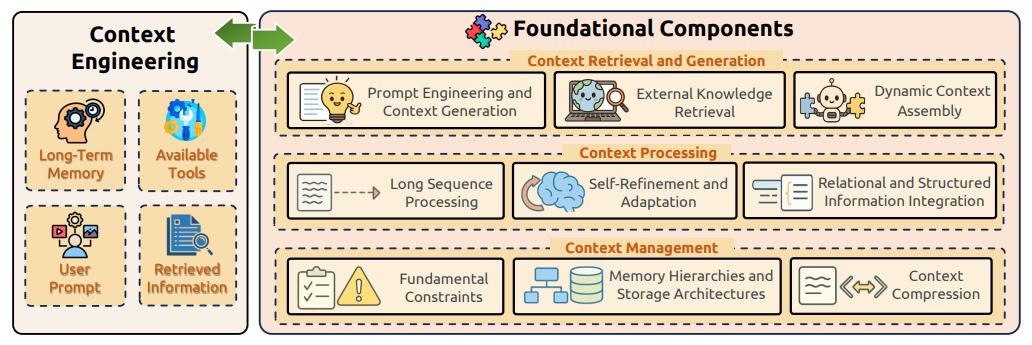
如前所述,上下文工程建立在三個基本組件之上,這些組件能夠共同應對大模型中信息管理的核心挑戰:
- 上下文檢索與生成,它通過提示工程、外部知識檢索和動態上下文組裝來獲取適當的上下文信息;
- 上下文處理,它通過長序列處理、自我優化機制和結構化數據整合,來針對獲取的信息進行轉換和優化;
- 上下文管理,它通過解決基本約束、實施複雜的內存層次結構以及開發壓縮技術,來處理上下文信息的有效組織和利用。
這些基礎組件爲所有上下文工程的實施奠定了理論和實踐基礎,並能形成一個全面的框架。其中,每個組件都能處理上下文工程流程的不同方面,同時各組件之間保持協同關係,從而實現全面的上下文優化和有效的上下文工程策略。
基於上下文工程的基礎組件,研究人員探討了複雜的系統實現方式,這些實現方式可以將上述組件整合到實用的智能架構中,同時這些實現代表了從理論框架到可部署系統的演進。
如前所述,研究人員提出了四類系統實現方式:
- 第一類實現方式是檢索增強生成系統,它通過模塊化架構和圖增強方法實現外部知識的整合。
- 第二類實現方式是內存系統,它通過複雜的內存架構展示了持續的上下文管理,從而能夠支持長期學習。
- 第三類實現方式是工具集成推理,它通過函數調用和環境交互,將語言模型轉化爲能夠與世界交互的實體。
- 第四類實現方式是多智能體系統,它通過通信協議和編排機制呈現出協調一致的方法。
以上四類實現方式中的每一個都基於基礎組件構建,同時解決了上下文利用中的特定挑戰,展示了理論原則轉化爲實際系統的背後原理。
(來源:https://arxiv.org/pdf/2507.13334)

“AI 模型的性能本質上取決於上下文信息”
研究人員指出,當前上下文工程正處於一個關鍵的轉折點,當前這種基礎進展與新興應用需求相融合的階段,既創造了前所未有的創新機遇,也暴露出了一些必須在多個維度開展持續研究才能解決的根本性挑戰。
隨着該領域逐漸從孤立的組件開發向集成系統架構過渡,一些研究難題的複雜性也會呈現指數級的增長,因此需要採用跨學科的方法,將理論計算機科學、實用系統工程和特定領域專業知識結合起來。
基於此,研究人員通過本次論文爲 AI 從業者提供了一個統一的框架。與此同時,研究人員通過本次研究所發現的大模型評估挑戰,凸顯了該領域對於全面評估框架的需求,這類全面評估框架需要能夠捕捉上下文工程系統所展現出的複雜、動態的行爲。因此,傳統評估方法對於多組件集成、具有自適應行爲且長期持續運行的大模型來說已經顯得力不從心。但在這之中也蘊含着一些重大機遇,比如未來人們可以開發用於高效長上下文處理的下一代架構、構建智能上下文組裝系統,以及打造多智能體的協調機制等。
總的來說,本次綜述論文不僅呈現了該領域的一些現狀,也爲未來研究提供了路線圖,並將上下文工程確立爲一門獨立學科,它的獨立性體現在它擁有獨屬於自身的原則、方法和挑戰,能夠推動並支持具有上下文感知能力的AI 模型實現“負責任”的發展。
而隨着大模型的不斷髮展,“AI 模型的性能本質上取決於上下文信息”的這一關於上下文工程的核心洞見,仍將在 AI 模型的發展中佔據關鍵地位。未來,隨着 AI 模型逐漸朝着複雜的多組件系統發展,上下文工程有望在 AI 發展中扮演日益核心的角色。而上下文工程的跨學科性質,即其涵蓋計算機科學、認知科學、語言學以及特定領域專業知識的特點,也要求人們必須採取跨領域合作的方法來將 AI 之路走寬走遠。
參考資料:
https://arxiv.org/pdf/2507.13334
https://x.com/karpathy



