

近日,機器學習與決策控制領域的知名專家、美國加州大學伯克利分校副教授、Physical Intelligence 聯合創始人 Sergey Levine,在其個人博客上發表了一篇題爲《人工智能的叉勺》(Sporks of AGI)的文章。深入探討了在機器人學習領域中數據獲取的核心挑戰,尤其對當前普遍依賴的“替代數據”策略提出了批判性思考。

圖丨Sergey Levine(來源:MIT Technology Revie)
文章開篇就直指機器人技術發展的核心痛點:數據。與主要依賴文本和圖像數據的大語言模型和視覺語言模型不同,訓練機器人所需的視覺-語言-行爲(VLA,Vision-Language-Action)模型,需要的是機器人在真實物理世界中進行交互和執行任務的數據。這類數據的採集不僅成本高昂、效率低下,而且難以規模化,這成爲了訓練強大、通用機器人模型的主要障礙。
圖丨相關博文(來源:Sergey Levine)
因此,研究界一直在尋找“次優選擇”(The Next Best Thing),即用一些成本較低的替代數據(surrogate data)來取代真實世界的數據。文章將當前研究界爲繞過數據難題而採用的各種“捷徑”——例如在模擬器中訓練、從人類視頻中學習、或使用模仿機器人夾爪的設備——比作“叉勺(Spork)”。叉勺試圖同時擁有叉子和勺子的功能,卻最終在兩方面都表現平平,無法真正替代其一,甚至會隨着模型能力的增強而變得更加有害。因此,他呼籲研究者正視困難,迴歸“真實之物”(The Real Thing),強調只有真實、海量的物理世界交互數據,纔是通往通用機器人智能的必經之路。
以下是博文的完整內容:
爲什麼“真實之物”優於“次優之選”
訓練大模型真的很難,而且隨着模型變得越來越大,並擴展到新的領域時,只會變得更難。大語言模型使用大量文本數據,視覺語言模型需要文本和圖像,而機器人領域的視覺-語言-行爲模型,則需要機器人在真實世界中執行真實任務的數據。這對智能體(agent)來說尤其困難:無論你是想控制一個真實世界的機器人,還是想在網絡上執行操作以滿足用戶請求,帶有行爲標籤的真實世界交互數據,都無法像網絡上的文本和圖像那樣廉價地獲得。
因此,研究人員一直在努力尋找一種方法,用“次優之選”(The Next Best Thing)來替代真實數據和行爲,試圖兼得兩者的優點:既擁有在海量數據集上訓練大型模型所帶來的強大能力和泛化性,又付出一個遠低於在領域內(in-domain)爲基礎模型收集標準訓練數據所需的成本。
次優之選
雖然在視覺感知和自然語言處理等領域,真實世界的原始數據一直都是首選,但當涉及到智能體——特別是機器人智能體(例如 VLA 模型)時,人們總有一種不可抗拒的衝動,想要找出如何使用別的東西,某種可以廉價獲取的“替代品”(surrogate),但它又能提供我們所追求的那種廣泛的泛化能力。
我們可以使用一些方法來記錄人類自己以一種更“機器人化”的方式執行任務的視頻。這個領域已經有了大量激動人心且極具創造性的研究,如果稍作概括,可以將其描述如下:手動定義一個廉價的替代域(surrogate domain)與真實世界機器人系統之間的映射或對應關係,然後利用這種對應關係,使用廉價的數據來代替昂貴但有代表性的領域內數據(即來自目標域中真實機器人的數據)。每一種被廣泛研究的、用以避免收集真實機器人數據的方法,都基於類似的想法:
- 模擬(Simulation):從模擬到現實(sim-to-real)的方法需要人類設計師來指定機器人訓練的環境並生成必要的資產。在模擬中學到的行爲是這些選擇的產物。通常,能帶來最佳結果的模擬環境,並不是對現實的精確建模(這非常困難),而是對機器人需要應對的各種變化類型進行編碼,比如在隨機的墊腳石或高度場上進行訓練。這進一步凸顯了人類的洞察力不僅決定了任務是什麼,還間接指明瞭任務應該如何解決。
- 人類視頻(Human videos):那些純粹從人類視頻中學習機器人技能的方法,通常需要定義某種人類與機器人之間的對應關係,比如抓取時手或手指放置的位置。任何此類選擇都預設了一種特定的任務解決方法(例如,用強力抓取的方式撿起和移動物品),並且還需要在物理上可行的人類動作與機器人動作之間架起一座巨大的橋樑,無論是在動力學上還是在外觀上。
- 手持夾爪設備(Hand-held gripper devices):我們可以在學習過程中,通過讓人們使用模仿機器人夾爪的手持設備來收集數據,從而在物理上強加一種人機映射。這確實是一種將人類意圖轉化爲機器人動作的非常直接的方式,但它也帶來了自身的挑戰:例如,一個沒有手臂的懸空夾爪的動力學特性與一個完整的機器人手臂是截然不同的。
所有這些方法都促成了有趣且相關的研究,並取得了一些出色和令人興奮的實踐成果。但是,我認爲它們中的每一種都代表了一種妥協,而這種妥協最終會破壞大型學習模型的真正力量。
交集
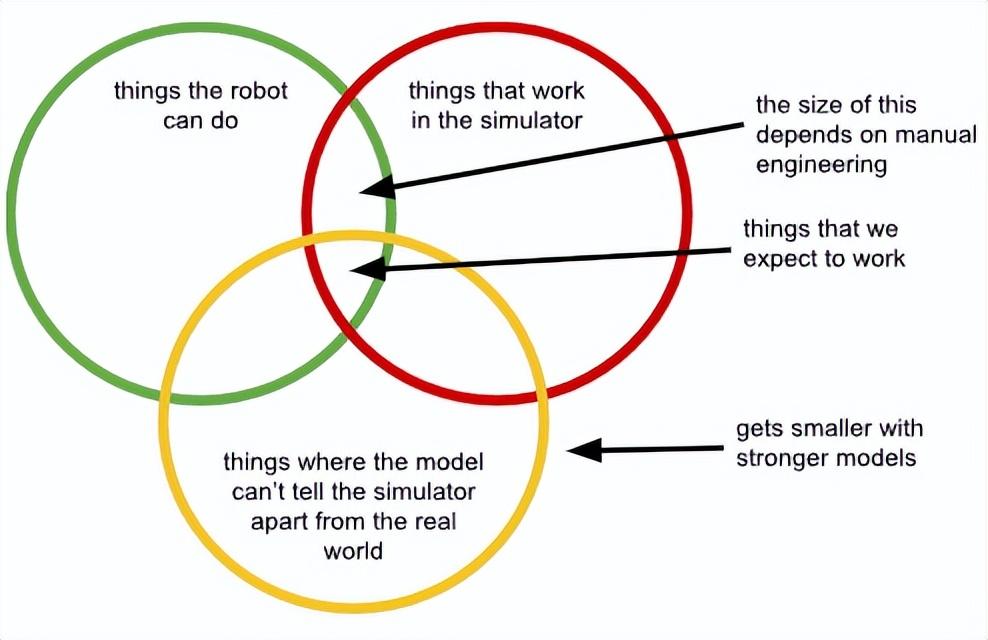
當然,在收集數據時,人類的判斷是不可避免的:即便是最原始、最純粹的“白板式”學習方法,也需要我們定義一些關於我們希望模型做什麼的事情。但是,當我們爲了迴避真實數據而做出設計決策時,這些決策可能會帶來特別大的麻煩,因爲它們內在地限制了問題可以被解決的方式。
每存在一個域差距(domain gap)(無論是模擬、視頻還是其他),我們都會被限制在這樣一個解決方案空間裏:它必須位於那些在我們的系統上實際有效的行爲、可以用我們選擇的方法(例如,模擬或手持夾爪)完成的行爲,以及——這一點至關重要——那些不會加劇領域間差異的行爲(例如,不會暴露機器人其實沒有手持夾爪,或不會觸發一個特別嚴重的模擬/現實世界差異)的交集之中。
此外,隨着我們使用更大、更強的模型,我們應該預料到會從這些問題中感受到更強的阻力:因爲更強大的模型能更緊密地擬合數據中的模式,它們將越來越多地擬合那些(我們不希望的)差異,就像它們學習我們想要學習的、真正的可遷移模式一樣。
(來源:Sergey Levine)
在研究項目和演示中,這些問題可能看起來無傷大雅,因爲我們可以設置真實機器人,讓這種差異變得不那麼重要,比如選擇那些最佳和最魯棒的策略恰好就落在這個交集內的環境和物體。但在真實的開放世界環境中,這不僅是侷限性的,它實際上破壞了訓練大型、強大基礎模型的主要優勢。
首先,隨着模型越來越強,從而越來越能分辨出替代數據域和真實世界域的差異時(即上圖中黃色圓圈縮小時),這個交集會變得更小。我們可以嘗試通過向模型隱藏信息、減少觀察空間、使用域不變損失函數、限制機器人可以使用的攝像頭視角等方法來抵消這個問題。實際上,幾乎所有解決這些域差異的方法,最終都歸結爲某種形式的信息隱藏。但這再次破壞了基礎模型的根本優勢,即它們合成複雜信息源並提取人類難以手動識別的微妙模式的能力。基本上,隨着我們使用更強的模型,黃色圓圈會變小,而任何試圖抵消這一點的嘗試,最終都會使模型變弱。我們只能通過“給我們的模型做腦葉切除手術”(lobotomizing them),來“愚弄”它們,阻止它們意識到自己身處《黑客帝國》(The Matrix)之中。
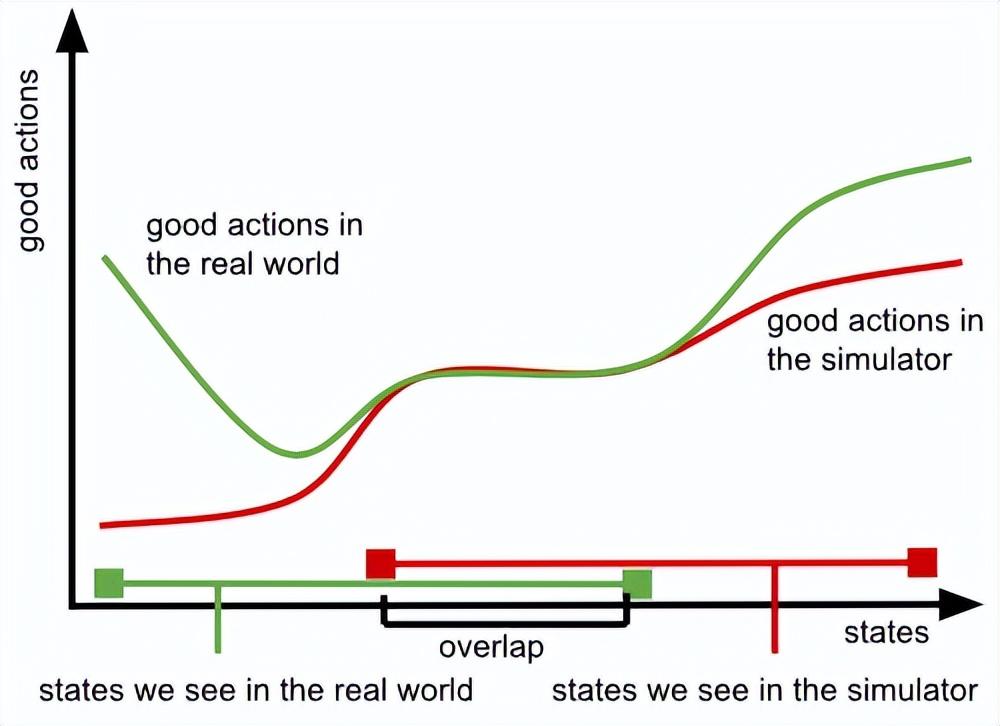
這個交集的大小,也關鍵性地取決於我們在設計替代數據時所做的決策——這些決策越差,綠色和紅色圓圈之間的交集就會越小。在實踐中,我們會爲我們的替代數據(我們的模擬器或手持數據收集設備)進行設計,以便在我們設想的少數應用領域中,這種差異被最小化,以確保好的動作(即那些能導致成功的動作,或至少能避免災難性失敗的動作)在替代數據和真實機器人之間能夠匹配。但在這些應用領域之外,無法保證它們還會匹配。
(來源:Sergey Levine)
所有這些問題,在我們真正想要優化出最佳行爲(例如,通過強化學習)時,都會變得更加嚴重,因爲我們無法在不走出“機器人能做的、在替代數據中有效的、且模型無法分辨差異”這個狹窄交集的情況下,充分利用真實機器人系統的全部能力。
真實之物
在試圖迴避使用真實世界數據的過程中,我們其實是在尋找一個“兩全其美”的解決方案:某種既像模擬或視頻那樣廉價,又具備真實世界數據有效性的東西。
在機器學習中,持續有效的最佳方法是確保訓練條件與測試條件相匹配。這就是“真實之物”(The Real Thing)——那些教會模型世界究竟如何運作的數據,這樣它才能做好自己的工作,提取潛在的模式(其中許多模式對於人類來說都過於微妙和複雜,難以理解),然後從這些模式中進行推斷,以解決複雜的新問題。當我們用替代數據來替換真實數據時,我們其實在做的是“次優之選”:一個在少數特定條件下能夠匹配真實情況的替代品。就像你無法通過對着牆打球或在電視上看羅傑·費德勒的比賽而成爲一名網球專家一樣——儘管這兩者都複製了真實網球體驗的某些方面——機器人也無法掌握真實世界,除非它能看到自己在真實世界中做事。
我們應該從中得到什麼啓示?主要啓示是,如果我們想真正構建能夠像大語言模型和視覺語言模型在虛擬世界中那樣,在真實物理世界中廣泛泛化的機器人基礎模型,那麼真實數據是不可或缺的。
但我們也不應“把嬰兒和洗澡水一起倒掉”:保持務實很重要。就像 LLM 和 VLM 使用大量與其最終目的並非高度相關但包含了有用世界知識的數據一樣,我們的機器人基礎模型也可以使用許多不同來源的數據。畢竟,如果你想成爲一名優秀的網球運動員,觀看費德勒的比賽是有用的。如果我們在訓練集中,除了廣泛且有代表性的真實世界機器人經驗之外,還包含多樣化的數據,包括來自人類甚至模擬的數據,這很可能會有幫助。我只是想說,這可能比完全迴避真實世界數據的需求要容易得多:一旦我們不再需要擔心只在機器人能力和我們替代數據覆蓋範圍的交集中學習,就可以拋棄那些旨在縮小域差距的“柺杖”,並接受替代數據的本來面目:它是一種輔助知識來源,旨在補充真實世界的經驗,幫助你成爲一名優秀的網球運動員。
The Sporks
在這篇文章中,我討論了替代數據,這是一種試圖在不付出大規模領域內數據收集成本的情況下,獲得規模化訓練好處的“叉勺”(spork)。這並非 AI 研究人員鍾愛的唯一一種“叉勺”。其他“叉勺”還包括:結合了人工工程和學習組件的混合系統;使用人工設計的約束來限制學習型自主系統不良行爲的方法;以及將我們關於問題應該如何解決的直覺嵌入到神經網絡結構本身的方法。它們都試圖獲得兩全其美:既有大規模機器學習的好處,又沒有隨之而來的高數據需求或大量目標設計(“對齊”或“後訓練”)的缺點。
在深層次上,它們有很多共同點——通過某種形式的人工設計的歸納偏置(inductive bias)來解決訓練不完整帶來的挑戰。因此,它們有一個根本性的缺點:它們要求我們植入“我們認爲我們是如何思考”的方式。大規模機器學習的成功,歸根結底在於機器學習的力量勝過人類設計——這就是 Richard Sutton 所說的“慘痛的教訓”(The Bitter Lesson)。“慘痛的教訓”的一個必然推論是,在任何支持學習的系統中,任何未經學習而是通過手工設計的組件,最終都會成爲其性能的瓶頸。“叉勺”之所以吸引人,是因爲它們讓我們以爲可以通過強制模型以特定方式解決問題來克服重大挑戰,但最終,這隻會讓我們的學習系統變得更不可擴展,即便我們的初衷恰恰相反。
參考資料:
https://sergeylevine.substack.com/p/sporks-of-agi
運營/排版:何晨龍



