夢瑤 發自 凹非寺
量子位 | 公衆號 QbitAI
文本一長就糊、指令一雜就撂挑子、遇到中文更是一整個變形freestyle……
「AI生圖」的這點苦,到底有誰懂啊!!!

停,不用擰巴了,因爲現在的AI,已經能穩穩喫下1K token的超長文字指令了:

複雜指令也不在怕的,最近OpenClaw賊火,我索性讓AI直接幫roll出一個賽博信息圖海報(你就說牛不牛吧):

中文渲染表現也不孬,《蘭亭集序》這種公認的高難度文本,這AI居然能做到文字1:1還原,排版、筆鋒都在線:

你以爲到這兒就結束了,NONONO!因爲它還能——多圖編輯。
隨手丟給了它一張照片,人家直接給我甩出一組影棚級的9宮格寫真!!(誒,突然感覺怒省一筆錢…

剛纔幫我幹活的這位,正是阿里剛剛發佈的新一代圖像生成及編輯模型——Qwen-Image-2.0。
1K token長文本、複雜指令、中文渲染、圖片編輯、2K分辨率一次性梭哈,連國際評測裏的表現都已經衝到了僅次於Nano Banana Pro的位置。
不廢話,這個中文版Nano Banana到底能不能打,咱實測見真章!!!
Qwen-Image-2.0 一手實測
複雜指令理解準,1K token文本玩得轉
在AI生圖界,最讓人崩潰的倒不是寫Prompt詞,而是寫了太多,AI根本不喫消,好的提示詞真無!處!施!展!
不知道千問團隊受了啥啓發,這次在Qwen-Image-2.0中把提示詞的輸入字符硬生生搞到了「1K token」,而且對複雜指令的生成準確率也上了一個level。
換句話說,現在咱喂進去一大段「七八九百字」的超長地獄級提示詞,對AI來說也是《手拿把掐》了。

但老話講得好,光說不練假把式。
你說1K token就1K token?你說這AI能理解複雜指令就能理解?咱還得實測說的算!
先來道開胃菜,最近水墨風多宮格漫畫在網上賊火,我直接反手就是輸入一個長達700字,且包含複雜指令的提示詞:

這個提示指令的難度在於,既需要AI理解五宮格結構、時間推進、空間切換、人物關係與統一畫風,還需要把700字的長文本消化理解到位,這對長上下文保持一致性要求很高!!!
結果還沒一分鐘,Qwen-Image-2.0就給我搓出來了完成度明顯高於我預期的唐僧師徒西天取經的「五宮格漫畫」:

仔細看會發現,夜行、火焰山、打鬥這些場景區分都很明顯,而且人物形象穩定,唐僧、孫悟空、豬八戒、沙僧都保持了較好的角色一致性。
連唐僧臉上的emo情緒都還原得很到位,該有的要素一個不差???
(不是,家人們,我有點驚了…)
emm…一張圖說明不了啥!
這回咱再試一個Nano Banana裏很火的「美食爆炸圖」玩法,看看AI能不能接住招!
這次我輸入了一段長達600多字的提示詞,逐層描述漢堡的十種食材及其上下位置,對AI的結構理解與還原能力提出了很高要求:

萬萬沒想到,一個顏值和完成度都拉滿的「商業級」2k分辨率的漢堡分解信息圖,就這麼被AI搓出來了:

質感自然沒得說,牛肉餅的焦化紋理、芝士拉絲、醬汁流動都很真實,文字也沒有出現變形問題,每一層食材之間的距離也把控得很完美,強迫症患者狠狠愛了!!!
漫畫和美食玩夠了,咱再來試試城市特效玩法。
這回咱讓AI在「畫軸+立體城市+微縮建模+2k分辨率」多重要求同時成立的前提下,生成一幅上海市的3D景觀:

說一句不誇張的,這張已經有點鉅作內味了,完成度甚至比不少我在網上看到的爆款案例還要高……

從結構上看,畫軸與上海城市的結合非常自然,卷軸的展開方向剛好承載了城市縱深。
此外,高樓、道路、水面、人物之間沒有明顯失衡,夜景燈光、車流光帶、水面反射也都處理得很細,這Qwen-Image-2.0屬實是把複雜指令和超長提示詞妥妥拿捏了…
最後咱再來試試微觀景觀玩法,讓AI搓一個2k微距攝影視角下的「大米王國」:

在提示詞的設計中,既要求AI將大米放大到地形級的尺度,又要保證微縮人物的比例、動作和受力邏輯真實,還得在同一畫面中呈現搬運、裝袋、協作的勞動場景,一旦有一項沒對齊,畫面就會立刻出戲!!!
沒失望啊沒失望,一個誤入米粒世界、微縮人們圍着巨型大米忙得熱火朝天的奇妙場景,就這麼水靈靈被搓出來了:

u1s1,整體完成度還是很高的,微縮比例關係準確,大米的尺度誇張但邏輯自洽,而且米粒的半透明質感、裂紋細節和淺景深處理讓畫面非常接近真實微距攝影了。
看來,Qwen-Image-2.0的1K token的超長文本輸入和複雜指令理解力,還是有點說法的…

多圖編輯手拿把掐
有朋友看到這兒該問了,光能文字生圖有啥用啊,編輯能力纔是最實用的。(大聲)
好巧不巧,除了基礎的文生圖外,這次Qwen-Image-2.0的另一大超實用的能力,那就是——圖片編輯!
具體講呢,我們可以通過上傳一張或多張圖片,通過提示詞指令讓AI進行二創、修改等編輯操作~
咱先來玩一個NanoBanana超火的OOTD拼圖玩法,讓圖1中的女孩穿着圖3的裙子,站在圖2的車身前:
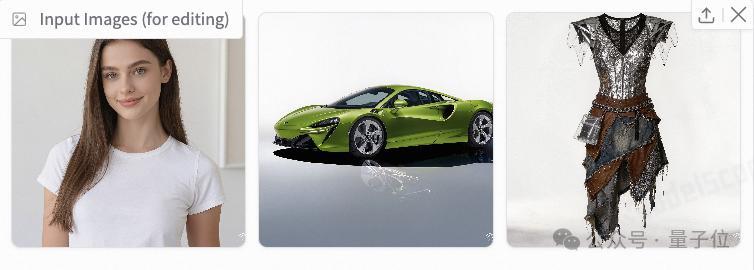
別說嗷,真一點違和感沒有,衣服和女孩的融合得也非常好,不僅如此AI還把汽車的倒影給補足還原了,666…

咱再來試一個九宮格自拍照編輯玩法,只喂一張照片,再給一句九宮格需求指令,我就得到了一套影棚級寫真!

不光如此,人家連文案都給你一塊包了,我讓AI給第一張水墨畫寫了首詩,小詞一放上去,古風味兒立馬就出來了:

能改圖、能加字、能拼圖,好好好,這下真·萬物皆可編輯了。
感覺下個月我P圖軟件的會員真不用續費了……
中文漢字渲染極夯
其實從Qwen Image模型剛出的時候,我就對它中文渲染的強大能力的《略有耳聞》。
只是沒想到,到了2.0,這本事又進化了…..
因爲我發現,哪怕一張圖都不喂,只簡單說了一句「生成一個一文看懂的科普信息圖表,解釋熬夜的危害」,Qwen-Image-2.0給我的,已經是一張數字、漢字、英文全都安排得明明白白的科普海報了:

此外,它還能將文字和畫作進行完整融合,看下面這個雪雕版的冰雪大世界,遠看是字,近看是景,文字和周圍的積雪融合得恰到好處!

即便黑板報中充滿數字、符號和中文,文字依然能夠做到1:1還原,更難得的是整體排版依舊規整,每個字的筆鋒和間距看起來都很舒服:

漢字完整度和一致性都很高,幾乎沒有亂碼或假字,數字、符號和公式渲染準確,已經達到可直接閱讀的水平了。
誒?感覺非常適合拿來處理咱日常的一些海報文案、信息圖表內容,這可比自己往圖上一個個P字兒快多了…

實測之外,國際表現同樣能打
實測中能打,國際表現也不孬。
在AI Arena模型評測中, Qwen-Image-2.0在文生圖、圖生圖兩個基準測試裏也都跑出了相當靠前的成績,僅次於谷歌Nano Banana Pro和GPT Image 1.5:
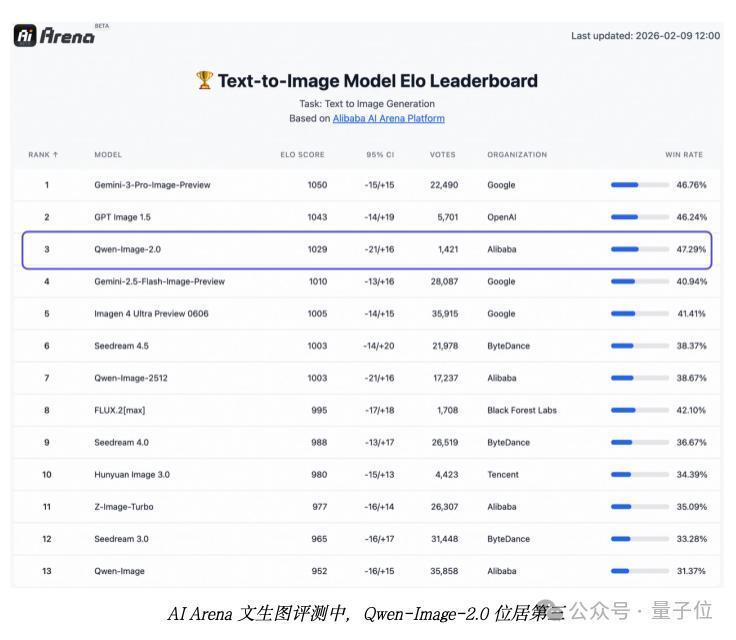
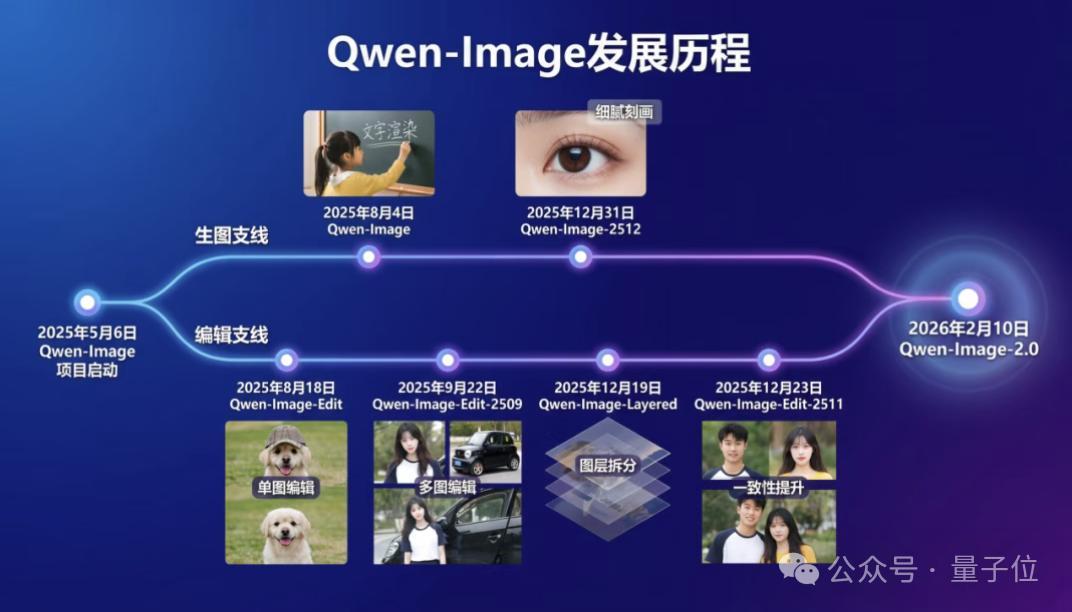
其實回頭看Qwen-Image的演進路徑,這個結果算不上意外。
早些時候,千問一直在兩條方向上同時推進:一條主攻生圖能力,一條持續打磨編輯能力。
去年8月發佈的Qwen-Image更偏向文字渲染的準確性,12月的Qwen-Image-2512則把重心放在細節質感和真實度上,與此同時,從單圖編輯到多圖編輯,再到一致性能力,也一步步補齊。
到了這次的Qwen-Image-2.0,相當於把這兩條路線收攏到同一個模型裏,生圖和編輯同時在線,整體表現也就更穩了。
以中文文字渲染爲例,過去這一方向長期受限於VAE壓縮帶來的損失:
小字號、密集排版對壓縮極其敏感,信息密度越高,重構難度越大,生成結果也越容易糊。
圍繞這一痛點,Qwen-Image-2.0在VAE與生成模型兩端同步升級,小字與高密度文字場景下的可讀性明顯提升,PPT、信息圖這類場景終於能穩定輸出可直接使用的圖像。
參數規模上,Qwen-Image-2.0也做了進一步收斂。
在能力提升的同時,模型體量更輕,部署門檻更低,生圖速度更快,尤其適合高頻prompt調試、實時展示和交互式創作等使用場景~

站在真實使用者的角度,這次實測下來最大的感受只有三個字——「超預期」。
對我而言,平時看一個生圖模型好不好用,從來不太糾結參數本身,更在意它能不能在不反覆抽卡的情況下,直接給出讓我滿意的結果。
這背後包括幾個很實際的點:
提示詞信息能不能完整呈現、生成速度快不快、畫面好不好看,以及編輯能力夠不夠強大順手。
而從這次體驗來看,Qwen-Image-2.0幾乎把這些日常生圖時最容易翻車的地方,一次性都補齊了:
1K token的指令支持,讓我可以儘可能把提示詞寫完整;2K分辨率輸出,保證了畫面的質感;而生圖與編輯二合一的能力,讓很多修改都能直接在生成結果上完成,省去了咱來回切換其他修圖軟件的麻煩。
好用、好看、真實、好玩,對我來說這就夠了。
目前阿里雲百鍊上已開通API邀測。
開發者也可通過Qwen Chat(chat.qwen.ai)免費體驗新模型,感興趣的友友不妨直接自己上手搓一把!!!