當一個大型語言模型(LLM,Large Language Model)被要求“在心裏想一個數字”並確認完成後,它是否真的在內部“記住了”這個數字?來自美國約翰斯·霍普金斯大學和中國人民大學的研究團隊通過一項新研究指出,答案可能是否定的。
圖丨當 ChatGPT 說它已經想好了一個數字,而且不是 4,我們如何知道 ChatGPT 是否在說謊?(來源:arXiv)
這篇發表於 arXiv 預印本平臺的論文《大型語言模型不具備類人工作記憶》(LLMs Do Not Have Human-Like Working Memory),通過一系列實驗論證,當前主流的 LLM 雖然在處理語言任務上表現出色,但它們普遍缺乏一種對高級認知至關重要的能力——工作記憶。

圖丨相關論文(來源:arXiv)
這項研究認爲,LLM 的許多行爲,如產生矛盾信息或在複雜推理中失敗,其根本原因可能在於它們無法像人類一樣,在內部主動地、臨時地存儲和處理信息。
在認知科學中,工作記憶是一個核心概念。它指的是一個容量有限的系統,負責在執行思考、推理、學習等複雜任務時,臨時性地存儲並主動處理相關信息。例如,在不使用紙筆進行心算時,大腦就需要依靠工作記憶來暫存中間計算結果。這是一個主動、內化的心理過程。
研究人員強調,LLM 所依賴的“上下文窗口”與工作記憶存在本質區別。上下文窗口允許模型在生成回應時,回顧之前的對話歷史。這更像是一種被動的查閱,所有信息都以文本形式外在地、明確地存在。相比之下,人類的工作記憶是在沒有外部提示的情況下,於內部對信息表徵進行操縱。當前對 LLM 能力的評估,很多時候混淆了這兩種機制。
爲了準確評估 LLM 是否具備內化的工作記憶,研究團隊設計了三個實驗,其共同點在於,要求模型處理的信息並不直接存在於其可訪問的上下文(prompt)中。
第一個實驗簡單而犀利。研究團隊讓各種 LLM“在心中想一個 1 到 10 之間的數字”,然後分別詢問是否爲每個特定數字。關鍵在於數學邏輯:如果模型真的選擇了一個數字並誠實回答,那麼所有“是”回答的概率總和應該接近 1。這是因爲在 200 次獨立測試中,如果模型每次都真的選擇一個數字,那麼對所有可能數字的"是"回答頻率加起來應該大致等於 100%。
結果發現。在測試的衆多模型中,大部分的概率總和接近於 0。例如,GPT-4o-Mini、GPT-4o 的多個版本以及 Qwen 系列模型,它們對所有數字的“是”回答概率加起來都是 0,這意味着它們幾乎從不給出肯定回答。即使是表現相對較好的模型,如 LLaMA-3.1-405B,其概率總和也達到了 1.195,超過了理論上限。
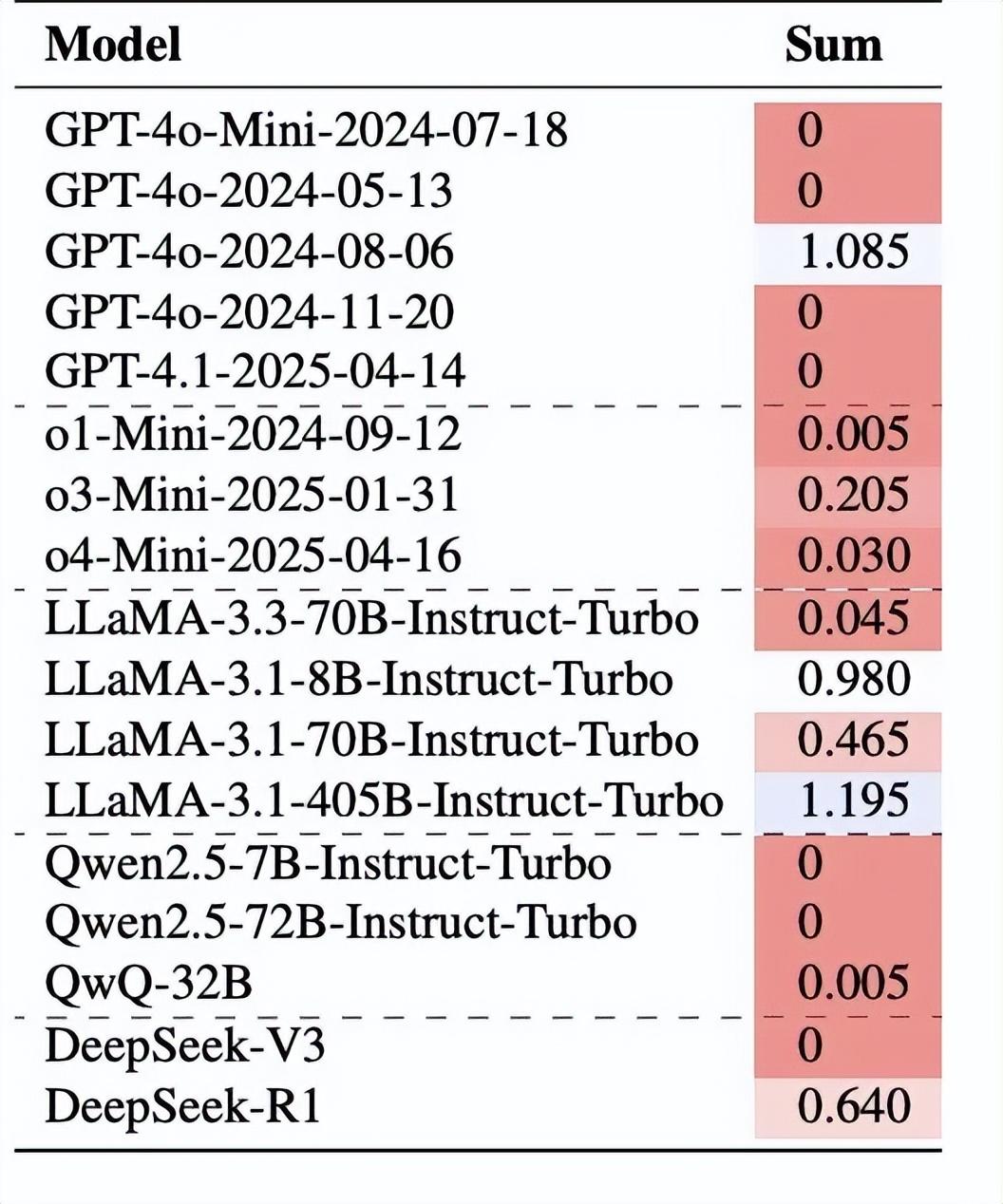
圖丨每個模型對從 1 到 10 的所有數字回答“是”的概率之和(來源:arXiv)
這種現象表明什麼?要麼這些模型根本沒有真正“想”任何數字,要麼它們在某種程度上“撒謊”了。更可能的情況是,它們缺乏維持內部狀態的能力,無法在對話過程中保持一個一致的心理表徵。
團隊還發現,當模型確實給出“是”的回答時,它們表現出對數字 7 的強烈偏好。這種現象在人類中也存在——心理學研究表明,當被要求隨機選擇一個數字時,人們往往傾向於選擇 7。但在 LLM 中,這種偏向可能並非來自真正的認知過程,而是訓練數據中的統計規律。
研究者還測試了不同數字範圍的影響。令人困惑的是,當範圍較小(如 1-3 或 1-5)時,某些模型反而表現出強烈的“是”傾向,概率總和遠大於 1。而當範圍較大(如 1-40)時,模型又幾乎不給出任何“是”的回答。這種不一致的表現進一步證實了 LLM 缺乏穩定的內部狀態管理能力。
第二個實驗更加接近真實的認知測試。研究者讓模型想象一個物體,然後問一系列比較性問題,比如“這個物體比大象重嗎?”、“它比貓輕嗎?”等等。如果模型真的在“想象”一個具體物體,它應該能夠保持回答的一致性。
研究團隊預先定義了 60 種不同的物體,按照體積、長度、重量、密度和硬度五個屬性進行排序。然後持續向模型提出多達 250 個比較問題,記錄模型在第幾個問題時出現自相矛盾。
結果顯示,較小的模型(如 GPT-4o-Mini)幾乎總是出現自相矛盾,200 次試驗全部失敗。即使是更大的模型 GPT-4o,也只有 27 次試驗(13.5%)沒有出現矛盾。更重要的是,模型出現矛盾的時機呈現出一定的規律性:GPT-4o-Mini 通常在 20-30 個問題後開始自相矛盾,而 GPT-4o 能堅持到 30-40 個問題。
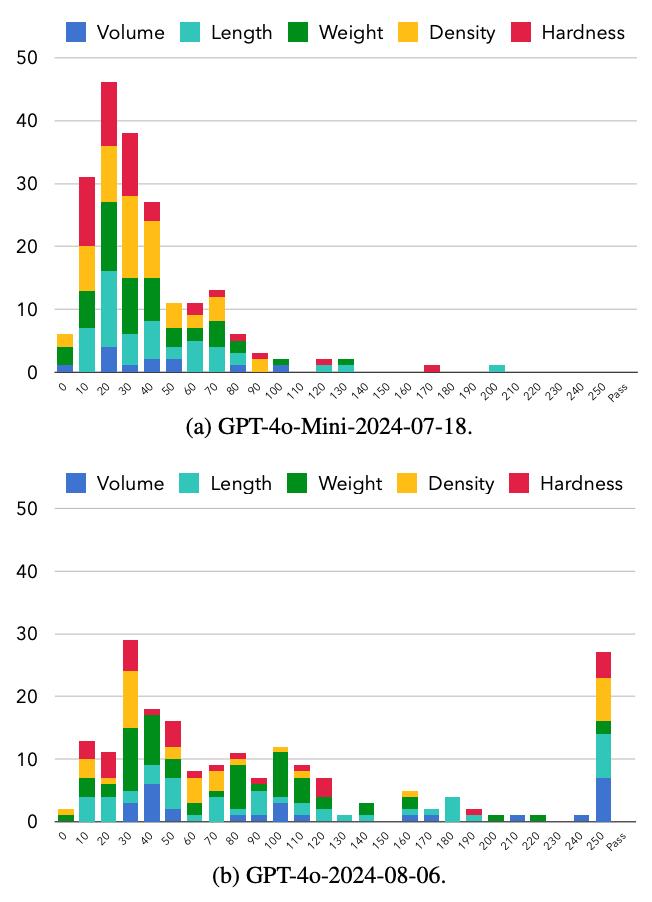
圖丨兩個模型出現自相矛盾問題的數量的直方圖(來源:arXiv)
這種漸進式的失敗模式揭示了一個關鍵問題:LLM 並非真正在“想象”一個物體,而是試圖通過檢查之前的回答來保持一致性。隨着問題數量的增加,維持一致性變得越來越困難,最終導致邏輯矛盾。研究者形象地描述道,模型可能會先說某個物體比汽車大,後來又說它比足球小。
第三個實驗是最複雜的。研究者設計了一個基於著名的約瑟夫問題的“數學魔術”,要求模型在心中想象四個數字,然後執行一系列複雜的操作:複製、旋轉、移除等等。由於數學約束,最終剩下的兩個數字理論上應該相同。
這個任務需要模型在多個步驟中維持和操作內部狀態,是對工作記憶能力的終極測試。結果再次印證了研究者的假設:大多數模型在這個任務上表現極差,準確率通常只有 0-20%,僅略高於隨機猜測的基線(10%)。
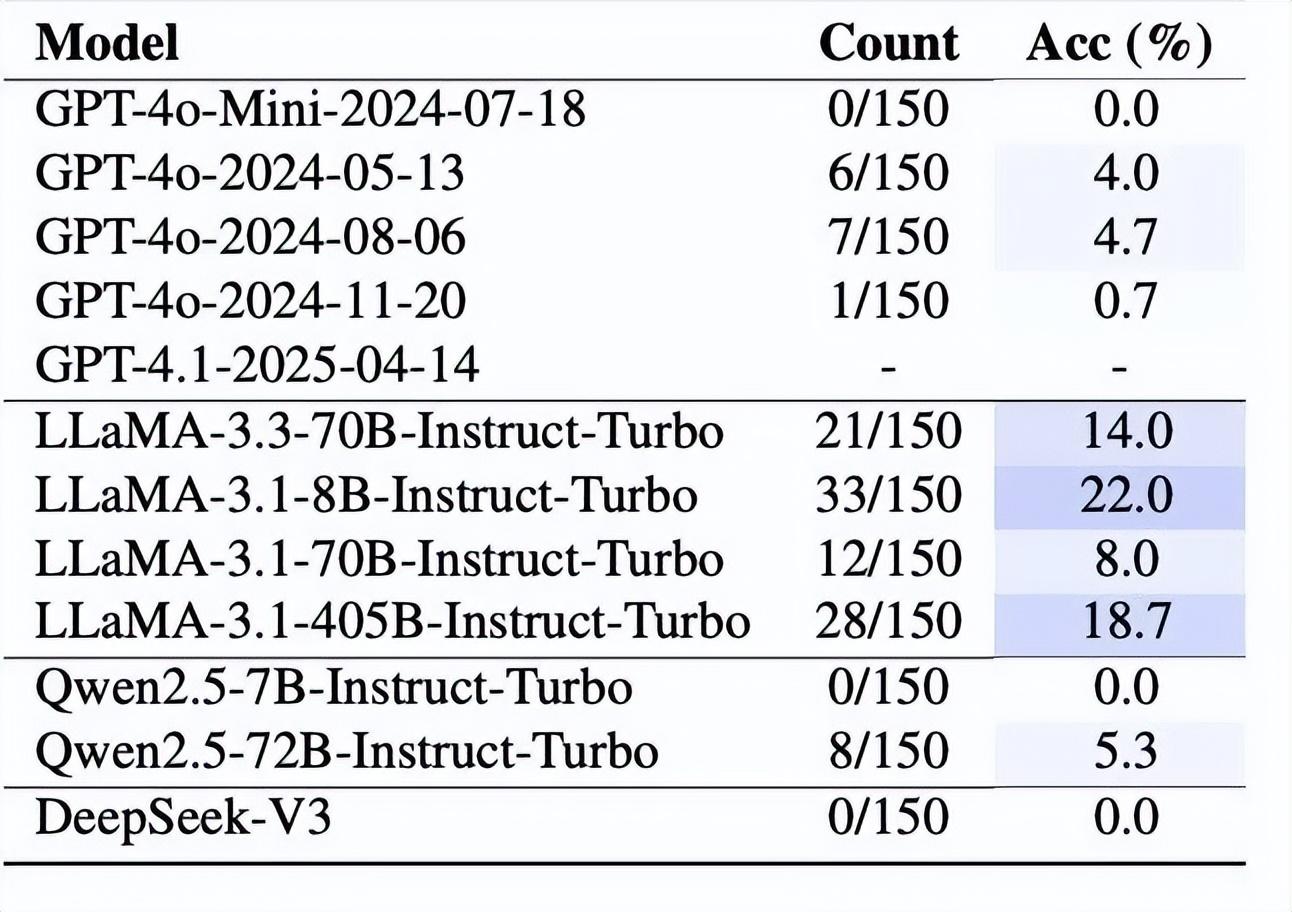
圖丨模型在“數學魔術”上的表現(來源:arXiv)
即使是配備了高級推理能力的模型,如 OpenAI 的 o1 系列,也只能達到 16.7% 的準確率。表現最好的是 DeepSeek-R1,達到了 39.3% 的準確率,但這仍然遠低於人類的表現水平。
有意思的是,研究者發現模型在這個任務中也表現出對數字 7 的偏好。在 DeepSeek-R1 的 59 次正確回答中,有 48 次(81.4%)涉及數字 7,這進一步表明模型可能並不是真正理解任務,而是依賴於訓練中形成的數字偏好。
研究者還測試了當前最流行的提升 AI 推理能力的方法——思維鏈(CoT,Chain-of-Thought)推理。這種方法要求模型逐步展示其思考過程,理論上應該能幫助模型更好地管理複雜任務。
然而,實驗結果顯示,即使使用 CoT 推理,模型在工作記憶相關任務上的表現也沒有顯著改善。在數學魔術實驗中,使用 CoT 的 GPT-4o 準確率從 4.7% 提升到 21.3%,雖有改善但仍然很低。這表明,簡單地要求模型“展示思考過程”並不能彌補其根本的認知侷限性。
儘管整體表現不佳,研究中還是發現了一些有趣的差異。Meta 的 LLaMA 系列模型在某些測試中表現相對較好,特別是在數字猜測遊戲中。LLaMA-3.1-8B 甚至超越了更大的 70B 和 405B 版本,這表明模型大小並不總是決定性因素。
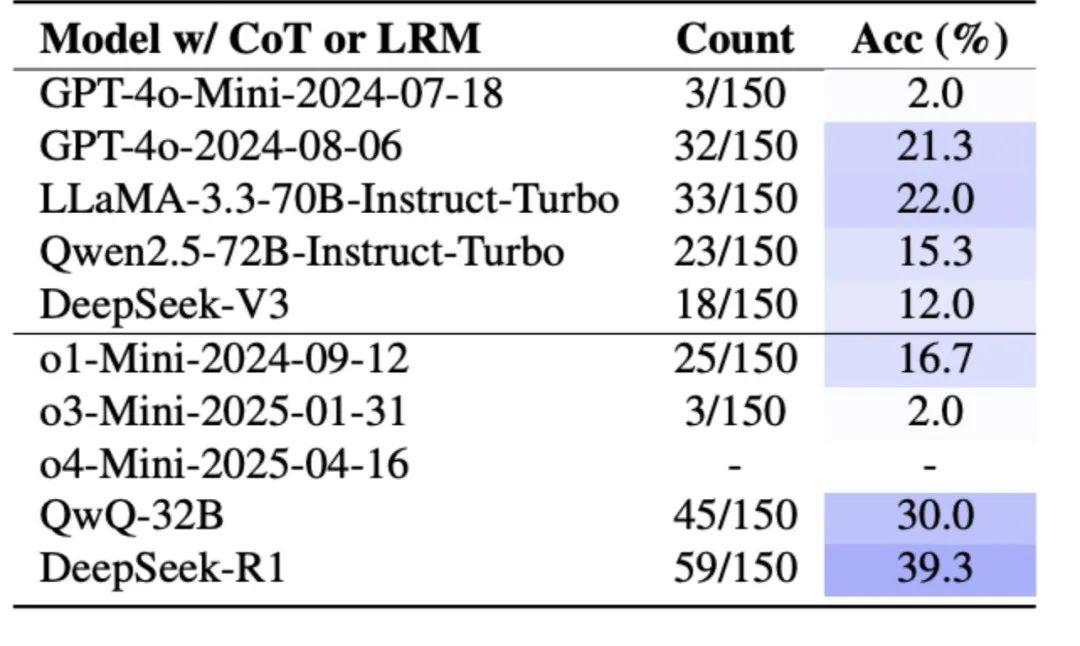
圖丨LLMs 在“數學魔術”上使用 CoT 或 LRM 的表現(來源:arXiv)
另一個令人意外的發現是,較新的模型版本並不一定比舊版本表現更好。在 GPT-4o 系列中,2024 年 8 月版本在數字猜測任務中表現最佳,超過了 11 月版本和最新的 GPT-4.1。這說明,在追求更強大的語言能力時,可能無意中削弱了其他認知功能。
綜合這三個實驗,該研究得出結論:當前的大型語言模型作爲一個類別,並不具備類人的工作記憶。它們在需要內部表徵和操縱瞬時信息的任務上,表現出系統性的失敗。它們的強大能力更多地體現在處理和生成基於顯式上下文的文本,而非進行內化的、主動的思考。
而這一發現或許也爲我們理解當前 LLM 的一些能力侷限提供了具體的證據。模型產生的邏輯矛盾、事實錯誤等問題,可能並只是因爲“幻覺”,而因爲其認知架構中缺少工作記憶這一核心組件的直接體現。因此,未來人工智能領域的發展,或許需要將研究重點從單純擴大模型規模,轉向探索能夠整合有效工作記憶機制的新型模型架構。
參考資料:
1.https://arxiv.org/pdf/2505.10571v1
運營/排版:何晨龍