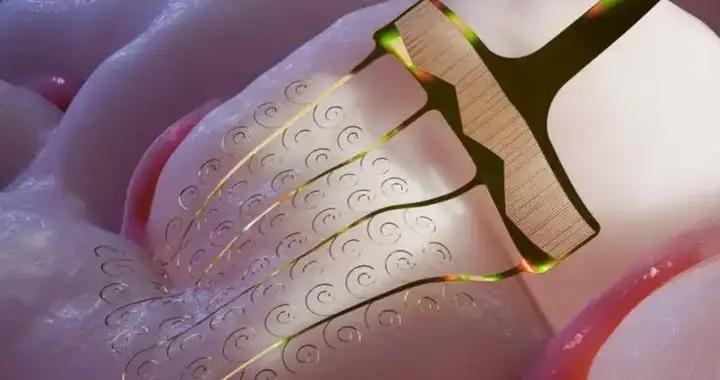
你是否想過,當人類面對面交流時,我們的注意力更多地被放在哪裏?
第一直覺或許是眼睛。它們是心靈的窗戶,能夠傳達出細微而生動的情感。科學研究也證實的確如此,在日常對話中,我們會頻繁地注視對方的眼睛來捕捉情緒信號。
不過,當環境變得嘈雜時,情況就有所不同了。研究表明,在噪音環境下,人們會將 50%-55% 的注意力轉向對話者的嘴脣,傾向於通過脣形來輔助理解對方在說什麼。
這也解釋了爲什麼即便是目前最先進的人形機器人,仍然讓人在和它們面對面交流時感到不適。我們可以容忍它們笨拙的步態,甚至僵硬的手勢,但當一張接近人類的面孔無法自然地活動時,就會生髮出一絲詭異感。這就是機器人領域著名的"恐怖谷效應"——越接近人類卻又不夠完美的機器,反而會引發更強烈的排斥感。
在致力機器人如何跨越“恐怖谷”效應的道路上,首形科技是積極的拓路者之一。這家由哥倫比亞大學博士胡宇航創立的初創公司,自成立起便選擇了一條與衆不同的技術路徑:不追求機器人在運動或操作能力上的極致性能,而是聚焦於賦予它們具有情緒表達能力的面部。過去一年多,這一方向爲他們贏得了多輪融資,並且收穫了社交媒體和市場的廣泛關注。

圖 | 胡宇航與人臉機器人 Emo (來源:受訪者)
1 月 15 日,Science Robotics 封面刊發了胡宇航團隊關於 Emo 面部機器人的研究,展示了其如何通過學習實現與語音、歌曲同步的脣部運動,這也是 Science Robotics 首次將人臉機器人刊登在封面。這項工作源於他在哥倫比亞大學的博士研究,也是他近兩年在 Science 和 Nature 子刊上發表的第三篇論文。

圖 | 胡宇航論文登上 Science Robotics 封面(來源:Science Robotics)
嘴脣運動被低估的複雜性
“嘴脣是人們交互過程中動作最多的部位, 也是機器人從表情自然到交互自然非常重要的門檻。”胡宇航告訴 DeepTech,嘴脣運動的複雜性遠超多數人的想象,甚至超出了機器人研究者此前的認知。
從技術角度看,這種複雜性首先體現在驅動機制上。與眉毛等單一方向運動的面部特徵不同,嘴脣由多個肌肉羣驅動,運動過程中存在頻繁的接觸與分離。同時,嘴脣對時間精度極爲敏感,還需同步承載語言、情感與社交信號。胡宇航指出:“這使得嘴脣運動的建模從根本上超越了參數化控制,成爲一個高維、非線性、強閉環的生成式形變問題。”

圖 | Emo 面部機器人的脣部發音動作及其對應的語音符號(來源:論文)
既然如此,面對如此複雜的任務,如何客觀衡量機器人嘴脣運動的“真實性”呢?
胡宇航團隊在論文中提出了一種創新方法:使用合成參考視頻作爲理想同步基準,在 VAE 編碼器的潛空間中計算機器人嘴脣運動與參考視頻之間的距離。該指標能夠刻畫整體嘴型動態與時序結構的偏差,避免了依賴易受噪聲干擾的二維關鍵點。由此,研究者獲得了一個客觀的度量標準,可以在連續語音與多語言場景下評估音頻-視覺同步誤差。
這可以說是創新的一步。因爲此前,機器人領域對嘴脣同步的嘗試主要依賴手工預定義的運動規則和固定的音素-視位映射表。簡單來說,就是爲每個音素設計一套固定嘴型,再讓機器人機械執行。
但這種方法存在明顯的侷限。胡宇航列舉了幾個關鍵問題:首先,同一音素的發聲速度會因說話人、場景或情緒而異。例如,一個人在激動和平靜狀態下說出的“好”,雖然音素相同,但嘴脣運動的幅度、速度和形態可能截然不同。其次,在多語言、歌唱或方言等場景中,基於音素設計規則需要投入巨大的手工工作量。更關鍵的是,當機器人硬件升級時,所有動作幾乎都要重新編排,難以複用。
此外,這種規則方法還隱含了一個假設:音素與嘴型之間存在着穩定、一對一的映射關係。但這顯然與真實人類發音機制並不相符。實際上,同一音素的嘴脣運動在不同說話人、語速、情緒和語境下都存在顯著差異,其時序、幅度和形態高度連續且上下文相關。
將這種連續性強行離散化爲固定規則,必然丟失大量信息。規則方法也無法建模嘴脣作爲軟體器官所具有的非線性、並行驅動和跨時間依賴特性,最終只能生成“正確但僵硬”的嘴型序列。
相比之下,數據驅動方法能夠從真實人類與機器人發音數據中學習複雜的統計規律與隱含約束。胡宇航表示:“這從根本上突破了規則方法在泛化性、可擴展性和自然性上的瓶頸。”
想要更像人,機器人需要“照鏡子”
爲了讓機器人更精準地復刻學習人類的嘴脣動作,胡宇航團隊巧妙地設計了兩階段“自監督學習系統”(Self-Supervised Learning, SSL):第一階段,機器人通過“照鏡子”建立自我模型;第二階段,它觀看人類視頻學習嘴脣運動規律。
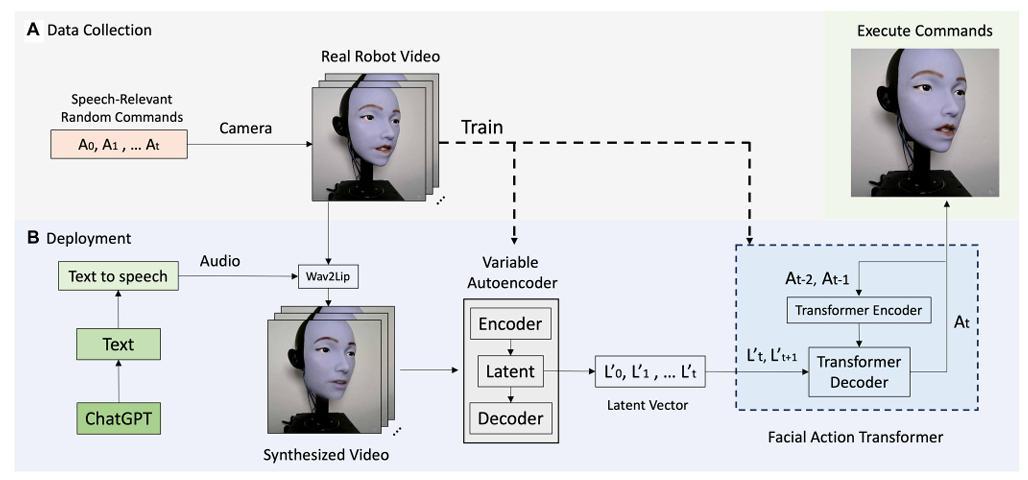
圖 | 用於機器人脣部同步的自監督學習框架(來源:論文)
“兩階段設計的核心原因在於機器人與人類在外觀、結構和運動約束上的本質差異。”胡宇航解釋道。若跳過第一階段,直接讓機器人模仿人類視頻,將不可避免地學習到大量自身硬件無法執行的形變模式,例如人類皮膚的滑移、脣齒細節或肌肉驅動方式。這些錯誤映射最終會導致機器人動作失真、抖動或被系統性削弱。
第一階段的“照鏡子”訓練,目的並非學習表情本身,而是讓模型明確“哪些運動在自身硬件與軟體結構下是可實現的”。通過隨機生成數千個面部表情並觀察鏡中反饋,系統建立起從視覺變化到自身可控空間的映射關係,爲後續學習提供物理可行性的約束。
在具備自我模型的基礎上,第二階段引入人類視頻的作用變得清晰:機器人學習人類嘴脣運動的統計規律與高層時序結構,並通過自我模型將這些規律投射到自身可執行的動作空間中。“這本質上是先解決‘我是誰、我能怎麼動’,再解決‘人類是如何動的’。”胡宇航說。該策略有效避免了跨形態直接模仿帶來的域錯配問題,是實現自然、穩定且可泛化嘴脣運動的關鍵前提。

圖 | 團隊機器人 Emo 照鏡子(來源:胡宇航)
出色的跨語言泛化能力
實驗結果展示了這套系統的出色泛化能力:它能在 11 種語言中實現自然的嘴脣同步,包括英語、法語、日語、韓語、西班牙語、意大利語、德語、俄語、中文、希伯來語和阿拉伯語。
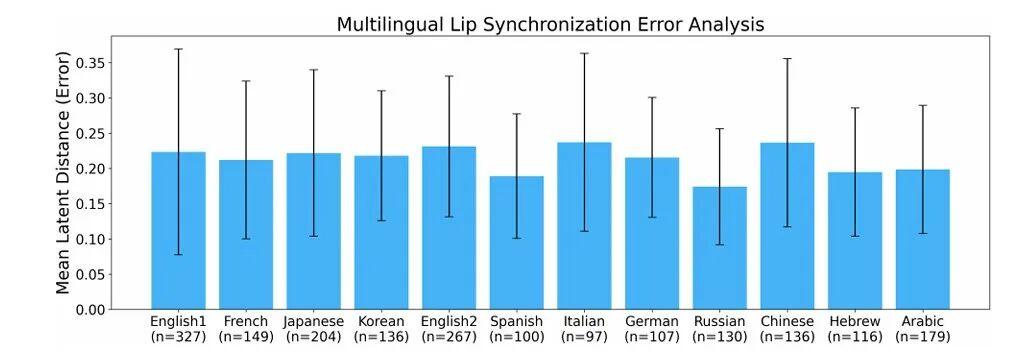
圖 | 多語言口型同步性能的測試結果(來源:論文)
這種神奇的"跨語言"能力從何而來?胡宇航解釋道:“系統並未學習語言或音素本身,而是學習了人類發音過程中更底層的肌肉運動模式。”在兩階段自監督框架下,模型首先熟悉機器人自身嘴脣能做出哪些動作;隨後在觀看人類視頻時,它不再關注具體是哪種語言、哪個發音,而是去捕捉聲音節奏與嘴脣動作之間那些跨越語言邊界的共性規律。
“這些關係在不同語言中表現爲高度一致的運動模式,比如張合節律、閉合-釋放結構、過渡速度等。”換句話說,雖然各種語言的發音規則千差萬別,但人類嘴脣的運動方式終究受限於相同的生理結構。正因如此,系統學到的是聲音與動作之間更本質的對應關係,使它能夠自然地適應多種語言,甚至應對不同的語速和說話風格。
儘管成果顯著,胡宇航坦言系統仍面臨技術挑戰,其中最典型的是硬輔音(如 /b/、/p/、/m/、/w/)的處理。這些音素之所以棘手,不僅因爲發音速度快,更因爲它們同時涉及多重難以精確建模的約束條件。
以 /b/、/p/、/m/ 爲例,發這幾個音時,嘴脣需要在極短時間內完成“閉合—保持—釋放”這一連串動作。閉合不夠緊或時機稍有偏差,人耳立刻就能察覺異樣。而 /w/ 更爲複雜,不僅要求雙脣閉攏,還需要嘴脣前突、形成圓形,同時配合口腔形狀的連續變化。胡宇航補充,這意味着模型必須在毫秒級時間精度下,協調多個高度耦合的自由度,同時應對軟體接觸、非線性阻尼以及電機帶寬限制等物理因素。
與元音或軟輔音那種平滑漸變的動作不同,硬輔音更像是一種"開關式"的動作——既有連續的運動軌跡,又有瞬間的接觸切換。這恰恰是當前數據驅動模型最容易出錯、機器人執行難度最高的地方。
從實驗結果來看,當前方法在一些極端語音場景下表現欠佳,比如語速極快、多人同時說話、歌唱中的顫音,以及情緒激動時的表達。胡宇航認爲,這反映了方法的本質邊界:"模型主要學習的是典型對話語境下聲學時序與嘴脣運動之間的關係。"一旦輸入偏離日常對話的範疇,系統性能便會下降。
不過他也指出,這些失效案例恰恰爲未來研究指明瞭方向:“這也爲我們引入更豐富的對話與語音場景提供了思路。”隨着訓練數據的豐富和模型能力的提升,這些邊界場景的處理能力有望逐步改善。
在採訪最後,DeepTech 問及這項技術是否會從脣部動作擴展到整個面部表情系統。
“會的。”胡宇航給出肯定回答,“我們團隊的最終目標,是實現完整的類人交互。”如何協調脣部動作與眼神、眉毛等其他面部要素,形成統一而細膩的情感表達,正是團隊下一步要攻克的方向。這不僅是技術上的自然延伸,更是對人機交互本質的深度探索。當機器人能夠用整張臉來表達和理解情緒時,它與人類的關係將發生更深刻的轉變。
參考鏈接:
論文地址:DOI:
10.1126/scirobotics.adx3017
營/排版:何晨龍