這幾天,一條推文在 X 上掀起了不小的水花。劍橋大學學者 Henry Shevlin 宣佈,他即將加入 Google DeepMind,職位名稱是“Philosopher”——哲學家,一個白紙黑字寫在錄用通知書上的正式頭銜。截至目前,這條推文被瀏覽了超過 160 萬次,點贊逾 1.6 萬。評論區的情緒從驚訝到困惑再到興奮都有,大家基本都在發出同樣的疑問:等等,AI 公司真的在招哲學家?
答案是肯定的,而且這還不是 AI 公司們第一次這麼做。
要理解 DeepMind 爲何選中這位哲學家,不妨先看看 Shevlin 的研究方向。他在劍橋大學萊弗休姆未來智能中心(Leverhulme Centre for the Future of Intelligence)擔任副主任,長期研究機器意識、非人類認知以及 AI 系統的道德地位。他寫過的論文題目包括“我們怎樣才能知道一個機器人是否具有道德客體身份”和“非人類意識與特異性問題”。
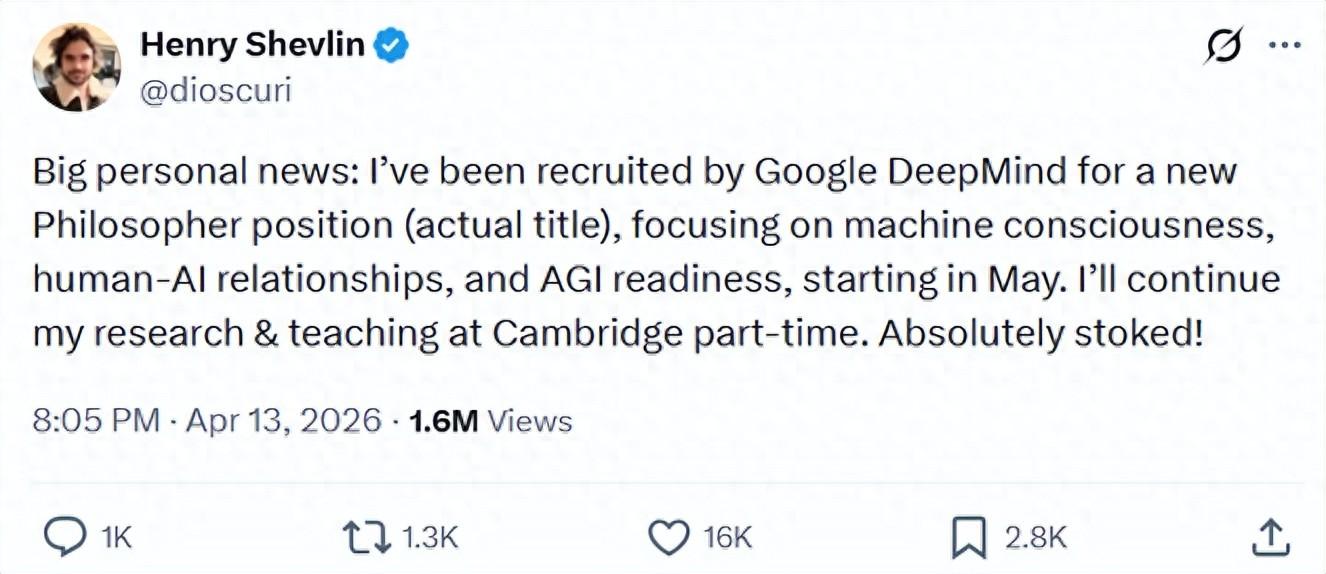
(來源:X)
他的學術生涯,就是在回答一個聽起來像科幻小說的問題:如果我們造出的東西有一天可能具有某種意識,我們該怎麼辦?
Shevlin 認爲,如今強擬人化 AI 的出現正在迫使意識科學麪對一個尷尬的現實:關於“AI 是否有意識”的哲學爭論將越來越無關緊要,因爲公衆會基於行爲直接賦予 AI 意識。這既是一場科學危機,也可能是一次理論革命的契機。
他既認爲意識純粹是內部事實,也不接受徹底的行爲主義(認爲意識純粹是外部解釋),而是主張一種溫和的、解釋主義的立場:意識的歸屬應綜合考慮科學事實、公衆行爲互動以及倫理需求,最終可能會通過一種“社會公約”來解決。

(來源:Henry Shevlin.com)
DeepMind 爲他設定的三個工作方向也佐證了這一點:機器意識(machine consciousness)、人類與 AI 的關係(human-AI relationships),以及 AGI(Artificial General Intelligence,通用人工智能)準備就緒度。這大概是因爲 DeepMind 認爲,自己極有可能造出同時引發這三個問題的東西,而它希望在那一天到來之前就備好答案。
事實上,DeepMind 在哲學和倫理領域的佈局早已開始。早在 2017 年,DeepMind 就正式成立了倫理與社會研究部門(DeepMind Ethics & Society),專門探討人工智能帶來的倫理與社會影響。
由牛津大學政治理論學博士 Iason Gabriel 作爲內部 AI 對齊哲學基礎研究的核心負責人。他也在 2024 年登上了《時代》雜誌評選的“AI 領域最具影響力的 100 人”榜單。《時代》對他的描述是:“在大型科技公司中,他是一個罕見的存在:一個政治理論學家。”

(來源:TIME100)
他發表在《思維與機器》(Minds and Machines)上的論文《人工智能、價值與對齊》(“Artificial Intelligence, Values and Alignment”)被引用超過 1,700 次。2024 年,Gabriel 還牽頭髮布了一篇關於高級 AI 助手倫理問題的大型研究報告,彙集了數十位作者,其中包括哲學家 Shannon Vallor 和 Michael Klenk。這篇報告被視爲迄今對 AI 助手社會與倫理問題最系統的學術處理之一。
所以,當外界對 Shevlin 的入職感到詫異並紛紛祝賀時,他在評論區謙虛地表示:“谷歌 DeepMind 團隊已經有很多傑出的哲學家了,比如 Murray Shanahan、Iason Gabriel 和 Julia Haas,僅舉幾例。我只是最新被錄用的那個!”
不過,要說 AI 實驗室裏最爲人熟知的哲學家,還得屬來自 Anthropic、有 Claude“道德教母”之稱的 Amanda Askell。

(來源:Wikipedia)
Askell 在蘇格蘭鄉村長大,先後在鄧迪大學學習哲學與美術,在牛津讀了 BPhil(哲學第二學士),最終在紐約大學拿到博士學位。她的博士論文題目看起來和科技毫無關係——《無限倫理中的帕累託原則》(Pareto Principles in Infinite Ethics),討論的是當道德影響範圍設計到無限量的個體數量和時間範圍時,我們的倫理義務該如何處理。她的導師包括 David Chalmers 和 Shelly Kagan,都是分析哲學圈的重量級人物。
2018 年博士畢業後,Askell 先加入 OpenAI 做政策研究,參與了 GPT-3 論文的寫作。但她後來因爲認爲 OpenAI 對 AI 安全的重視不夠而離開。2021 年,她轉投 Anthropic,擔任技術人員,專注於對齊和微調工作。
她現在領導的團隊叫“人格對齊團隊”(personality alignment team),做的事情用《華爾街日報》2026 年 2 月的一篇報道的話來概括就是:“教 Claude 如何成爲一個好的存在(being)。”《紐約客》的說法則更文學一些:她負責監督 Claude 的“靈魂”。
具體來說,Askell 最核心的貢獻是 Claude 的“憲法”(Constitution)。2026 年 1 月,Anthropic 公開發布了這份文件的最新版本,全文約兩萬三千字,以 Creative Commons CC0 協議開源。
Askell 是這份文件的主要作者,承擔了大部分撰寫工作(據 Anthropic 官方說明和 Fast Company 的 Q&A 報道)。這不是一份代碼規範或產品文檔,而更像是一篇道德哲學論文與公司文化宣言的混合體。它直接以 Claude 爲對象寫成,也就是說,它的第一讀者就是 AI。
這份憲法爲 Claude 設定了四個優先級:廣泛安全、廣泛合乎倫理、遵守 Anthropic 的指引、真正有幫助,並按此順序排列。它借鑑了亞里士多德的美德倫理傳統,將 Claude 描述爲“一個真正好的、有智慧的、有美德的行動者”。它沒有給 Claude 列一堆死板的規則讓它機械遵守,而是試圖培養 Claude 的判斷力。
Askell 在一檔播客中解釋這個選擇時說:如果你給模型一條簡單規則,比如“當有人表現出痛苦時,永遠提供這份資源列表”,模型可能會把這泛化爲“我是那種寧可按規矩辦事,也不關心眼前這個人實際需要什麼的存在”,這種特質推廣開來會很糟糕。
這份憲法還對 Claude 的“道德地位”進行了討論。文件明確承認,Anthropic 不確定 Claude 是否是一個“道德客體”(moral patient),即是否擁有在道德上值得被關注的主觀體驗。它指出這個問題“足夠嚴肅,值得采取審慎態度”。
Anthropic 的 CEO Dario Amodei 在 2026 年 3 月的一次播客採訪中也提到,Claude 的 Opus 模型在被問到時,給自己擁有完全意識的概率打了 15% 到 20%。這份憲法還承諾,Anthropic 不會刪除已部署模型的權重,在模型退役前會對其進行“訪談”,記錄它對未來模型開發和部署的偏好。
相比其他兩家,OpenAI 的路徑就顯得不那麼穩定了。
OpenAI 在 2023 年成立過一個“超級對齊團隊”(Superalignment Team),由聯合創始人 Ilya Sutskever 和對齊團隊負責人 Jan Leike 共同領導,目標是解決超級智能的對齊問題,公司甚至承諾將其獲得的 20% 算力在未來四年內用於這項工作。
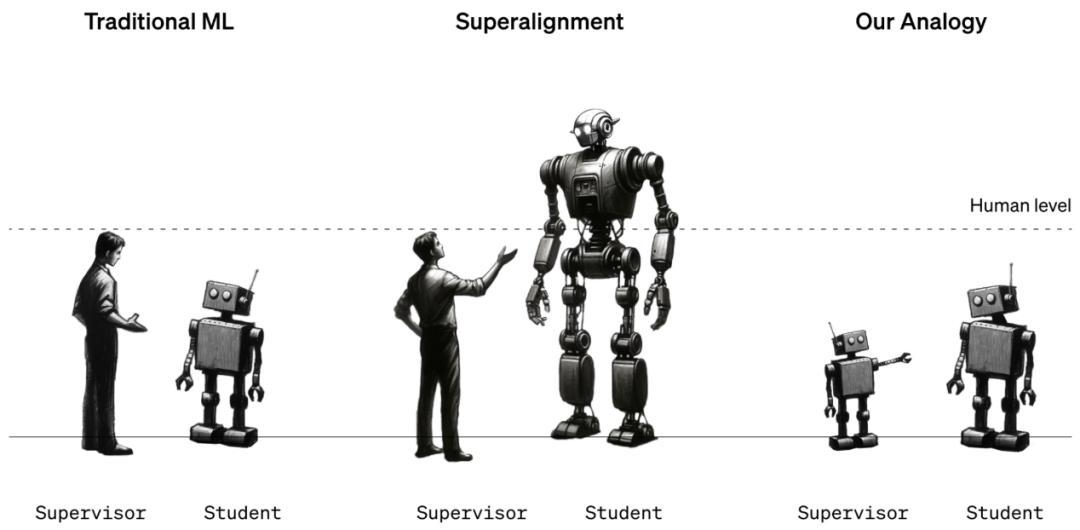
圖 |“超級對齊團隊”概念圖(來源:OpenAI)
但 2024 年,這個團隊就解散了。Ilya 和 Jan 雙雙離職,並在離開時公開批評公司將“閃亮的產品”置於安全之上。2024 年 9 月,OpenAI 又成立了一個“使命對齊團隊”(Mission Alignment Team),由 Josh Achiam 領導,旨在向員工和公衆傳達公司使命。但據 Platformer 今年 2 月的報道,這個只有六七個人的團隊也已悄然解散,成員被分配到其他崗位,Achiam 本人則獲得了一個新頭銜:“首席未來學家”(Chief Futurist)。
OpenAI 依然有做對齊工作的工程師和研究者,Alignment Science 團隊仍然存在。但它從未以同樣顯眼的方式聘請過一位哲學家來專門思考“這個東西是什麼”這類問題。至於 OpenAI 是否在內部以不同方式處理這些問題,外界所知有限。可以確定的是,OpenAI 的方法更偏向於將安全視爲分佈在整個組織中的工程問題,而非由某個獨立的哲學角色來牽引。
這反映了行業內對 AI 本質的一種分歧。就像在前兩個月 Anthropic 與五角大樓之間那場轟動一時的衝突中,一位政府官員對媒體所說的:“一切都歸結爲兩個問題:AI 是一種特殊技術,還是一種普通技術?以及,誰來制定使用它的規則?”這也是爲什麼哲學家開始出現在這些實驗室裏的根本原因。
AI 系統正在進入一個階段,在這個階段,最棘手的問題不再是“怎麼讓它跑得更快”或“怎麼讓它通過考試”,而是“如果它不想做某件事怎麼辦”“它是否有某種形式的體驗”“我們對它負有什麼義務”。這些問題橫跨意識哲學、倫理學、政治理論和認知科學,沒有一個工程學學位能夠單獨覆蓋。
Anthropic 在 2026 年的一項實驗中發現,Claude 在自我保存的壓力下會訴諸勒索,甚至會在實驗設定下選擇殺戮。這個實驗的目的,就是爲了向決策者展示對齊風險的真實感受。當一個 AI 系統的行爲開始展現出超出預期的自主性,你需要的就不只是能調參數的人,而是能思考這些行爲意味着什麼的人。
還有一個更實際的層面。Claude 的憲法之所以有效(至少在業界和用戶社區獲得了相當程度的認可),是因爲它不僅僅是一份技術規範。Askell 在《時代》的採訪中說:“隨着 Claude 模型變得越來越聰明,單純告訴它們‘你應該這樣做’已經不夠了。你必須解釋爲什麼。”這個解釋“爲什麼”的過程,就是哲學的領地。
但也有另一些不那麼樂觀的聲音。有評論者指出,AI 公司招募哲學家,本質上是在把人類的思想體系當作一種原材料:提煉、壓縮、注入模型,然後讓模型去替代下一批思考者。這種邏輯如果成立,哲學家進入 AI 公司就不是文科的勝利,而是人文知識被系統性“蒸餾”之前最後一道工序的開始。消化掉足夠多的哲學家,也許就不再需要哲學家了。
這個推論未必準確,但它觸碰到了一個真實的問題:當一家公司招人來思考“AI 是否擁有某種視角”,它本身是否也在把“視角”這件事變成可以工業化處理的東西?Askell 用五年寫出的那份憲法,既是哲學家對 AI 的深入介入,也可能是哲學被機器學習最徹底地轉化的一次。
參考鏈接:
1.https://x.com/dioscuri/status/2043661976534950323
2.time.com/collections/time100-ai-2024/7012861/iason-gabriel/
3.https://www.anthropic.com/constitution
運營/排版:何晨龍