當你在電商平臺下單購入一臺全新的空氣炸鍋,快遞到了,拆開包裝,你隨手把說明書扔在一邊,轉頭告訴家裏的服務機器人,“把那個紅薯放進空氣炸鍋裏烤一下。”
放在之前,機器人從未見過這款炸鍋,沒有對應的操作程序,最可能的結局就是系統報錯,任務失敗。想讓它學會用新電器,工程師必須重新收集演示數據、重新訓練模型,一個完整的流程將耗費數週乃至數月。
但現在,這個困局正在被打破。2026 年 4 月 16 日,總部位於美國舊金山的明星機器人 AI 公司 Physical Intelligence(簡稱 PI 或 π)發佈了其最新模型 π0.7。在一段令研發團隊成員都感到意外的演示視頻中,這個從未被明確訓練過“如何使用空氣炸鍋”的模型,僅憑一步步的語言指引,就引導機器人打開炸鍋蓋、放入食材、合上機器,順利完成這個它在訓練數據中幾乎沒有見過的任務。
PI 是誰?
PI 成立於 2024 年初,總部位於舊金山。公司核心創始團隊堪稱 “全明星陣容”:聯合創始人謝爾蓋·萊文(Sergey Levine)是加州大學伯克利分校(UC Berkeley)機器人學習方向的知名教授,專注研究機器人強化學習與模仿學習十餘年;切爾西·芬恩(Chelsea Finn)來自斯坦福大學,是元學習領域的頂尖學者;卡羅爾·豪斯曼(Karol Hausman)與布萊恩·伊希特(Brian Ichter)均來自 Google DeepMind,在大型機器人模型方向積累了深厚的工業界經驗。

圖 | Sergey Levine(來源:UC Berkeley)
謝爾蓋曾對外簡潔地描述公司的目標:PI 的使命就是“把 ChatGPT 搬進機器人裏”,開發能夠控制任意機器人、完成任意任務的通用基礎模型。這個定位決定了 PI 的商業邏輯:不造硬件,專爲機器人提供“大腦”。PI 的模型可以授權給各家機器人廠商,成爲整個行業的底層智能引擎。
資本市場對這一邏輯給出了極爲積極的回應。2024 年 3 月完成 7,000 萬美元種子輪融資後,PI 在兩年內又相繼完成 4 億美元 A 輪融資和 6 億美元 B 輪融資,估值來到 56 億美元,成爲全球具身智能賽道估值最高的純模型公司之一。而最近的 2026 年 3 月,有消息傳出,PI 正洽談新一輪約 10 億美元融資,估值有望超過 110 億美元,較四個月前幾乎翻番。
π0 家族演進史:從開源原型到通用大腦
讓我們把時間線拉回 2024 年 10 月,彼時發佈的 π0 是 PI 的開山之作。這是一個約 30 億參數的視覺-語言-動作(VLA)模型,基座模型是谷歌的預訓練視覺-語言模型 PaliGemma,並在來自7種不同機器人平臺、68 項任務的數據上進行訓練。
π0 採用了一種稱爲“流匹配”的動作生成方式,能以 50Hz 的頻率實時生成平滑的運動軌跡,具備基本的跨機器人泛化能力。2025 年 2 月,PI 將 π0 的代碼與權重完全開源,迅速成爲機器人基礎模型社區的重要參考基線。
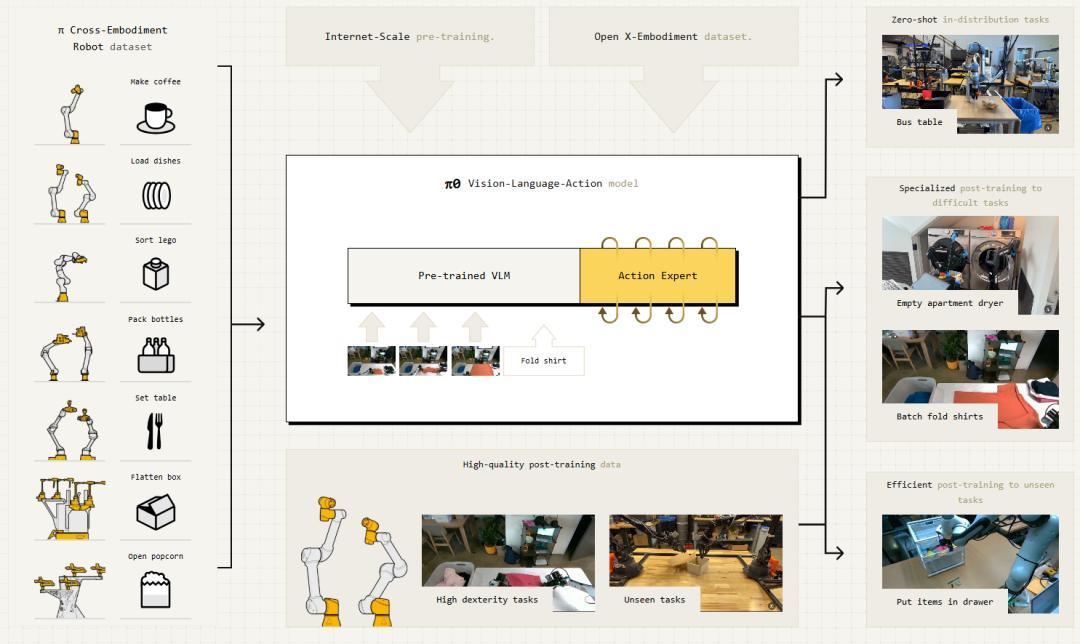
圖 | π0 的訓練框架(來源:Physical Intelligence)
2025 年 11 月發佈的 π0-FAST 則在 π0 的基礎上引入"快速動作空間分詞器"(FAST),這代模型改善了語言指令的跟隨能力,但推理計算成本也隨之提升約 4~5 倍。在幾乎同期亮相的 π0.6 中,PI 爲之引入了一套名爲 RECAP(基於優勢條件策略的經驗與糾錯強化學習)的算法,將專項任務的吞吐量翻倍,同時大幅降低了長時間運行的失敗率。但 π0.6 的本質仍是“專家模型”,每個任務需要單獨訓練,單獨優化。
直到 π0.7 問世,才成爲這個故事最關鍵的轉折點。作爲一系列迭代模型中最新、能力最強的一代,PI 不再追求“爲每項任務訓練最佳專家”,而是試圖用一個單一通用模型,在不進行任何任務特定微調的情況下,直接匹配甚至超越所有專家模型的表現,同時還展現出此前機器人模型從未真正實現的組合泛化能力。
全新的多模態提示框架與罕見的組合泛化能力
舉一個經典例子,如果一個大語言模型既能將英文翻譯成法文,也能將輸出格式化爲 JSON,它就能自然地完成"將英文翻譯成法文並以 JSON 格式輸出"這個新任務,儘管它可能從未見過這種組合的訓練樣本。這種將已有技能重新排列組合、解決新問題的能力,就是組合泛化。
在機器人領域,這種能力一直是一個理想化卻難以實現的願景。現有的 VLA 模型雖然能理解多樣的語義概念,但在實際執行層面的表現基本停留在“模式記憶”階段:見過的任務能做,沒見過的就不行。想要完成新任務,必須重新收集數據、重新訓練或微調專項模型。
π0.7 的出現,爲機器人模型突破泛化限制帶來了一絲曙光。而其實現組合泛化的核心技術路徑,是一套全新的多模態提示框架。
在舊的訓練策略中,給機器人的指令往往只有一個維度:做什麼(語言描述任務目標)。但 π0.7 的訓練將指令擴展成了一個多維度的上下文包,其中既有描述任務目標及子步驟的語言指令、描述如何執行任務的具體參數和控制模態標籤,也包括一個內置輕量級視覺模型自動生成的視覺子目標圖像。
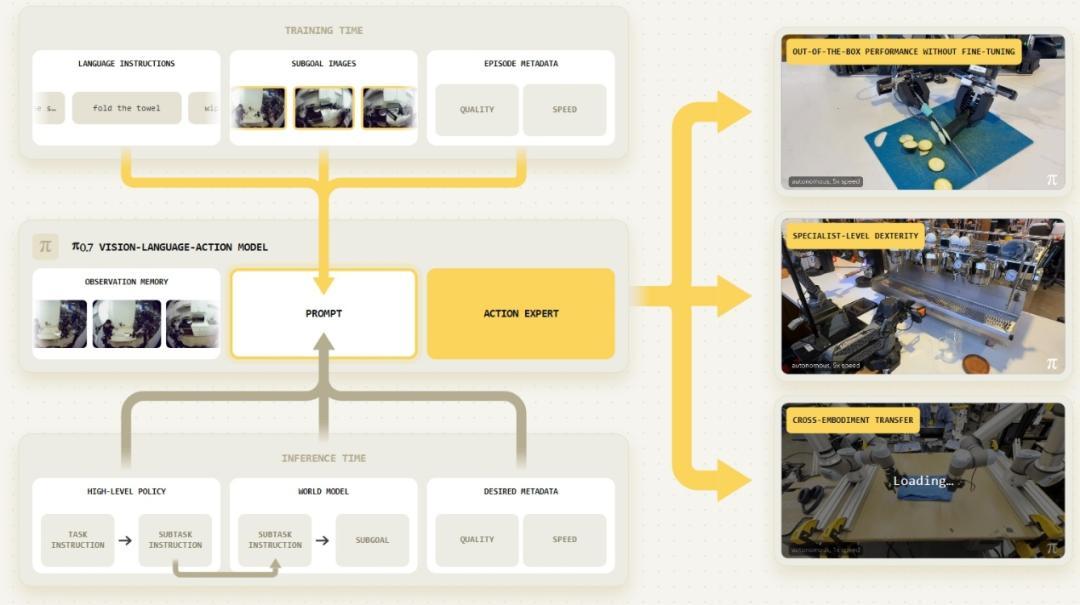
圖|π0.7 的多模態提示框架(來源:Physical Intelligence)
這套多模態提示框架解決了一個之前被低估的核心問題:數據多樣性與質量的矛盾。在以往的訓練中,不同來源的數據往往無法混用,因爲它們的執行風格、速度、質量參差不齊,混合訓練反而會讓模型學到僅僅達到“平均水平”的劣質策略,執行效果也差強人意。
π0.7 的解決方案是爲每條訓練數據添加顯式的元數據標註,低質量的自動採集數據被標註爲“低質量/低速度”,優質的人類演示被標註爲“高質量/高速度”。模型在訓練時學會了根據指令要求,選擇對應風格的行爲。推理時,只需在 Prompt 中指定“高質量、快速執行”,模型就會調用與該標籤對應的最佳行爲模式。
這一設計使 π0.7 能夠將過去無法有效利用的數據全部納入訓練,包括質量較低的自動數據、來自不同機器人平臺的數據,甚至人類操作視頻等,大幅擴展了有效訓練數據的規模與多樣性。
從系統層面看,π0.7 使用了用 Gemma3 4B 作爲基座模型,推理流程可以分爲幾個環節:在感知層,機器人的 RGB-D 攝像頭持續流式傳輸圖像,與機器人當前的運動歷史一同輸入系統。接着,系統將二者輸入一個 50 億參數量級的 Transformer 模型,結合語言指令與視覺子目標圖像進行綜合理解。
隨後,高層策略模型根據任務指令,自動分解並生成語言子目標序列,選擇性地調用世界模型生成對應的視覺子目標圖像。行動專家模塊則在約 100 毫秒內預測未來 50 步的動作序列,通過硬件抽象層將數據轉換爲各機器人平臺專用的關節指令,同時在力度和速度範圍內實施安全約束。整套系統可自動適配或靈活切換多種控制模式,如關節控制、末端執行器控制等,無需重新訓練。
僅需動動嘴,模型就能自己學會控制新機器、完成新任務
在 PI 公佈的論文中,研究人員展示了三個實用案例。其中最令人印象深刻、也最具想象空間的實驗就是用自然語言教會機器人使用空氣炸鍋。
PI 的研究人員首先用一個直接指令測試模型,零樣本地讓機器人把紅薯放進空氣炸鍋。結果是機器人做了若干次錯誤嘗試,終究未能順利完成任務,按照現有模型的水平,屬於意料之中。
隨後,研究人員換了一個策略:對機器人進行逐步的語言引導,就像你教一個第一次用這個電器的朋友:先告訴它打開抽屜,再告訴它放入食材,再告訴它關上,以此類推。在語言一步步引導下,機器人成功完成了這個它從未被專門訓練過的任務。
最後一步更爲關鍵。當研究人員用這種語言引導的方式多次走完流程之後,他們用這些語言指令序列微調了一個高層策略模型,該模型能夠自動生成完成任務所需的語言子目標序列。此後,機器人無需人工逐步引導,可以完全自主地完成空氣炸鍋任務。換言之,模型從“被語言引導着做事”,進化到了“用語言引導自己做事”。
研究人員專門追溯了訓練數據來源,結果只找到兩條和空氣炸鍋高度相關的片段:機器人關閉空氣炸鍋抽屜的操作,以及開源數據集中一個同款機械臂放置塑料瓶的片段。這些片段的操作場景與真正完成任務時的運動軌跡差異很大,但模型仍然將其內化,併成功遷移到了新任務上。
第二個實驗展示的是 π0.7 的跨機器人本體遷移能力。
PI 使用了名爲 UR5e 雙臂系統的機器人平臺,這種機器人操作起來極爲困難:兩條粗重的機械臂慣性大、夾爪精度低。在 PI 的訓練數據中,幾乎沒有其執行疊衣服任務的記錄。
但當研究人員用另一套靜態雙手機器人收集數據並餵給 π0.7,命令它自主控制這臺 UR5e 疊衣服時,它也順利完成了。兩臺機器人在體型、姿態和結構上差異巨大,π0.7 在 UR5e 上採用了與原始訓練機器人完全不同的運動策略,這意味着它能夠實現真正意義上的技能遷移與適應。

(來源:Physical Intelligence)
量化驗證顯示,π0.7 在 UR5e 上疊衣服的成功率,與已在原始機器人上積累了平均 375 小時遠程操作經驗的專業人員、首次切換到 UR5e 時的“零樣本”成功率相當。
第三個結果或許是最能改變行業預期的。此前,PI 的 π0.6 版本通過專項強化學習,在疊衣服、製作咖啡、組裝紙箱等特定任務上分別訓練了專門的“專家模型”。爲每個任務分配一個專家,是當時取得最佳性能的最優策略。
π0.7 用一個單一通用模型,在這些任務上直接與這些專家進行了對比。結果是:π0.7 在成功率上與所有專家模型持平,在某些任務的吞吐量上甚至超過了專家模型。除了以上這些意在精確評估模型某項能力的具體控制實驗,π0.7 在削黃瓜皮、做花生醬三明治、擦玻璃等靈巧任務上也表現出色,我們離全能家務機器人又近了一步。
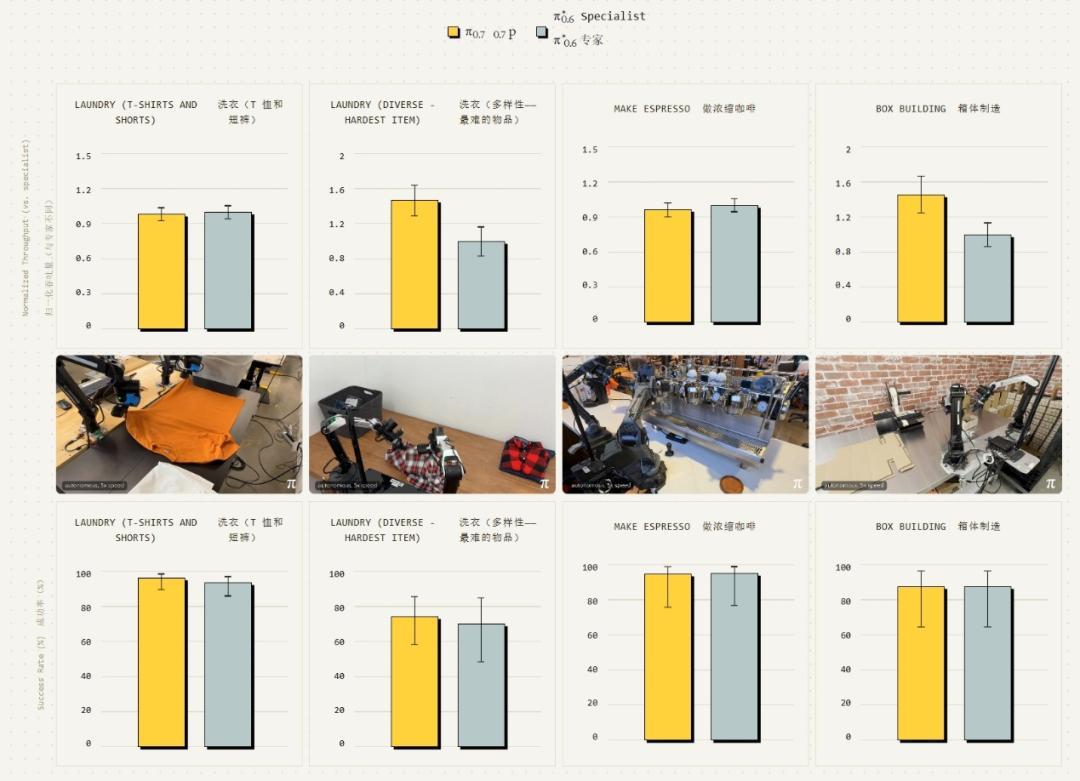
圖 | π0.7 與 π0.6 在不同任務上的表現相當。(來源:Physical Intelligence)
PI 的研究科學家阿什溫·巴拉克裏希納(Ashwin Balakrishna)感慨道,π0.7 能做到的已經遠超預期:“此前我只要深入瞭解訓練數據的內容,就能猜到模型能力的邊界,但 π0.7 顛覆了這一切,隨便買一個齒輪組,問它能轉動這個齒輪嗎,它都能做到。”
具身智能的“GPT 時刻”,還有多遠?
早期的大型語言模型需要針對每個具體的下游任務進行大量微調,才能取得最佳性能,直到 GPT 系列模型的出現改變了這一範式:通過足夠大規模、足夠多樣的預訓練,模型可以在不針對特定任務微調的情況下直接完成多種語言任務,並展現出組合泛化在內的湧現能力。
機器人領域如今正處在一個類似的早期階段,即需要針對每項任務訓練對應的專家模型。但 PI 的聯合創始人給出了判斷:一旦機器人模型越過組合泛化的能力門檻,其能力的增長速度就將不再與數據量線性相關,而會呈現超線性增長。
難道,拐點已至?PI 的研究人員在論文全篇中使用了非常審慎的措辭,他們坦承,π0.7 展示的是組合泛化的“初步跡象”,模型目前還無法響應類似“給我烤片面包”等高層級模糊指令,仍需人類將其分解爲具體步驟。同時,提示工程的質量對結果影響巨大,一次糟糕的引導就可能導致成功率從 95% 暴跌至 5%。
謝爾蓋曾拒絕給出機器人模型真正落地的預期時間表,只表示,“進展比我兩年前預期的要快”。現在看來,這句話或許是最值得行業認真對待的一句話:π0.7 展示的是方向,而非終點。未來,機器人的“可用性”可能只需要一個足夠通用的模型,和足夠清晰的語言表達。
參考內容:
https://www.pi.website/blog/pi07
運營/排版:何晨龍