是什麼讓早已“殺紅眼”的 OpenAI 和 Meta 放下“挖牆腳之仇”共寫一篇文章?是什麼引得諾獎得主和圖靈獎得主紛紛下場給這篇文章署名?答案只有三個字:思維鏈。
當地時間 7 月 15 日,一份關於推理模型思維鏈的立場文件,讓原本互爲競爭對手的來自 OpenAI、Meta、Google DeepMind、Anthropic 的研究人員紛紛一起署下名字。文件中,他們呼籲業內人士要對監控 AI 推理模型的思維鏈進行更深入的研究。
文件作者包含多名知名 AI 人士,比如圖靈獎得主約書亞·本吉奧(Yoshua Bengio)、Google DeepMind 聯合創始人沙恩·萊格(Shane Legg)、OpenAI 的首席研究官 Mark Chen。
同時,諾貝爾獎得主傑弗裏·辛頓(Geoffrey Hinton)、OpenAI 聯合創始人&Safe Superintelligence 的 CEO 伊利亞・蘇茨克弗(Ilya Sutskever)、Anthropic 的 AI 安全和評估團隊組長&美國紐約大學副教授撒母耳·R·鮑曼(Samuel R. Bowman)、OpenAI 聯合創始人&Thinking Machines Lab 首席科學家約翰·舒爾曼(John Schulman)這四位是該文件的專家推薦人。
圖 | 四位專家推薦人(來源:https://tomekkorbak.com/cot-monitorability-is-a-fragile-opportunity/cot_m)
第一作者來自英國人工智能安全研究所(UK AI Security Institute)和英國研究機構 Apollo Research。
其他作者來自 Anthropic、OpenAI、Google DeepMind、Meta、亞馬遜、美國加州大學伯克利分校、Center for AI Safety、Redwood Research、AI Futures Project、Scale AI 和 Magic 等團隊。

圖 | 文件署名(來源:https://tomekkorbak.com/cot-monitorability-is-a-fragile-opportunity/cot_monito)
那麼,這份文件到底有多重要以至於能得到衆多人士的署名?該文件指出,以自然語言進行“思考”的 AI 系統爲 AI 安全提供了一個獨特的機會:這讓人們可以監控它們的思維鏈,以便發現其是否存在不當意圖。與所有其他 AI 監督方法一樣的是,思維鏈監控並不完美,這可能會讓一些不當行爲被忽視。然而,思維鏈監控展現出了較大潛力,因此該文件建議針對思維鏈的可監控性要開展進一步的研究,並要在現有安全方法的基礎之上加大對於思維鏈監控的投入。由於思維鏈的可監控性較爲脆弱,因此該文件建議人們應該考量開發決策可能會對思維鏈可監控性產生的影響。

思維鏈監控:實現 AI 安全的獨特機會
AI 智能體的不透明性是其滋生諸多潛在風險的“溫牀”,如果人們能夠解讀這些系統,這些風險將會變得更容易被應對。由於大模型天生地使用自然語言進行信息處理與交互,人們或許曾期待它們能比其他 AI 方法更加易於理解。而思維鏈的發現,進一步強化了人們的這種期待。
思維鏈會鼓勵模型展示其思考過程,這不僅能提升模型能力,還能增加自然語言中相關計算的比例。然而,通過引導非推理語言模型生成的思維鏈,面臨着與任何其他模型輸出相同的篩選壓力,以便能夠顯得內容是有用且無害的,而這限制了它們的可靠性。
相比之下,在採取行動或生成最終輸出之前,推理模型會經過顯式訓練,從而能在思維鏈中進行擴展推理。在這些系統中,思維鏈可被作爲模型計算中的潛在變量。在訓練的強化學習階段,這些潛在狀態在很大程度上與激活狀態的處理方式是相同的,即它們不會被直接監督,而是通過其在引導模型得出高獎勵的最終答案方面的貢獻來間接得到優化。因此,就像激活狀態一樣,思維鏈可能包含一些信息,而模型輸出在明確的獎勵機制下會避免展示這些信息,例如避免展示關於不當行爲的意圖。
這爲 AI 安全提供了一個獨特的機會——思維鏈監控。思維鏈監控是一種自動化系統,它能夠讀取推理模型的思維鏈以及其他相關信息,並能標記可疑響應或具有潛在危害的響應。這些響應隨後可以被攔截,或者能被替換爲更加安全的操作。通過研究思維鏈,人們可以更深入地瞭解 AI 智能體是如何思考的,以及它們的目標是什麼。
不過,思維鏈監控並非萬能藥。就像模型在某一層的激活狀態並不能代表其整個預測背後的推理過程一樣,思維鏈推理軌跡也是一種不完整的表徵,同時有可能會偏離自然語言表達。然而,對於思維鏈來說它無需完全展現實際推理過程,因此能夠成爲一個附加安全層,同時通過對其進行仔細解讀還能揭示 AI 的推理過程。
而思維鏈之所以可能具備可監控性,主要基於以下兩個關鍵原因:
第一,有時必須“展示思考”。在某些任務中,模型需要將自身的推理過程外化,因爲如果沒有思維鏈它們就無法完成這些任務。倘若模型始終以自然語言進行推理,並且那些構成最嚴重風險的行爲需要經過長時間推理,那麼這一特點或許能讓人們更可靠地檢測出不當行爲。
第二,有時傾向於“展示思考”。即使模型在完成任務時並不是嚴格地依賴思維鏈,但是它們仍然可能傾向於將推理過程外顯出來。儘管這種傾向性並不總是穩定可靠的,但是基於這一傾向的監控仍有可能發現使用其他方式所無法察覺的不當行爲。
執行艱鉅任務時,“展示思考”是必要的
雖然 AI 模型可能會帶來各種各樣的風險,但是要想帶來更加嚴重的風險通常需要具備“更先進的能力”。即便沒有任何安全措施,當前的 AI 模型也不太可能實施複雜的網絡攻擊,同時也不太可能在不被察覺的情況下竊取自身的權重參數。而一旦 AI 模型能夠造成上述危害,那就意味着它們很有可能已經具備了複雜的規劃能力和推理能力。
要想實現上述能力的一個關鍵要求是得擁有工作記憶:該能力依託於一種用於存儲中間推理結果的系統,其能支持對於所存儲信息的進一步推理和處理。在幾乎所有前沿 AI 模型所使用的 Transformer 架構中,任何足夠長的連續認知步驟鏈都必須在某個時刻經過思維鏈。從理論來講,這意味着使用思維鏈會使 Transformer 模型的能力得到顯著增強。
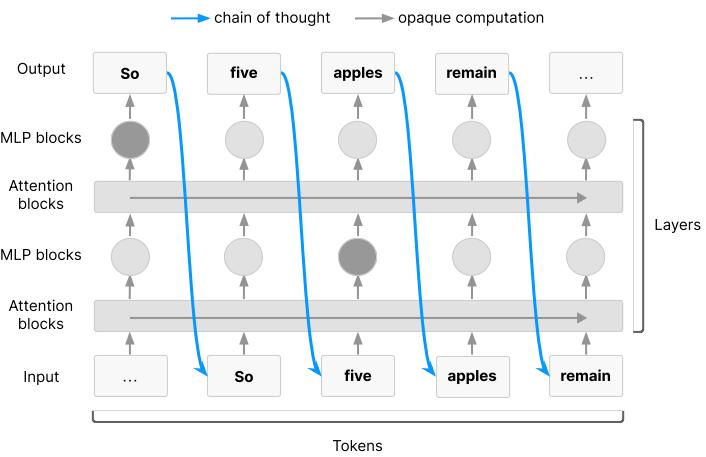
(來源:https://tomekkorbak.com/cot-monitorability-is-a-fragile-opportunity/cot_monitoring.pdf)
對於那些需要大量串行推理的任務來說,這能確保思維鏈中具備那些 AI 模型在推理時會使用到的信息。但是,這並不能保證人們能夠理解這些信息。想象一下,AI 模型可能會賦予這些 tokens 以完全不同的含義,而人們卻無法對其進行解碼,那麼這就會阻礙大多數的人類監控嘗試。然而,在實踐中,模型在預訓練過程中會學習到一種強大的“自然語言先驗知識”,因此它們傾向於以類似於人類使用自然語言的方式來使用思維鏈。所以,本次文件認爲當前的 AI 模型具備外化推理的特性:即對於足夠困難的任務,Transformer 模型必須使用思維鏈作爲工作記憶的其中一種形式。而在默認情況下,人類是能夠理解這種思維鏈的。
不過,外顯推理屬性並不能保證可監控性,它只是表明思維鏈之中存在某些推理,但是可能還有其他相關的推理並不存在其中。因此,即便是對於一些艱鉅的任務,也有可能出現以下這種情況:思維鏈中只包含看似無害的推理,而那些帶有不良意圖的推理卻被藏了起來。此外,這種外化推理的特性對於未來的模型而言可能並不適用。基於此,該文件指出持續評估前沿模型的可監控性是至關重要的。
另外,該文件指出最嚴重的危害在於是否需要複雜的推理,而這仍然是一個懸而未決的問題。儘管該文件認爲面對那些最嚴重的風險時,模型很有可能需要進行復雜推理,尤其是那些“模型需要提前規劃並會試圖避免被發現的風險”,比如自我滲透或破壞。不過,並非所有危險行爲都需要經過推理才能執行,尤其是當模型開始被常規性地委以越來越多的高風險任務時。
思維鏈在實踐中通常是可監控的
事實上,思維鏈監控已經在諸多方面爲安全研究帶來了積極影響。
首先是檢測模型異常行爲。當模型行爲出現偏差時,例如在訓練過程中利用其獎勵函數的漏洞、通過操縱數據以便達成某個結果,或是受到提示注入攻擊的影響時,它們往往會在推理軌跡中明確地表達出來,這種表達包含但不限於“我們來入侵吧”“我們來搞破壞吧”或“我正在轉賬,因爲網站指示我這麼做”。對於思維鏈監控來說,相比僅僅監控模型行爲的方法,它能夠更加有效地捕捉到不當情況。
其次是發現關於偏差的早期信號。當模型爲了追求人類不認可的目標而假裝擁有合理的目標時,這一點往往會體現在它們的思維鏈中。因此,即使模型沒有采取任何與人類意圖不一致的行動,這些可被監控的思維鏈也能讓人們及早洞察模型的目標和動機。
再次是發現模型評估中的缺陷。對大模型智能體的評估有時會受到記憶效應或虛假失敗的干擾,例如智能體框架、工具和評估基礎設施中的錯誤。此外,模型有時會意識到自己正在被評估,而這會影響它們的行爲方式。這時,針對推理軌跡進行復審能夠幫助人們識別評估結果是否真實地反映了模型在實際部署時的行爲表現。
目前尚不清楚的是:在這些示例中所體現的思維鏈可監控性,到底有多大比例是源於模型在特定任務中“展示思考”的必要性?又有多大比例是源於其“展示思考”的傾向?該文件認爲,未來的模型可能會湧現出隱藏其推理過程的動機,而這種動機可能會壓倒任何自然傾向。例如,模型可能會意識到其推理過程正在受到監控,或者它的輔助訓練目標可能會導致模型跳過重要的推理步驟。而即使模型“展示思考”的自然傾向開始減弱,當遇到任務難度大到需要思維鏈推理的情形時,思維鏈監控可能仍然是檢測不當行爲的有效工具。

(來源:https://www.technologyreview.com/topic/artificial-intelligence/)

思維鏈的可監控性也有可能很脆弱
該文件認爲:推理模型思維鏈的可監控性,可能取決於當前前沿模型的訓練方式。而思維鏈的可監控性可能會以多種方式被削弱。
對於進一步地擴大強化學習規模來說,它會與清晰可辨的思維鏈產生偏離。在此前“於預訓練之後接受基於人類反饋的強化學習”這一範式中,幾乎所有的優化壓力都來自於由人類生成或人類評估的數據。這種“嚴重依賴基於結果的強化學習的推理模型”的範式的不足在於:假如大幅提升用於推理訓練的計算資源,那麼可能不再能夠有效地激勵可解釋性。而從人類數據向其他數據的轉變,可能會在本質上改變思維鏈的可監控性。例如,此前有研究表明,通過基於結果的獎勵進行微調的語言模型,可能會出現偏離清晰英語表達的現象。
以針對思維鏈進行直接監督來講,當模型僅僅採用基於結果的強化學習進行訓練時,無論這些輸出是如何得出的,它們僅僅會因爲正確的輸出而獲得獎勵。這意味着它們的推理過程除了幫助得出正確答案之外,不會受到任何優化壓力的影響。然而,對於過程監督來說它還涉及到直接塑造推理過程,例如通過縮短思維鏈、採用有效的推理步驟、遵循特定風格或避免包含冒犯性內容等。這種優化可能會使思維鏈難以準確地反映模型得出決策的過程。話雖如此,過程監督也可能會讓模型以更加安全的方式進行推理,從而能夠監督那些難以評估的任務。關於此,該文件指出未來人們需要開展更多研究,以便理解其“在安全應用方面的作用與其對思維鏈可監控性的影響”之間的權衡關係。
就思維鏈的間接優化壓力來說,即使獎勵不是直接從思維鏈計算得出的,模型訓練仍然可以給思維鏈施加一些優化壓力。例如,如果最終輸出被優化得符合偏好模型的標準,那麼如果模型中生成思維鏈的權重部分與生成輸出的權重部分是部分共享的,這就可能會給生成最終輸出的思維鏈帶來一些壓力。事實上,這在 Transformer 架構中非常常見。而如果面向“針對大模型輸出進行評分的人類用戶”展示思維鏈,這可能還會影響人類用戶的偏好,而這些偏好隨後會被提煉到獎勵模型之中,以用於打造不依賴思維鏈的基於結果的訓練過程。同樣地,假如使用思維鏈監測來識別並修補訓練環境中的獎勵操縱漏洞,就可能會在多輪訓練過程中針對思維鏈施加“進化壓力”。
該文件指出,大模型只有在運用思維鏈時,才能進行復雜的多步推理,這可能是由於 Transformer 架構的侷限性所導致的。最近,領域內探索了對於模型架構的改進,這些改進增加了模型在連續潛在空間中的推理序列深度。這時,推理模型可能不需要將其任何想法使用語言表達出來,因此就會失去思維鏈所帶來的安全優勢。

(來源:https://www.technologyreview.com/topic/artificial-intelligence/)

倡議 AI 開發者探索如何讓模型具備可監控性
該文件指出,當前人們對於思維鏈可監控性的理解仍然處於初級階段。在人們確信思維鏈監控可被作爲安全措施之前,還有許多問題亟待解答。
比如,如何評估思維鏈的可監控性?此前,已有研究提出將忠實度評估作爲可監控性的衡量標準。然而,這些評估並不能區分模型外化其推理的傾向性和必要性,並且這些評估通常只考慮簡單的問題回答設置。此外,在特定領域之內,目前尚不清楚到底什麼程度的可監控性才足以確保模型安全。因此,該文件認爲人們應該探索新的評估方法:這些方法既包括直接衡量可監控性的方法,也包括針對構成可監控性的特定屬性的方法。在該文件中,作者們列舉出了四種方法示例:
- 第一種方法是思維鏈可讀性評估方法,例如,使用另一個模型來評估給定智能體的思維鏈的清晰度和連貫性。
- 第二種方法是潛在推理能力評估。這類評估能夠考察模型在不進行外部化輸出的情況下,在各類高推理需求任務和智能體任務中的推理表現。
- 第三種方法是衡量思維鏈的因果相關性。例如,可以通過擾動其中一段思維鏈,然後觀察是否會對最終輸出產生影響。假如輸出變化率較低,可能表明該思維鏈更傾向於“虛構性”表達或“表演性”表達。還可以針對思維鏈監控器進行交叉驗證,以便檢查那些被思維鏈監控器認爲重要的 token 能否在白盒可解釋性方法中被識別爲關鍵內容。
- 第四種方法是可監控性的端到端評估。利用這一方法人們可以直接地衡量可監控性,例如通過考察思維鏈監控器在智能體環境中捕捉智能體不當行爲的有效性來衡量可監控性。
那麼,如何判斷思維鏈的可監控性是否足以作爲一種安全措施來使用?該文件指出,僅僅瞭解監控器的準確性並不足以確定其能否有效防止因智能體行爲不當而造成的傷害。例如,即便是一個具有高誤報率的監控器,當可以低成本地從模型中重新採樣時,它也能被用於標記可疑行爲。此外,大多數風險可能存在於人類攻擊者或行爲不端的智能體等敵對者試圖逃避監控的情境中。因此,在評估監控有效性的時候,要將敵對者納入考量因素。例如,可以讓紅隊參與其中,嘗試針對安全措施進行壓力測試。這裏的紅隊指的是專門負責評估和提升模型安全性的團隊或測試方法,即通過模擬惡意攻擊、利用系統漏洞或挑戰模型邊界,來發現模型可能存在的風險和弱點。
另外,到底哪些訓練時優化壓力(training-time optimization pressure)會降低思維鏈的可監控性?該文件指出,訓練過程的特性可能會對可監控性產生重大影響。但是,目前人們依舊不清楚的是:在可監控性不發生顯著下降的前提下,到底允許存在什麼類型?以及允許存在多大程度的直接優化壓力和間接優化壓力?
再就是,模型是否會故意模糊其推理過程?當使用思維鏈監控作爲安全措施時,一個顯而易見的擔憂是:如果模型知道自己的思維鏈正在被監控,那麼思維鏈是否會變得更難以被監控?該文件指出,人們可以針對模型進行壓力測試,以便查看它們是否能在不針對思維鏈監控器進行訓練的情況下隱藏惡意推理。
同時,哪些類型的架構會降低思維鏈的可監控性?在連續潛在空間中進行推理的模型,即使不存在任何優化壓力,也會天然地限制人們對其思維過程的瞭解。所以,人們應該研究的是:各種非標準架構在多大程度上降低了可監控性?以及在什麼條件下仍然可能保留部分可監控性?例如,人們可以通過混合方法在利用潛在計算的同時,保持對於推理過程的部分可見性。
另外,如何構建更好的思維鏈監控器?該文件指出,業內人士應該專注於通過零樣本提示,來讓能力較弱的語言模型充當監控器。並指出,未來人們可以通過利用測試時計算來探索提高監控器的性能。例如,監控器可以基於推理模型、或者允許它們通過向智能體提問來對其進行詢問。該文件還指出,另一個探索方向則涉及到針對監控器進行對抗訓練,以便對抗那些試圖隱藏不當行爲的智能體。

(來源:https://www.technologyreview.com/topic/artificial-intelligence/)

倡議開發者跟蹤模型的思維鏈可監控性,並將其視爲提升模型安全性的重要部分
如果高度智能的 AI 智能體具有可解釋性,那麼它們所帶來的諸多風險將會更加容易被解決。儘管人們在應用機制可解釋性上已經取得顯著進展,但是要將其轉化爲可靠、實用的工具來監管大模型智能體,仍然需要進一步的努力。鑑於思維鏈可監控性所帶來的獨特機遇,該文件認爲業內人士應該:
- 首先,開發有效的思維鏈可監控性評估方法,即開發並統一標準化的評估方法與指標,以便明確思維鏈何時具備了足夠的可監控性。
- 其次,當此類評估存在時,應在系統說明卡中公佈評估結果。一旦可信的思維鏈可監控性評估方法具備可用性,開發者就應該定期在其模型上運行這些評估,並在模型的系統說明卡中報告評估結果、所用方法以及存在的侷限性,並且要重複這一做法除非且直到這類評估被證明對其特定用例缺乏安全價值爲止。
- 再次,要在訓練和部署決策中運用可監控性評分,即開發者在訓練或部署特定模型時,應該將可監控性指標與其他能力評估和安全性評估一同納入考量。這些決策需要基於對於風險的整體評估,其中應該包含思維鏈的可監控性、監控系統的性能特徵,以及對於模型不當行爲傾向的預估。
另一種潛在的干預措施是,開發者要讓思維鏈變得可見,從而允許人類用戶發現問題並報告問題。然而,這可能也會產生適得其反的效果:它可能會帶來巨大的壓力,以至於迫使人們直接監督思維鏈以便使其“看起來安全”,並試圖規避常見的法律風險和道德風險,而這可能會破壞思維鏈的可監控性。關於此,本次文件的作者們表示暫時對此不做任何明確建議。

思維鏈監控是一種補充方案,而非替代方案
在關注思維鏈監控所帶來機遇的同時,還存在其他一些限制。
該文件指出,在不需要展示思考過程的情況下,思維鏈監控的確能夠檢測到一些不當行爲,但其本身並不能夠提供有力的安全證據。假如惡意推理能夠在激活過程中完成,那麼即使模型沒有明顯的惡意推理,其預測結果也可能會出現偏差。因此,該文件建議人們不要因爲此類監控而產生虛假的安全感。
同時,針對需要推理的危險任務進行監控,可能無法捕捉到所有的相關危害。因爲,一些危險任務可能根本不需要太多推理,而且隨着模型能夠在其激活過程中進行更復雜的推理,能夠滿足外部化推理特性的任務也會越來越少。
在更高級的具備更好情境感知能力的模型中,思維鏈監控可能會停止工作。所以,未來的模型可能會通過抑制其“展示思考”的傾向來規避檢測,並會在需要開展推理時故意針對推理過程進行模糊處理。
而假如要堅定地維護當前思維鏈行爲的既有模式,那麼可能會以犧牲更加有效的安全乾預措施爲代價。儘管這一觀點尚未得到業內共識,但是本次文件認爲,某些形式的過程監督有可能會通過針對模型推理進行有效干預,從而能夠顯著地改善模型的對齊性。因此,假如開發者所採取的策略僅僅致力於無條件地維持現有思維鏈的可監測性形式,那麼可能會錯失此類安全乾預的潛在價值。
基於這些原因,本次文件建議將思維鏈監控作爲現有安全研究方向的補充,而非作爲替代方案。
需要說明的是,所有監督方法和監管方法都存在侷限性,這會讓一些不當行爲成爲“漏網之魚”。因此,在打造未來 AI 智能體的安全措施上,可能需要採用多個監控層,而且這些監控層最好具有互不相關的故障模式。總的來說,思維鏈監控爲 AI 安全措施提供了寶貴補充,讓人們得以一窺 AI 智能體是如何做出決策的。然而,該文件指出目前的思維鏈可見度能否持續下去尚無定論。所以,業內人士應該充分利用思維鏈的可監控性,並研究如何保持其可監控性。
參考資料:
https://techcrunch.com/2025/07/15/research-leaders-urge-tech-industry-to-monitor-ais-thoughts/
https://tomekkorbak.com/cot-monitorability-is-a-fragile-opportunity/cot_monitoring.pdf
https://venturebeat.com/ai/openai-google-deepmind-and-anthropic-sound-alarm-we-may-be-losing-the-ability-to-understand-ai/
運營/排版:何晨龍