

最近,美國加州大學伯克利分校陳在俊助理教授團隊與合作者基於超多路複用集成光子學,開發了一種光學張量處理器(HITOP,Hypermultiplexed Integrated Tensor Optical Processor),運算速度達每秒數萬億次,吞吐量達 0.98TOPS,可應對多數 AI 應用需求。
這一架構的核心創新在於其獨特的空間、時間和波長三維光學並行計算策略:通過在時間域和波長域同時複用計算任務,HITOP 僅需 O(N)個片上電光調製器即可實現 O(N²)級別的計算吞吐量,從而在硬件資源利用效率上實現了質的飛躍。與傳統電子計算架構相比,HITOP 展現出顯著的能效優勢,其單位操作能耗可降低超過 100 倍。
值得注意的是,HITOP 通過引入時間積分器這一創新設計,巧妙地規避了傳統光學計算系統對高速高精度模數轉換器(ADC,analog-to-digital converters)的依賴。這一設計不僅大幅簡化了輸出電路結構,還顯著降低了系統整體能耗,解決了長期制約光學計算系統性能的關鍵瓶頸問題。

圖丨陳在俊團隊(來源:陳在俊)
從實現的性能方面來看,該系統在 10GS/s 的高數據速率下仍能保持 5-6 位的計算精度(計算誤差約 2.9%),可滿足圖像識別等多數 AI 任務對大規模矩陣運算的需求。實測數據顯示,HITOP 在處理大規模矩陣運算時的單位操作能耗僅爲 18 飛焦耳,這一數值比當前先進的電子計算系統(如 NVIDIA H100 GPU)低一個數量級以上。
此外,HITOP 的芯片面積效率達到 17.5GOPS/mm²,意味着在相同芯片面積下可完成更多計算任務,顯著提升了硬件資源利用率。這項研究不僅解決了光學計算系統的可擴展性問題,更爲 AI 和高性能計算領域提供了一種極具潛力的全新硬件實現方案。
日前,相關論文以《基於光子學的超多路複用集成光學張量處理器》(Hypermultiplexed integrated photonics–based optical tensor processor)爲題發表在 Science Advances[1]。美國南加州大學碩士畢業生歐紹元、加州大學伯克利分校博士生薛凱文是主要作者,陳在俊擔任通訊作者。

圖丨相關論文(來源:Science Advances)

多維信號處理機制:將乘法運算從“矩陣與向量”升級爲“矩陣與矩陣”
傳統電子計算硬件(如 GPU、TPU)在處理大規模 AI 模型時,正面臨能耗高、計算效率低的突出瓶頸。這一問題的根源在於電子架構的物理限制:電信號在銅線中傳輸時會因電阻產生顯著損耗,同時電子器件的時鐘頻率提升空間有限,導致數據吞吐量受限。
若以交通系統作類比,傳統電子架構就像平面交叉的單車道道路,數據信號如同密集的車流,極易因帶寬不足而引發“擁堵”。相比之下,光子計算則展現出顯著優勢——其利用光波導傳輸信號,不僅避免了電阻損耗,還能通過多波長複用實現並行光路,如同立體交通樞紐中的多層立交橋,可同時容納更多“車輛”高速通行。
光學模擬計算的研究淵源可追溯至 20 世紀中葉,當時已有科學家提出利用空間光路構建傅里葉變換計算器的方案。然而,受限於早期光學器件的集成度與調控精度,該技術長期未能實現規模化應用。直至近年,隨着集成光子學技術的突破性進展,與此同時,摩爾定律在電子器件領域逐漸逼近物理極限,光子計算才因其低能耗、高吞吐的特性重獲學界與產業界的廣泛關注。
近年來,衆多高校和研究機構陸續提出了多種光學計算架構,並在機器學習、圖形處理等領域展示了其大規模部署的可行性。然而,隨着系統中光學調製器數量的急劇增加,微納加工技術面臨巨大挑戰,同時光學損耗也限制了波導路徑的可擴展性。
更深層次的矛盾存在於系統級優化層面。雖然電光調製器已能實現皮秒級響應速度,但後端 ADC 的性能卻成爲整體算力的短板。現有技術中,維持高採樣率與高量化精度的 ADC 往往需消耗數十皮焦每轉換步的能耗,這與光計算單元飛焦級每操作的能耗形成巨大落差,導致系統能效優勢被部分抵消。
此外,當前多數光計算架構仍模仿電子計算的“存內計算”範式,卻忽略了二者在物理尺度上的本質差異:光學器件因受限於衍射極限,功能單元尺寸通常在百微米至毫米量級,而現代電子晶體管已縮至納米尺度。這種數量級的尺寸差異使得光學系統在集成密度上難以與電子芯片抗衡,也暴露出光子計算在有效縮放路線上的核心挑戰。
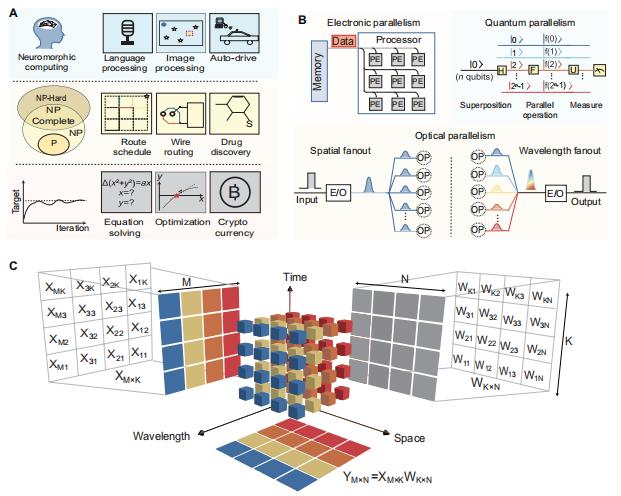
圖丨 HITOP 概念示意圖(來源:Science Advances)
針對上述瓶頸,研究團隊提出了全新的光計算芯片架構,其核心創新體現在系統架構設計層面。他們提出了“時間維度承載計算”的新範式:首先將數據編碼在時間序列上,再以時間維度作爲橋樑,與波長維度和空間維度實現協同計算。通過多維度協同計算策略,爲光學模擬計算提供了一種新的解決思路。
其突破在於:傳統光學計算實現 1000×1000 矩陣運算需要 100 萬個調製器(O(N²)規模),而 HITOP 架構僅需 1000-2000 個調製器(O(N)規模),這相當於將硬件複雜度降低了三個數量級。
這種多維信號處理機制使得系統能夠直接完成矩陣與矩陣的乘法運算,而傳統電子芯片通常僅能實現矩陣與向量的乘法運算。陳在俊對 DeepTech 表示:“這種突破性的計算能力源於光信號在時間、波長和空間三個維度的並行處理特性,這是電子計算架構難以實現的獨特優勢。”
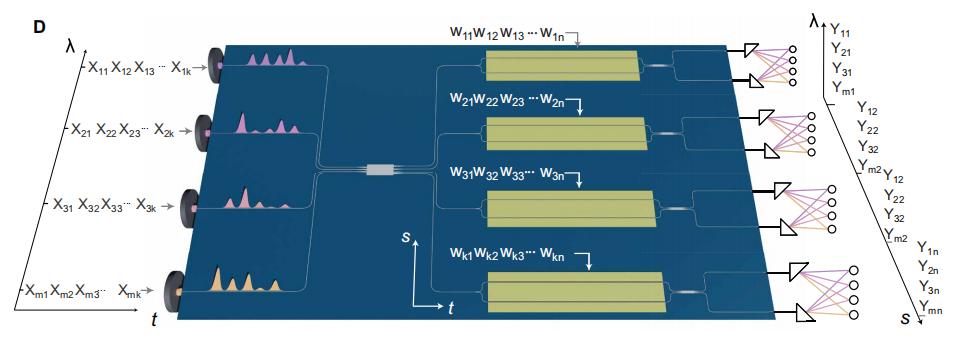
圖丨 HITOP 芯片架構(來源:Science Advances)
在材料選擇方面,研究團隊與加州大學伯克利分校喻夢潔助理教授、香港城市大學王騁副教授實驗室合作,採用了具有優異電光特性的薄膜鈮酸鋰(TFLN,Thin-Film Lithium Niobate)作爲光學計算平臺。該材料具備優異的電光特性,其較低的半波電壓(Vπ)顯著降低了電光轉換過程中的能耗,爲實現高效、低功耗的光學計算系統提供了基礎。

應用場景:從數據中心模型訓練到終端設備模型部署
陳在俊在德國馬克斯普朗克量子光學研究所和德國慕尼黑大學獲得博士學位,導師爲諾貝爾物理學獎獲得者特奧多爾·W·亨施(Theodor W. Hänsch),之後分別在馬克斯普朗克量子光學研究所和美國麻省理工學院迪爾克·英格倫(Dirk Englund)教授團隊從事博士後研究工作(DeepTech 此前報道:MIT團隊開發新型AI光子計算芯片,實現計算效率提高100倍)。
目前,陳在俊在加州大學伯克利分校成立了獨立實驗室,其研究方向主要聚焦於光計算技術及其應用的創新,研究內容涵蓋量子光學、壓縮態光子學和光學傳感技術等多個前沿領域。
近期,團隊正在開展存算一體化的新型光學傳感器方向研究,並探索量子增強傳感技術在自動駕駛等實際場景中的應用。此外,團隊還致力於將人工智能與量子光學方法相結合,以實現分子和原子尺度的高精度測量。
該研究歷時兩年,始於陳在俊實驗室剛成立之際。研究的核心挑戰主要集中在如何確保長時間、高速光學計算過程中的測量精度與系統穩定性。
在軟件架構層面,研究團隊採用任意波形發生器對光學系統作爲精確控制核心,通過高精度時序同步實現光學計算單元的數據採集與處理,並與計算機系統協同工作,成功實現了卷積神經網絡(CNN,Convolutional Neural Network)的運行。
在硬件測量方面,III/V 族半導體垂直腔面發射激光器(VCSEL,vertical-cavity surface-emitting laser)與薄膜鈮酸鋰集成芯片之間的時序校準問題尤爲關鍵,對實現高速測量的計算精度提出了嚴峻挑戰。
從計算原理來看,矩陣乘法運算(N×N 矩陣乘以 N×N 矩陣)的本質是,要求第一個矩陣中的所有行向量都必須與第二個矩陣中的所有列向量完成點積運算。
在這個過程中,光學計算的獨特優勢得以充分展現:系統可以在計算框架內實現天然的並行運算,並通過波長複用技術將不同計算任務在光學域進行有效分離。例如,當一個向量(維度爲 1×N)乘以一個矩陣(維度爲 N×N)時,傳統電子計算需要將該向量複製 N 次,然後分別與矩陣的每一列進行運算。
雖然從數學表達式看這個過程相對簡單,但在硬件實現層面卻異常複雜。研究團隊通過光學手段巧妙地解決了這一難題——利用光的波動特性自然地完成向量複製過程,這種基於波場的並行數據傳輸機制是電子計算難以達到的。
此外,他們所使用的計算元件都非常簡單。陳在俊解釋說道:“我們最終的目標是從簡單的計算單元開發出高算力、低能耗的光學計算系統,解決光學可擴展性。”
因此,他們選擇從最基礎的光學組件着手來構建系統。例如,僅需讓激光束依次通過兩個調製器就能實現乘法運算:第一個調製器完成 A 係數調製,第二個完成 B 係數調製,經過兩次調製後的輸出光強即對應 A×B 的結果。通過這種簡潔而高效的乘法單元,研究團隊成功構建起三維計算架構,並利用光學複製原理實現了前所未有的計算效率。
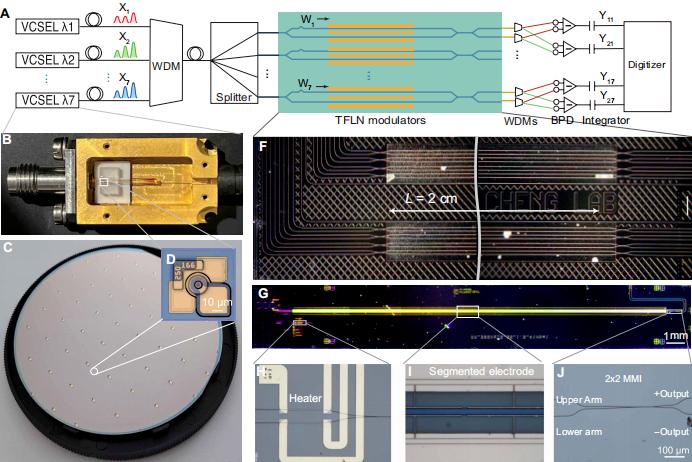
圖丨 HITOP 實驗裝置與器件平臺(來源:Science Advances)
在應用前景方面,這項技術直指當前 AI 算力發展的核心瓶頸,其應用場景涵蓋從數據中心模型訓練、邊緣實時決策、終端設備模型部署、氣候模擬等場景。以自動駕駛爲例,現代智能汽車通常搭載多個計算芯片,其中 30-40% 的整車能耗都消耗在計算任務上。這種低能耗、高算力的光學計算技術有望顯著提升終端設備的能效比。
實際上,AI 的發展水平在很大程度上受限於芯片性能,而光學計算的突破可能徹底改變這一局面。當算力得到質的提升後,此前受限於能耗和芯片效率的諸多技術瓶頸有望迎刃而解,更大規模的模型訓練將成爲可能。
該研究中的實驗數據顯示,HITOP 系統在圖像分類任務中表現出色,而所需的模型參數量僅約 40 萬。其中,在單層網絡(28×28→10)架構下,78.4ns 內完成圖像處理,分類準確率達 97%;在更復雜的三層網絡(28×28→100→10)Fashion MNIST 分類中,準確率保持 91.8%。
這自然引出一個關鍵問題:該技術能否支撐 GPT 級別的超大規模模型訓練?陳在俊指出,當系統規模擴展到 300×300 通道時,單個光學芯片的計算能力將相當於多個 GPU 的並行組合,屆時完全具備訓練大模型的硬件條件。
儘管當前的原型系統規模有限,但技術路線已經展現出巨大的發展潛力。特別值得一提的是,在實時性要求極高的自動駕駛場景中,現有系統需要 1 毫秒的反應時間,而 HITOP 已實現 100 納秒的極低延遲。可以預見,隨着系統規模的持續擴大,這項技術可能在自動駕駛等對實時性和能效要求嚴苛的領域發揮重要作用。
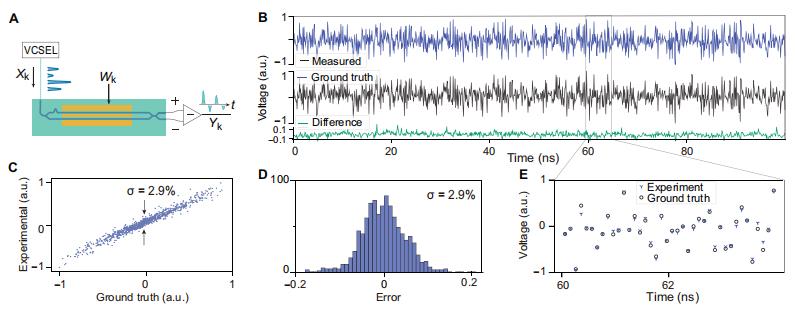
圖丨在 10GS/s 下對 HITOP 計算精度進行實驗驗證(來源:Science Advances)
現在,陳在俊正帶領團隊重點攻克光計算系統的相關技術難題並推進工程化。其首要目標是提升激光器的波長穩定性,通過優化系統架構將計算規模擴展到 300×300,同時增加波長和通道數量。儘管現有的硅光技術理論上支持這一規模,但在實際實現過程中仍面臨諸多技術挑戰。
他表示:“實現 300×300 的系統規模後,計算能力預計將達到 4000TOPS(每秒 4000 萬億次運算),這一性能將顯著超越當前主流的 NVIDIA GB200。”隨着先進封裝工藝的持續發展和系統集成度的不斷提高,時序校準等關鍵技術難題將逐步得到解決,進而爲光學計算系統的大規模商業化應用奠定堅實基礎。
參考資料:
1.Ou,S. et al. Hypermultiplexed integrated photonics–based optical
tensor processor. Science Advances 11, eadu0228(2025). https://www.science.org/doi/10.1126/sciadv.adu0228
排版:劉雅坤



