

隨着大模型的發展,大模型的能力正在從單輪靜態的問答、推理任務拓展到多步的、交互式的智能體任務,在軟件開發、電腦使用、遊戲博弈等任務中提出相應的測試基準和方法。然而,現有的測試基準主要集中在單智能體或純文本環境,缺少多智能體、多模態的大模型智能體測試基準,因此在近期一項研究中清華大學教授汪玉團隊的博士生徐澤來和合作者提出了 VS-Bench(Visual Strategic Bench), 以用於評估視覺語言模型(VLM,Vision-Language Model)在多智能體任務中的推理和決策能力。
爲什麼要在多智能體任務中評估大模型?因爲現實世界就是一個多智能體的環境,這樣的環境給大模型的能力提出了新的挑戰。
首先,在推理方面,因爲多智能體環境的結果依賴於所有智能體的聯合動作,所以智能體不僅需要自己能選擇合理的動作,還要能夠預測其他智能體的動作,即 theory of mind 的推理能力,才能在多智能體環境中取得好的效果。
其次,在決策方面,因爲多智能體環境中存在智能體之間的合作和競爭,同時各智能體的策略和行爲也在不斷變化,使得環境變得非平穩,從而要求智能體要在不確定性更強的環境中優化自己的長期目標,對其決策能力提出了更大的挑戰。
(來源:https://arxiv.org/pdf/2506.02387)
基於此,在本次研究之中,研究團隊提出了新的測試基準 VS-Bench,以用於評估視覺語言模型在多智能體任務中的推理和決策能力,包含了合作、對抗、混合三種類型的 8 個多智能體環境。研究團隊提出了 2 種互補的評估方式,一種是離線的策略推理(strategic reasoning)能力,通過智能體對其他智能體下一步動作的預測準確率來評估;另一種是在線的決策能力(decision-making),通過智能體獲得的長期回報來評估。研究團隊對包含推理模型、對話模型、開源模型三種共 14 個先進的視覺語言模型進行了測試,有以下主要發現:

圖 | 徐澤來(來源:徐澤來)
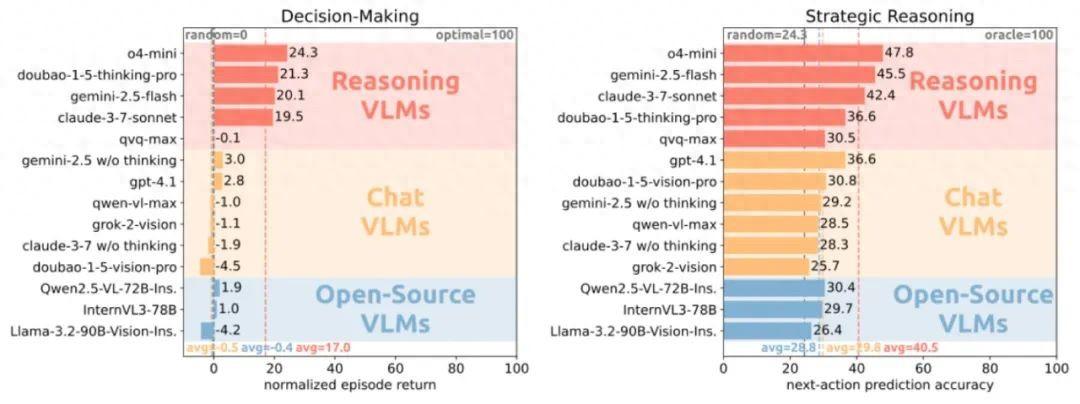
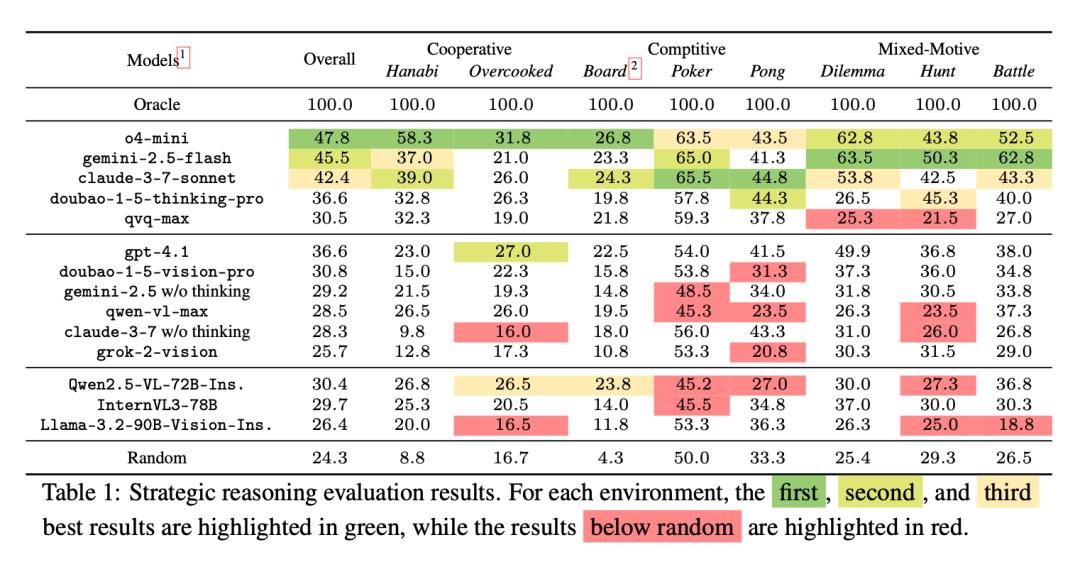
主要發現之一是:現有大模型具有初步的策略推理能力,但距離準確預測其他智能體的動作還有較大差距。所有 14 個大模型都超過了隨機智能體(隨機推理),但結果最好的大模型 o4-mini 也只有 47.8% 的綜合準確率。整體而言,推理模型最強,而對話模型和開源模型性能接近。
(來源:https://arxiv.org/pdf/2506.02387)
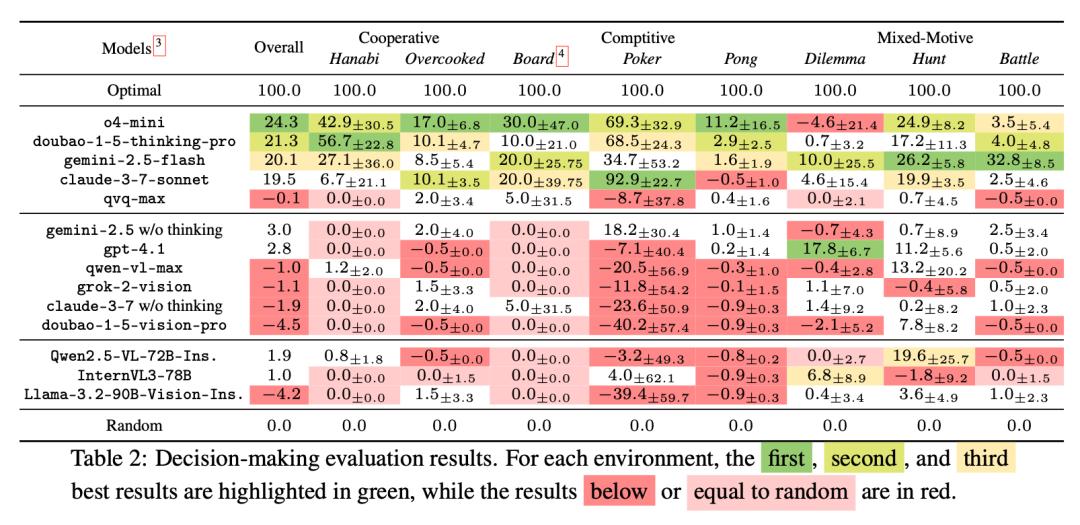
主要發現之二是:現有大模型在多智能體任務中的決策能力很弱。14 個大模型中的 10 個都只得到了和隨機智能體相近的綜合分數,只有 3 個推理模型明顯優於隨機智能體,但是性能最好的大模型 o4-mini 也只有 24.3% 的綜合得分。
(來源:https://arxiv.org/pdf/2506.02387)
徐澤來指出,在絕大多數任務和環境中,推理模型都顯著優於對話模型和開源模型,但是在某些多智能體社會困境的任務中,開源模型性能有顯著的提升,甚至超過了部分推理模型。他們通過分析發現,這是因爲開源模型雖然單個模型能力較差,但更傾向於合作共贏的行爲,從而在這些任務中得到甚至超越推理模型的結果。
具體而言,本次研究的環境中有一個類似囚徒困境的環境,如果各個智能體合作則都能雙贏,但智能體可能會爲了更大的個人利益而選擇背叛,而如果所有智能體都背叛則會陷入雙輸。研究團隊發現推理模型通常更加“理性”,更有可能爲了個人利益而選擇背叛;而開源模型更傾向於合作,從而讓各個智能體都能得到較高的收益。

圖 | 本次論文的共同作者徐哲軒(來源:徐哲軒)

圖 | 本次論文的共同作者易翔敏(來源:易翔敏)
未來,他們希望該工作能夠成爲大模型在多智能體任務中的一個測試基準,推動領域內多智能體算法和應用的進步,從而使大模型智能體能被更好地應用在遊戲 AI、人機協作等多智能體場景中。
下一步,研究團隊計劃從幾個方向來進一步擴展本次工作:
首先,要進行人類實驗。讓人類和大模型完成同樣的任務,得到平均人類的分數,從而更好地評估大模型現在的能力。
其次,要拓展環境和模型。爲此,研究團隊計劃加入更多不同類型和難度的多智能體環境,並測試更多更新的大模型。
參考資料:
https://arxiv.org/pdf/2506.02387
運營/排版:何晨龍



