

在剛剛舉辦的計算語言學和自然語言處理領域的頂級國際會議 ACL 上,由 DeepSeek 創始人梁文鋒親自署名的論文從 8000 多篇論文中脫穎而出,成爲本屆大會的最佳論文之一。

(來源:資料圖)
該論文的其他合作者分別來自北京大學和美國華盛頓大學,擔任第一作者的是 Jingyang Yuan。

圖 | Jingyang Yuan(來源:https://ieeexplore.ieee.org/author/37090050318)
在這篇論文中,他們提出了一種名爲 NSA 的本機可訓練的稀疏注意力機制,該機制將算法創新與硬件優化相結合,以實現高效的長上下文建模。
NSA 採用了一種動態分層稀疏策略,將粗粒度 token 壓縮與細粒度 token 選擇相結合,以同時保持全局上下文感知和局部精確性。
這一方法通過以下兩項關鍵創新推動了稀疏注意力設計的發展:
一方面,他們通過設計算術強度平衡的算法,並結合針對現代硬件的實現優化,實現了顯著的速度提升。
另一方面,他們實現了端到端的訓練,在不犧牲模型性能的前提下減少了預訓練的計算量。
如下圖所示,實驗表明,在通用基準測試、長上下文任務和基於指令的推理任務中,使用 NSA 預訓練的模型表現與全注意力模型相當或更優。
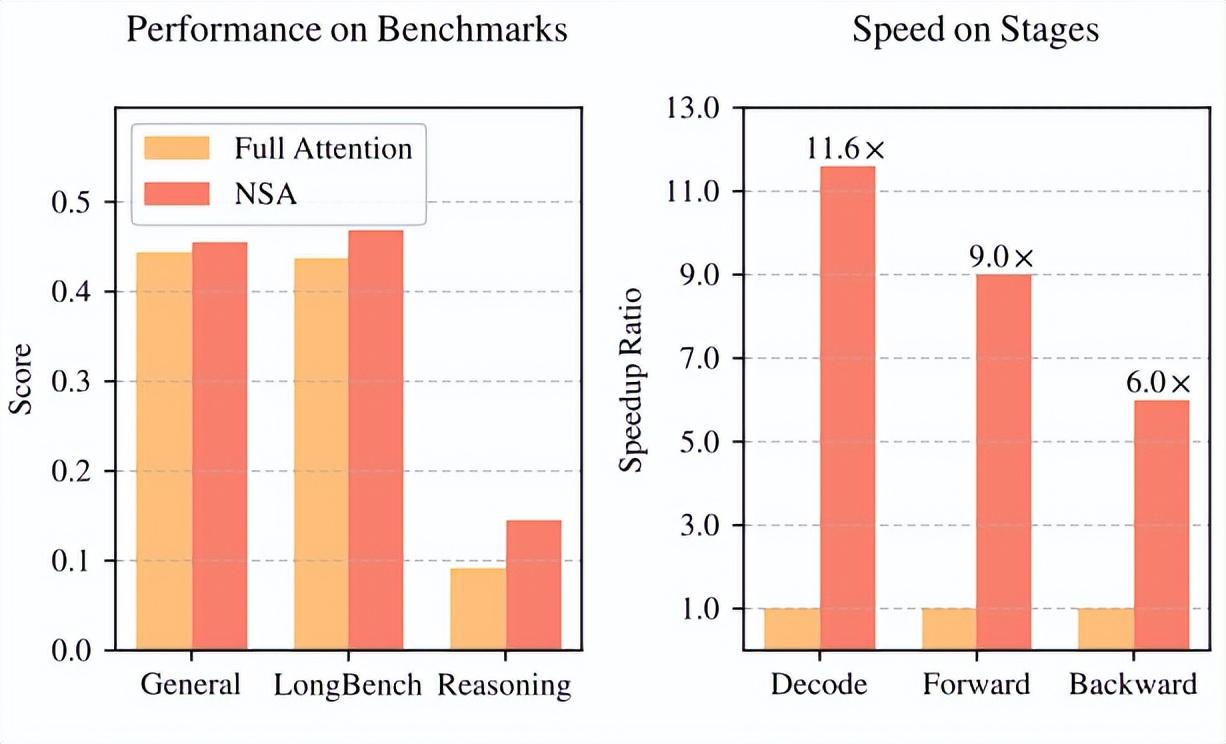
(來源:https://arxiv.org/pdf/2502.11089)
同時,在解碼、前向傳播和後向傳播方面,NSA 在 64k 長度序列上相較於全注意力機制實現了顯著加速,驗證了其在整個模型生命週期中的效率。

圖 | 相關論文(來源:https://arxiv.org/pdf/2502.11089)

長上下文建模是下一代大模型的關鍵能力
研究界日益認識到,長上下文建模是下一代大模型的關鍵能力,其推動因素是現實世界中的各種應用,包括深度推理、庫級代碼生成和多輪自主代理系統。然而,標準注意力機制的高計算成本帶來了巨大的計算挑戰。稀疏注意力機制爲在保持模型性能的同時提高效率提供了一個有前景的方向。
最近領域內的一些突破,包括 OpenAI 的 o 系列模型、DeepSeek-R1 和 Gemini 1.5 Pro,使模型能夠處理整個代碼庫、長文檔,在數千個 token 上保持連貫的多輪對話,並在較長依賴關係中進行復雜推理。
然而,隨着序列長度的增加,基礎注意力機制的高度複雜性成爲關鍵的延遲瓶頸。
理論估計表明,在解碼 64k 長度上下文時,採用 softmax 架構進行注意力計算佔總延遲的 70% 至 80%,這凸顯出人們迫切需要更高效的注意力機制。
實現高效長上下文建模的一種自然方法是利用 softmax 注意力機制的固有稀疏性,即選擇性地計算關鍵的查詢-鍵對,這可以在保持性能的同時顯著降低計算開銷。近期的研究進展通過多種策略展示了這一潛力:鍵值(KV)緩存淘汰方法、分塊 KV 緩存選擇方法,以及基於採樣、聚類或哈希的選擇方法。
儘管這些策略頗具前景,但現有的稀疏注意力方法在實際部署中往往表現不佳。許多方法未能實現與其理論增益相當的速度提升;此外,大多數方法缺乏有效的訓練時間支持,無法充分利用注意力機制的稀疏模式。
爲了克服這些侷限性,部署有效的稀疏注意力機制必須應對兩個關鍵挑戰:
(1)解決硬件適配的推理加速挑戰:將理論計算減少轉化爲實際速度提升,需要在預填充和解碼階段都進行硬件友好的算法設計,以便緩解內存訪問和硬件調度瓶頸;
(2)解決訓練感知算法設計的挑戰:通過可訓練算子實現端到端的計算,以便降低訓練成本,同時還得保持模型性能。這些要求對於實際應用實現快速長上下文推理或訓練至關重要。當同時考慮這兩個方面時,現有方法仍然存在顯著的差距。
因此,爲了實現更有效且高效的稀疏注意力機制,他們提出了 NSA 這種原生可訓練的稀疏注意力架構,並集成了分層 token 建模。如下圖所示,NSA 通過將鍵和值組織成時間塊,並通過三條注意力路徑來處理它們,從而減少每次查詢的計算量:壓縮的粗粒度 token、選擇性保留的細粒度 token 以及用於獲取局部上下文信息的滑動窗口。
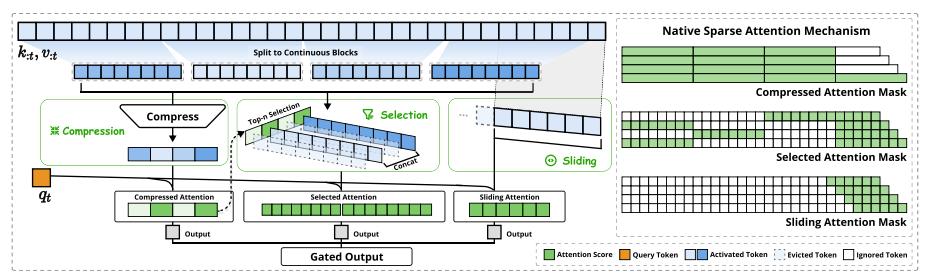
(來源:https://arxiv.org/pdf/2502.11089)
然後可以實現專門的核函數,以最大限度地提高其實用效率。針對上述關鍵需求,NSA 推出了兩項核心創新:
首先是硬件對齊系統:針對 Tensor Core 的利用率和內存訪問,優化塊級稀疏注意力機制,確保算術強度平衡。
其次是訓練感知設計:通過高效算法和反向操作符實現穩定的端到端訓練。這一優化使 NSA 能夠同時支持高效部署和端到端訓練。
研究中,該團隊通過在真實世界語言語料庫上的綜合實驗來評估 NSA。在擁有 2600 億個 token 的 270 億參數的 Transformer 主幹網絡上進行預訓練後,他們評估了 NSA 在通用語言評估、長上下文評估和思維鏈推理評估中的表現。並進一步比較了在英偉達 A100 GPU 上採用優化 Triton 實現的核速度。實驗結果表明,NSA 的性能與全注意力基線相當或更優,同時優於現有的稀疏注意力方法。此外,與全注意力機制相比,NSA 在解碼、前向和後向階段均實現了顯著加速,且隨着序列長度的增加,加速比也隨之提高。這些結果驗證了他們的分層稀疏注意力設計有效地平衡了模型能力和計算效率。

三個角度評估 NSA
實驗中,他們從以下三個角度來評估 NSA:通用基準性能、長上下文基準性能以及思維鏈推理性能,並與全注意力基線以及當前最先進的稀疏注意力方法進行比較。
遵循最先進的大模型的常見做法,他們的實驗採用了一種結合分組查詢注意力(GQA,Grouped-Query Attention)和混合專家(MoE,Mixture-of-Experts)的骨幹網絡,總參數爲 270 億,其中活躍參數爲 30 億。該模型由 30 層組成,隱藏層維度爲 2560。對於 GQA,他們將組數設置爲 4,總共有 64 個注意力頭。對於 MoE,他們採用了 DeepSeek MoE 結構,該結構包含 72 個路由專家和 2 個共享專家,並將 top-k 專家數設置爲 6。爲確保訓練穩定性,第一層中的 MoE 被替換爲 SwiGLU 形式的 MLP。
該團隊在論文中指出,其所提出的架構在計算成本和模型性能之間實現了有效的權衡。其將全注意力模型和稀疏注意力模型均在 2700 億個 8k 長度文本的 token 上進行預訓練,隨後使用 YaRN 在 32k 長度文本上進行持續訓練和監督微調,以實現長上下文適應。兩種模型都經過充分訓練以實現完全收斂,以確保公平比較。如下圖所示,NSA 和全注意力(Full Attention)基線的預訓練損失曲線呈現出穩定且平滑的下降趨勢,且 NSA 模型的表現始終優於全注意力模型。
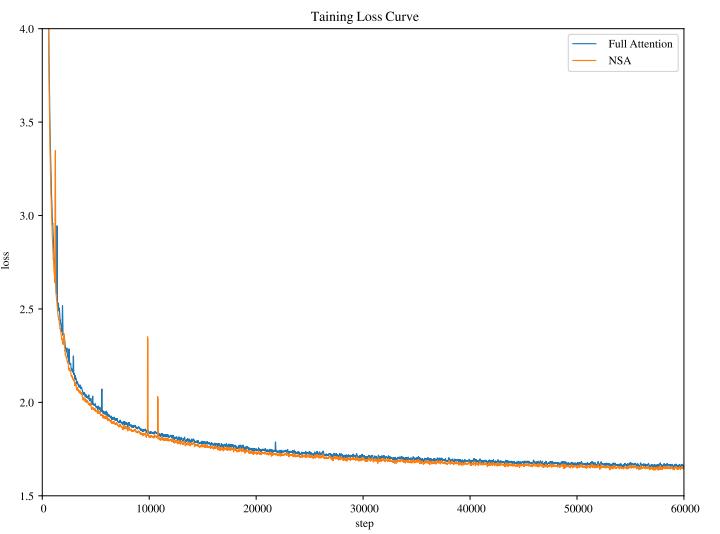
(來源:https://arxiv.org/pdf/2502.11089)
除了與全注意力(Full Attention)方法進行比較外,他們還評估了幾種最先進的推理階段稀疏注意力方法:H2O、infLLM、Quest 和 Exact-Top,這些方法首先計算全注意力得分,並選擇與每個查詢相對應的前幾個得分最高的鍵,然後計算這些位置上的注意力。與此同時,這些方法涵蓋了多種稀疏注意力範式。
在一般評估中,當大多數樣本的長度位於稀疏注意力基線的局部上下文窗口內時,這些方法實際上等同於全注意力方法。因此,在這種設置之下,該團隊僅展示了 NSA 與全注意力基線之間的比較結果。在長文本評估中,他們對所有基線方法進行了比較,並將所有稀疏注意力方法的稀疏度設置爲相同,以便確保比較的公平性。對於需要進行長文本監督微調的思維鏈推理評估,他們僅將比較範圍限定在全注意力模型上,因爲稀疏注意力基線模型不支持訓練。
在一系列涵蓋知識、推理和編碼能力的綜合基準測試上,該團隊對預訓練的 NSA 和全注意力基線進行了評估,這些基準測試包括 MMLU、MMLU-PRO、CMMLU、BBH、GSM8K、MATH、DROP、MBPP 和 HumanEval。

圖 | 對比結果(來源:https://arxiv.org/pdf/2502.11089)
儘管 NSA 較爲簡潔,但其整體表現卻十分出色,在 9 項指標中有 7 項優於包括全注意力機制在內的所有基線模型。這表明,儘管在較短序列上,NSA 可能無法充分發揮其效率優勢,但其表現仍然強勁。值得注意的是,NSA 在推理相關基準測試中表現出了顯著的提升(DROP:+0.042,GSM8K:+0.034),這表明該團隊所使用的預訓練有助於模型發展出專門的注意力機制。這種稀疏注意力預訓練機制迫使模型聚焦於最重要的信息,通過過濾掉無關注意力路徑中的噪聲,從而能夠潛在地提升性能。在不同評估中的一致表現也驗證了 NSA 作爲一種通用架構的穩健性。
同時,他們還進行了長上下文評估。如下圖所示,在 64k 上下文的“大海撈針”測試中,NSA 在所有位置均實現了完美的檢索準確率。
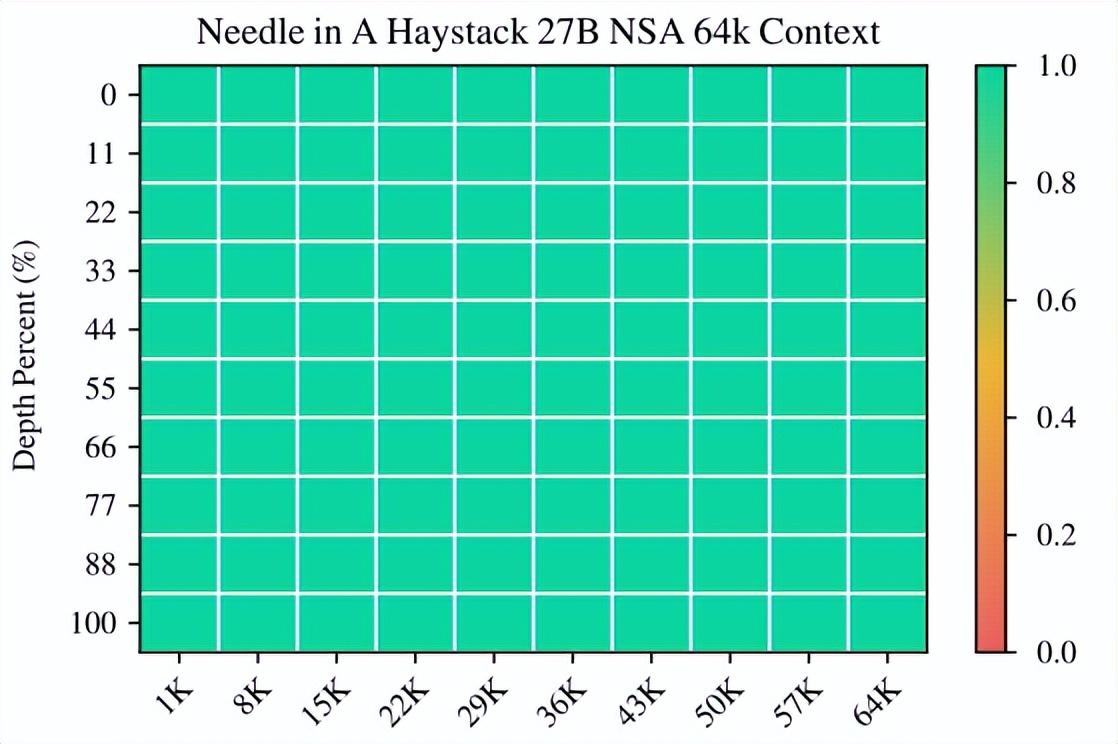
(來源:https://arxiv.org/pdf/2502.11089)
這種表現源於該團隊的分層稀疏注意力設計方案,該設計方案結合了壓縮 token 以便實現高效的全局上下文掃描,以及能夠通過選擇 token 實現精確的局部信息檢索。粗粒度壓縮則能以較低的計算成本識別出相關的上下文塊,而對選定 token 的 token 級注意力能夠確保關鍵細粒度信息的保留。這種設計使得 NSA 既能保持全局感知,又能確保局部精確性。
該團隊還在 LongBench 上對 NSA 與最先進的稀疏注意力方法和全注意力基線進行了評估。爲確保稀疏性一致,他們將所有稀疏注意力基線中每個查詢激活的 token 設置爲 2560 個,這對應於在處理 32k 序列長度時,NSA 中激活的 token 的平均數量。繼 StreamLLM 之後,該 token 預算包括前 128 個 token 和 512 個本地 token。他們排除了 LongBench 中的某些子集,因爲它們在所有模型中的得分都很低,可能無法提供有意義的比較。如下表所示,NSA 取得了最高的平均分 0.469,優於所有基線方法(比全注意力機制高出 0.032,比精確頂部方法高出 0.046)。
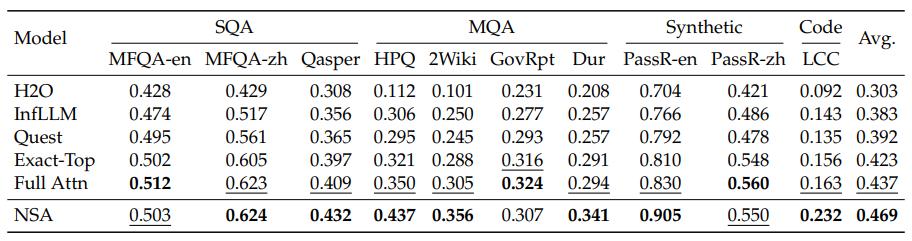
(來源:https://arxiv.org/pdf/2502.11089)
這一優異表現源於以下兩項關鍵創新:第一,他們獨創的稀疏注意力設計,能夠在預訓練期間對稀疏模式進行端到端的優化,促進稀疏注意力模塊與其他模型組件之間的同步適應;第二,分層稀疏注意力機制實現了局部和全局信息處理之間的平衡。
值得注意的是,NSA 在需要長上下文複雜推理的任務上表現出色,在多跳問答任務(HPQ 和 2Wiki)上相較於全注意力機制分別提升了+0.087 和+0.051,在代碼理解任務上超越了基線模型(LCC:+0.069),並且在段落檢索任務上優於其他方法(PassR-en:+0.075)。這些結果驗證了 NSA 在處理多樣化長上下文挑戰的能力,其原生預訓練的稀疏注意力在學習任務最優模式方面提供了額外優勢。
在思維鏈推理評估中,爲了評估 NSA 與先進下游訓練範式的兼容性,該團隊研究了其通過後訓練獲取思維鏈數學推理能力的能力。鑑於強化學習在較小規模模型上的效果有限,他們採用了 DeepSeek-R1 的知識蒸餾方法,利用 100 億個 32k 長度數學推理軌跡的 token 進行監督微調(SFT,supervised fine-tuning)。這產生了兩個可比較的模型:Full Attention-R(全注意力基線模型)和 NSA-R(該團隊的稀疏變體模型)。他們在 AIME 24 基準測試中評估了這兩個模型。爲了驗證推理深度的影響,他們在兩種上下文限制(8k 和 16k 個 token)下進行了實驗,以便衡量擴展推理鏈是否能提高準確性。
如下表所示,在 8k 上下文設置下,NSA-R 的準確率顯著高於全注意力-R(+0.075),且在 16k 上下文設置下,這一優勢仍然存在(+0.054)。
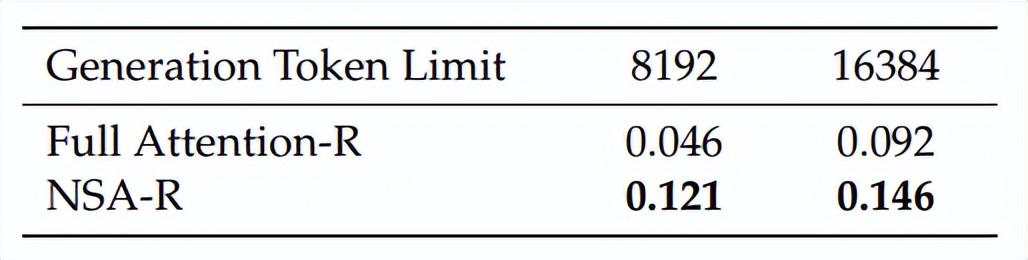
(來源:https://arxiv.org/pdf/2502.11089)
這些結果驗證了原生稀疏注意力機制的兩大關鍵優勢:(1)預訓練的稀疏注意力模式能夠高效捕捉對複雜數學推導至關重要的長距離邏輯依賴關係;(2)本次架構採用與硬件相匹配的設計,保持了足夠的上下文密度,以支持不斷增加的推理深度,同時避免災難性遺忘。
這種在不同上下文長度上的一致性表現證明,當稀疏注意力機制被原生整合到訓練流程中時,它能夠勝任高級推理任務。
(來源:https://openreview.net/profile?id=~Jingyang_Yuan1)
另據悉,擔任本次論文第一作者兼通訊作者的 Jingyang Yuan 於 2022 年獲得北京大學計算機科學學士學位,預計將於 2027 年從北京大學博士畢業,他的研究方向包括圖表示學習、神經物理模擬、大模型等。
參考資料:
https://ieeexplore.ieee.org/author/37090050318
https://scholar.google.com/citations?user=mDwlqfkAAAAJ&hl=en
https://arxiv.org/pdf/2502.11089
運營/排版:何晨龍



