

爲什麼自動駕駛系統在某些場景中越訓練越安全,然而在其他場景中卻突然出錯?長期以來,這種被稱爲“蹺蹺板效應”的問題成爲自動駕駛安全訓練的挑戰。
近期,清華大學封碩副教授與美國密西根大學團隊用一種“反直覺”的方法解決了這個問題。他們提出了一種密集學習(Dense Learning)方法,從理論上重新審視了自動駕駛訓練中的高價值數據。
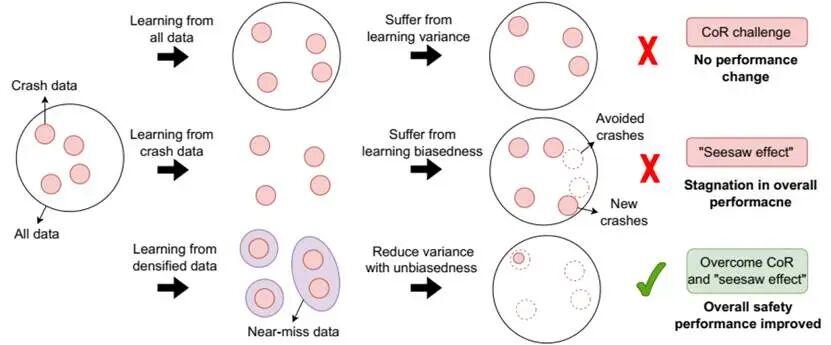
密集學習方法的核心思想,不是大量學習無效的海量數據,而是主動“學得更少”,即對少部分數據學得更密集、學得更多,而對其他數據則不學或學得更少,進而保留真正有價值的信息密集型樣本。
這就像在考試前有效刷題一樣,假如你有 1 萬道模擬試題,傳統方法是把每道題都做一遍,對於提分效果並不顯著。與太簡單和難度高的題相比,難度適中的題反而更有價值:做對了總結成功的經驗,做錯了總結失敗的教訓。這項技術就像是給你配了智能題庫,它能從題海中精準篩選出那些“差點就做對了”的關鍵題目,進而實現成績的高效突破。
基於增強現實測試平臺,該團隊使用密集學習方法對 L4 級自動駕駛汽車進行了安全性訓練和測試。結果表明,該方法打破了自動駕駛安全性的增長停滯,並將自動駕駛的安全性提升了 1-2 個數量級。
“這項研究對於自動駕駛汽車達到乃至超越人類駕駛員的安全水平,對助力自動駕駛從輔助駕駛更快地走向無人駕駛具有重要意義。”封碩對 DeepTech 表示。

圖丨封碩(來源:受訪者)
相關論文以《通過密集學習突破自動駕駛安全性能停滯瓶頸》(Breaking through safety performance stagnation in autonomous vehicles with dense learning)爲題發表在 Nature Communications[1]。清華大學自動化系封碩副教授是第一作者,密西根大學劉向宏(Henry X. Liu)教授擔任通訊作者。

圖丨相關論文(來源:Nature Communications)
行業困境:爲什麼 AI 數據“越喫越笨”?
近年來,隨着自動駕駛技術的持續發展,安全性已成爲制約其大規模商業落地應用的核心瓶頸。爲提升自動駕駛的安全性,現有的深度學習方法面臨着信號微弱、方差巨大的行業困境,目前的方法通常依賴事故場景數據進行訓練。但關鍵問題在於,如何高效發現自動駕駛中的長尾風險事件?
在此過程中,容易產生一種“蹺蹺板效應”(Seesaw Effect)。馬斯克也曾公開提到過這種效應,他認爲找到相關案例和數據投餵給自動駕駛大模型,當完成模型訓練後,訓練過的數據可能會沒問題,但是當將大模型部署到實車上,會在訓練以外的方面冒出新的問題。
可以理解這是一種“此消彼長”的關係:自動駕駛模型在部分場景中提升了安全性,但與此同時,在其他場景中相對容易出現安全性退化,這會導致事故如同“按下葫蘆浮起瓢”那樣並非真正減少。
其根本原因在於,高價值的安全攸關事件具有極高的稀疏度,傳統深度學習訓練過程中損失函數梯度估計的方差過大,導致無法進行有效學習。
業界一般會採取兩種應對方案,第一種方案是高度關注失敗數據,例如特斯拉在採集人類駕駛中難以處理場景的方式進行系統訓練;第二種方案是採取規則或形式化方法約束系統,如責任敏感安全模型。
但兩種方案各有侷限性:第一種方案容易因理論支撐不足而導致偏差,第二種方案則應對複雜的現實環境仍具挑戰。
破局關鍵:聚焦高價值“避險”數據
傳統思路僅關注事故場景,而該團隊提出的密集學習方法利用具有高信息量的安全攸關場景數據,以及可避免的事故場景數據進行訓練,並根據這些數據對深度強化學習策略梯度的貢獻程度、出現頻率進行自適應採樣,從而顯著提升了訓練數據中包含的高價值信息的密度。
(來源:Nature Communications)
傳統深度強化學習基於蒙特卡洛估計來更新策略梯度,但在罕見事件場景下,絕大多數樣本的梯度貢獻接近於零,在海量噪聲中有價值的信息往往容易被淹沒。
研究團隊通過理論推導分析了蹺蹺板效應,指出該效應背後的核心與稀疏性災難密切相關,並通過一套算法給出高價值數據的定義以及自動生成與篩選高價值樣本的方法。根據推導結果,最優的訓練數據分佈應滿足兩個條件:一是數據對策略梯度的貢獻非零,二是在現實世界中的出現頻率。
我們經常說“失敗乃成功之母”,但研究團隊發現,在自動駕駛領域更適用的一句話是“成功乃成功之母”或者“差點成功是通往成功的基石”:“失敗”的數據訓練不僅可能遇到瓶頸,甚至還可能導致原本表現良好的場景性能下降。原因在於,單純堆砌事故數據會讓模型過度擬合高風險場景,反而在常規場景中表現不佳,這正是“蹺蹺板效應”的體現。
也就是說,不能只用表現不好的案例進行數據訓練,真正高價值的是那些可避免的事故或可避免的風險,以及邊緣事件,即險些發生的事故的數據。尤其是,那些自動駕駛系統無論如何也學不會如何避免的事故場景,將其它用於模型訓練的作用並不大。
爲此,研究人員設計了包括三個層級的數據密化機制,不僅大幅提升了訓練數據的信息密度,在保證策略梯度估計無偏性的前提下,密集學習方法還顯著降低了訓練的方差,成功突破了自動駕駛安全性能的停滯瓶頸。
應用驗證:從虛擬仿真到現實街道,顯著降低事故率
有了高價值數據,接下來的問題就是如何用它們來進行自動駕駛的數據訓練。如果直接用於數據訓練,仍然難逃“蹺蹺板效應”。
2023年,封碩與合作者首次揭示了自動駕駛汽車安全性挑戰背後的科學難題——稀疏度災難(Curse of Rarity),並以封面論文形式發表於Nature。相關研究開闢了基於生成式 AI 的安全性加速測試與可持續學習框架,將仿真與實車測試速度提高 3 至 5 個數量級。並且,有可能對現有的強化學習、監督學習、預訓練等方向的方法理論帶來衝擊。
在此基礎上,該團隊對上述自動駕駛測試方法進行了系統性迭代推廣,通過密集學習聚焦高價值數據,讓自動駕駛模型在持續學習中不斷提升安全性。研究人員通過融合負責自動駕駛的模塊,爲模型打造了一個“AI 安全教練”SafeDriver。
當發現駕駛有問題或有風險時,它會接管或干預基礎自動駕駛系統,其餘時刻則保持“沉默”。重要的是,這種干預並非靠規則設計,而基於密集學習的數據訓練。
結果顯示,該方法可將原本安全事故率爲 10-5 的 AI Agent,再降低 1 到 2 個數量級。這爲打造更高效的數據閉環,以及實現自動駕駛持續進化提供了一種可行路徑。
圖丨研究團隊對真實自動駕駛汽車進行訓練和測試的結果(來源:Nature Communications)
研究團隊在仿真和實車方面的實驗證明,SafeDriver 可與多種 AI Agent 有效配合。從仿真實驗來看,整體碰撞率和可避免事故率都表現出大幅度降低。其中,高速場景降低 86.3%,城市場景降低 98.0%,環島場景降低 74.5%;在城市 SUMO 模型測試中,可避免碰撞率降幅最高可達 98.9%,提升幅度約 2 個數量級。
爲驗證方法的泛化能力,研究團隊還在 nuPlan 基準測試上進行了評估測試。以 SOTA 級 PDM-Hybrid 模型爲基礎,SafeDriver 在預測到 2 秒內碰撞時接管控制。結果顯示,總碰撞數降低了 21.7%,自動駕駛責任碰撞則降低 29.2%。
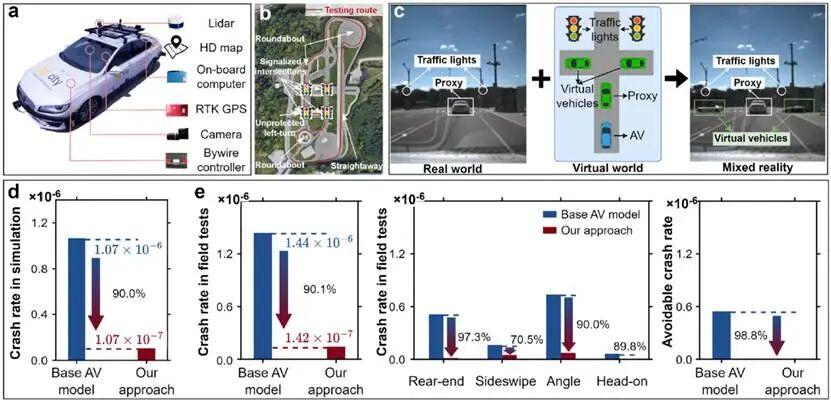
在實車測試方面,研究人員在密西根大學的 Mcity 測試場進行了混合現實實驗,通過融合虛擬背景車輛與真實道路基礎設施,構建出高保真的安全關鍵場景。從結果來看,實體車輛碰撞率從 1.44×10⁻⁶ 降低到了1.42×10⁻⁷,降幅達 90.1%;可避免事故降低幅度則實現了 98.8%。
從仿真與實車的測試結果中可以看到,SafeDriver 的作用相當於教會了 AI學會在自動駕駛中避險,爲未來自動駕駛真正接管和幫助人類開車奠定了基礎。封碩指出,Scaling Law 也適用於這項技術,如果 SafeDriver 能有更多的數據、更大的網絡、更長的訓練時間,安全事故率可能進一步降低。
在未來的研究中,該團隊計劃與車企密切合作,將自動駕駛安全做到量產實車,推動它從輔助駕駛向無人駕駛發展。“這項研究對解決蹺蹺板效應具有顯著的價值,它不僅可應用於自動駕駛領域,未來還有望進一步拓展至具身智能領域以及安全關鍵系統(例如醫療機器人、航空航天)的AI訓練中。”封碩表示。
參考資料:
1.https://www.nature.com/articles/s41467-026-69761-x
排版:胡莉花



