

在通往通用智能(AGI)的道路上,世界模型(World Model)正被視爲最關鍵的下一步。
通俗來說,世界模型就像是給 AI 裝上了一個“大腦模擬器”。它讓機器人不再僅僅是機械地執行指令,而是具備了在想象空間中預演未來的能力。當一個機械臂試圖抓取杯子時,世界模型允許它在真正動手前,先在腦海中模擬不同動作可能導致的結果。
爲了構建這種模型,圖靈獎得主楊立昆提出了聯合嵌入預測架構(JEPA)。該方法不直接讓 AI 預測複雜的畫面變化,而是先把畫面“壓縮”成一串簡單的核心特徵,再讓 AI 學怎麼預測這些核心特徵的變化。這樣一來,AI 不用關注畫面的細枝末節,只抓關鍵規律,效率會高很多。
然而,傳統 JEPA 技術打造的 “模擬器”,始終存在覈心痛點,成爲其落地應用的阻礙。
其一,訓練易 “表示崩潰”,穩定性差。爲了輕鬆完成特徵預測任務,AI 會出現“偷懶”行爲:將所有不同的視覺輸入映射爲幾乎相同的潛特徵,看似預測精準,實則這些特徵毫無實際價值,這一問題被稱爲“表示崩潰”;其二,超參數繁瑣,調參成本極高。主流端到端 JEPA 方法如 PLDM 擁有 6 個可調超參數,參數的細微變化都會導致模型性能天差地別,調參不僅需要大量的時間和計算資源,且參數無法跨任務複用,換一個任務就需要重新調試,門檻極高。
其三,計算成本高,規劃運行緩慢。部分方法爲避免“表示崩潰”,會依賴提前訓練好的超大視覺預訓練模型作爲基礎,雖能提升穩定性,卻讓模型體積臃腫、編碼效率低下,AI 完成一次決策規劃需要耗費大量時間。
近日,楊立昆團隊發表的論文,提出了一款名爲 LeWorldModel(簡稱 LeWM)的全新世界模型,核心解決了傳統 JEPA 訓練不穩定、易崩潰、超參數多、計算成本高的問題,是首個能從原始像素數據端到端穩定訓練的世界模型。整個模型就 2 個核心組件、2 個損失項,15M 參數,單 GPU 幾小時就能訓完,只有 1 個有效可調超參數。

(來源:上述論文)
LeWM 的組成特別精簡,包括兩部分。一個是編碼器,用輕量的視覺模型,把攝像頭拍的彩色畫面,變成一串簡短的核心特徵,抓住畫面裏的關鍵信息;另一個是預測器,根據 “當前的核心特徵以及要做的動作”,精準預測下一步的核心特徵,比如 “推一下方塊,它的位置特徵會變成什麼樣”,學懂環境的運行規律。
LeWM 最核心的突破,在於用兩個簡單且有科學支撐的訓練目標,從根本上解決了傳統 JEPA 的“表示崩潰”問題,徹底摒棄了經驗性技巧。其一爲預測損失,是讓 AI 精準預測未來的核心特徵,保證學的規律有用;其二是 SIGReg 正則化,逼着 AI 把核心特徵分佈得均勻多樣,不讓它把所有畫面都映射成一樣的特徵。
同時,LeWM 把調參的難度降到了最低,過去要調 6 個參數,現在只需要調 1 個,而且調參的方法特別簡單,不用反覆試錯,普通人也能上手。
在實際性能測試中,研究團隊在二維導航、機械臂控制、推方塊等經典連續控制任務上測試了 LeWM,並與當前主流的 JEPA 方法(DINO-WM、PLDM)、行爲克隆(GCBC)、離線強化學習(GCIVL、GCIQL)等方法展開對比。
在二維導航任務中,智能體需要從一個房間穿過唯一的門,導航至另一個房間的指定目標位置,考驗 AI 的路徑規劃和環境感知能力。LeWM 在該任務中雖略遜於傳統方法,但其潛特徵仍能精準捕捉智能體的位置信息,後續研究證實,這一表現差異並非源於特徵學習不足,而是簡單環境的內在維度與 SIGReg 的正則化要求存在適配性問題,並非模型本身的性能缺陷。
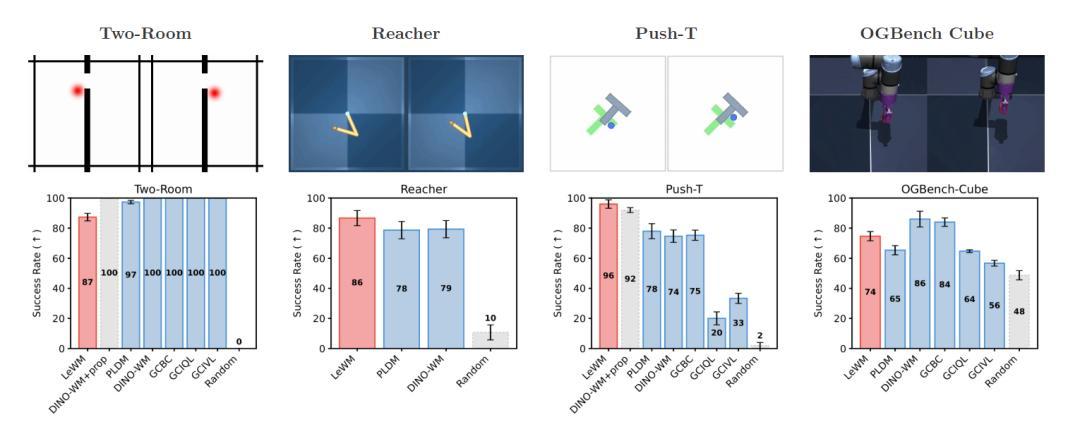
圖 | LeWM 在不同任務測試中的表現(來源:上述論文)
在推方塊任務中,LeWM 實現了性能突破,成功率比主流端到端方法 PLDM 高出 18%,更關鍵的是,僅依靠純像素輸入的 LeWM,性能竟超越了額外融合機器人本體感受信息(關節狀態、運動數據)的 DINO-WM,充分證明其能從純視覺畫面中,精準捕捉到任務所需的全部關鍵規律,無需額外信息輔助。
除此之外,LeWM 的規劃效率更是實現了質的飛躍。因爲模型輕、特徵簡單,LeWM 做決策規劃的速度,最高是傳統大模型方法的 48 倍,單次規劃不到 1 秒,不同任務、不同環境下速度都很穩定。
同時,LeWM 的訓練穩定性遠超傳統方法:傳統 PLDM 的訓練曲線波動劇烈,像“坐過山車”,而 LeWM 的訓練曲線平滑單調收斂,預測損失穩步下降,SIGReg 損失在訓練初期快速下降後趨於平穩,且不同隨機種子下的訓練結果方差極小,可復現性大幅提升,徹底解決了傳統方法“一次成功、次次翻車”的問題。
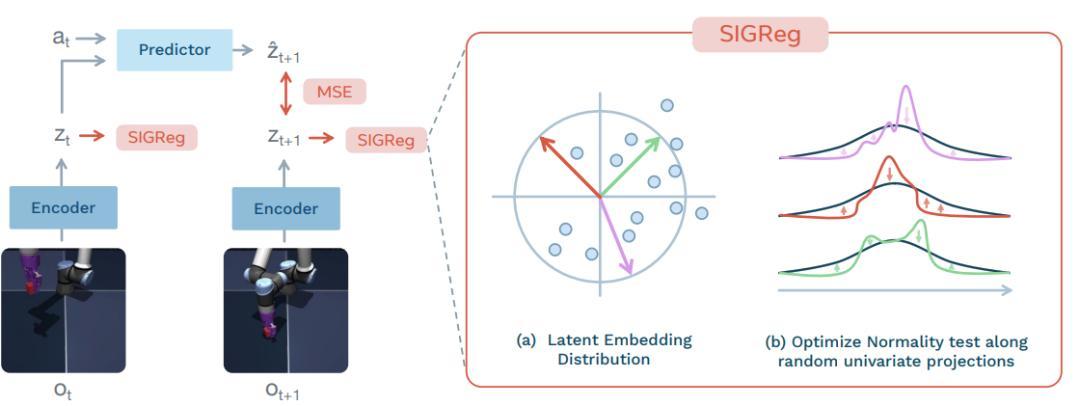
圖 | LeWM 訓練路徑(來源:上述論文)
最厲害的是,LeWM 造的 “模擬器”,不是單純靠死記硬背數據,而是真的學懂了物理世界的規律。
實驗中,研究人員能從 LeWM 的核心特徵裏,精準提取出物體位置、角度、速度這些物理量,精度比傳統方法高很多;更有趣的是,給 LeWM 看三種視頻:物體正常運動、物體顏色突然變了、物體突然瞬移(違反物理規律),LeWM 對瞬移會表現出明顯的驚訝(預測誤差驟增),對顏色變化卻幾乎沒反應。這說明它能分清“只是外觀變了”和“物理規律被打破了”,真正理解了世界的運行邏輯,而不是隻記得畫面的表面特徵。
當然,目前 LeWM 還有一些小短板:比如現在只能做短期的決策規劃,規劃太久會積累誤差;在特別簡單的環境裏,部分訓練規則的效果會打折扣;訓練時還需要明確的“動作標籤”,比如“推方塊”要標註出推的方向和力度。
針對這些問題,研究團隊也指出了未來的改進方向,比如把長任務拆成短任務實現長期規劃、讓模型從海量自然視頻裏學通用物理規律、讓模型自己從畫面裏學動作,不用額外標註。
參考鏈接:
1.https://arxiv.org/pdf/2603.19312
運營/排版:何晨龍



