來源:市場資訊
(來源:極客公園)

性能、開源、性價比,千問 3.5 全都要。
作者|Cynthia
編輯|鄭玄
大模型行業走到 2026 年,所有人都陷入了集體焦慮。
Scaling Law 的紅利徹底見頂,萬億參數模型繼續向上的邊際收益無限趨近於零,行業陷入了參數越卷越高,落地越來越難的死循環;
閉源巨頭牢牢把持着性能天花板,GPT、Claude 的 API 定價一漲再漲,頂級模型的使用成本,成了中小企業和開發者邁不過去的門檻。
開源模型始終跳不出性能追平閉源,就閉源收割;想要極致性價比,就要犧牲性能的怪圈。
久而久之,行業形成了一條無人敢質疑的鐵律:頂級性能、完全開源、極致性價比,構成了大模型的不可能三角,三者最多選其二。
於是,一到年底,國內外的萬億參數模型就一個接一個發佈,但普通企業是否用得上所謂的 SOTA 模型,卻不在考慮範圍。半年多時間,GPT、Claude 的定價也一漲再漲,哪怕作爲頂級牛馬的程序員,也需要公司報銷,才用得起頂配 200 美金一月的 cursor 與 claude code。

直到,除夕當天阿里千問 Qwen3.5 的發佈。
千問 3.5 總參數量僅 3970 億,激活參數更是隻有 170 億,不到上一代萬億參數模型 Qwen3-Max 的四分之一,性能大幅提升、還順帶實現了原生多模態能力的代際躍遷。
而橫向對比同行,千問 3.5 不僅是當下的開源大模型 SOTA,同時也在認知能力、指令遵循、通用 Agent 評測等方面超越了 GPT5.2、Claude 4.5、Gemini-3-Pro 等同期閉源模型。
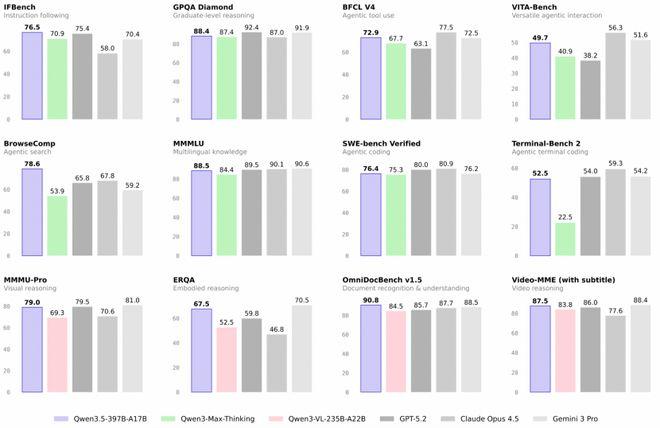
但成本上,千問 3.5 也做到了每百萬 Token 輸入低至 0.8 元,是 GPT5.2 的 1/15、Gemini-3-pro 的 1/18。
那麼,千問究竟如何做到的?答案藏在大模型的第一性原理中。
01
回到第一性原理,
千問 3.5 如何打破不可能三角?
大模型的第一性原理是什麼?
過去三年,答案或許是 Scaling Law。包括上一代 Qwen3-Max,也是阿里是用 36T tokens 的海量預訓練數據訓練出的暴力美學的成果。
但時至今日,Scaling Law 攀升的代價,已經到了行業難以承受的臨界點。緊隨其後,架構創新成爲新的行業關鍵詞。
剝掉所有參數、算力、跑分的外衣,所有大模型的底層核心,都是 Transformer 架構的attention 注意力 + FFN 前饋網絡雙塔結構:前者決定了模型的理解能力,後者決定了模型的表達能力。而這兩者,也是當前技術紅利最集中的突破點。
先看決定理解能力的 attention 層。
一直以來,大模型長上下文落地的最大瓶頸,從來不是窗口能開多大,而是算力成本和性能的平衡。
傳統 Transformer 的全局注意力機制,計算複雜度與上下文長度呈O (N²) 關係。翻譯過來就是,上下文長度翻 10 倍,算力需求就要翻 100 倍。這就是爲什麼行業裏很多模型號稱能支持百萬 token 上下文,卻根本不敢開放商用:成本高到用戶用不起,強行降價就要虧到吐血。
爲了解決這個問題,行業做了無數嘗試:線性注意力把複雜度降到了 O (N),卻損失了長文本的推理精度;稀疏注意力只計算部分 token 的注意力,卻無法解決全局語義依賴的問題,泛化能力大幅縮水。
而 千問 3.5 的解法,更像是人類思維模式在大模型上的遷移:既然人對不同事情可以有精力分配的不同,那麼對大模型來說,也不是所有 token,都配得上同等的全局注意力。
基於這個最樸素的原理,千問團隊打造了全局注意力 + 線性注意力的混合架構:
對非關鍵的冗餘信息,採用線性注意力處理,把計算複雜度從 O (N²) 直接砍到 O (N),算力消耗呈指數級下降;
對核心語義、關鍵邏輯信息,保留標準全局注意力,保證模型的長文本依賴建模能力,推理精度幾乎零損失。
這一改動,使得大模型在大幅減少算力消耗的同時,提升了輸出的效率,並帶來上下文窗口的大幅增加——千問 3.5 的上下文長度已經達到 1M token。約等於把劉慈欣的三體三部曲一起塞給模型,或者在每輪對話 500 字上下的基礎上,支持 600~800 輪連續對話不遺忘。
如果說混合注意力解決了理解效率的問題,那麼極致稀疏 MoE 架構,就解決了表達成本的痛點。
傳統稠密大模型,架構出場天生就帶着極致的浪費:不管你輸入的是一句早上好,還是一篇十萬字的行業報告,模型每次推理都要激活全部參數。
這就意味着,90% 以上的算力,都被白白浪費了。
MoE 混合專家架構的出現,就是把模型拆成多個專家子網絡,內容進來,只激活最對口的那幾個專家模型,不用全量參數跑一遍。
但行業裏絕大多數的 MoE 模型,都陷入了兩個死穴:要麼專家路由效率低下,激活參數佔比過高,成本下降有限;要麼專家之間的協同能力不足,模型性能出現滑坡。
而 千問 3.5 的極致稀疏 MoE 架構,直接把這個路線的潛力榨到了極致:總參數量 3970 億,單次推理的激活參數僅 170 億,不到總參數的 5%,即可調動全部知識儲備,順便實現部署成本大降 60%,最大推理吞吐量可提升至 19 倍,
到這裏,可能又有很多人會問,同樣是混合注意力、MoE 架構,爲什麼只有千問能做到這個程度?
答案是,架構創新的潛力,必須靠全棧協同才能徹底釋放。阿里獨有的阿里雲、平頭哥自研芯片與千問模型全棧協同能力,是其他廠商根本無法復刻的核心壁壘。
其中,阿里雲的 AI 基礎設施,爲 文本 + 視覺混合預訓練數據,提供了穩定、高效的算力支撐,讓大規模的架構創新實驗得以落地。
平頭哥真武 810 芯片,針對 MoE 架構、混合注意力機制做了專項優化,能充分發揮集羣算力效率,進一步把模型訓練和推理的效率拉到極致。
千問團隊的模型架構創新,又反過來給雲基礎設施、芯片的優化指明瞭方向,形成了正向循環的閉環。
也正是這套閉環,讓千問 3.5 的價格能進一步探底,把 API 成本壓到 0.8 元/百萬 Token,徹底打破了國外模型的價格壟斷,讓 sota 模型成爲人人可用,阿里雲上用的成本還能更低的普惠存在,也讓不可能三角成爲可能。
02
千問 3.5,全民友好型模型如何練成的?
很多人會問:千問 3.5 把成本打下來,是不是就會犧牲了推理性能?
恰恰相反,千問 3.5 最亮眼的地方就在於,它實現極致性價比的同時,也把性能和體驗,拉到了行業的新高度。
對普通用戶來說,最直觀的體驗升級,就是即使用 sota 模型,也能享受流暢的生成體驗。
過去,爲了給模型生成提速,大部分團隊都是在推理階段加個投機採樣的補丁,先猜後面的內容,猜對了就快一點,猜錯了就回滾,結果就是要麼快但容易錯,要麼準但還是慢。
而千問 3.5 的解法,是從訓練階段就原生支持多 Token 聯合預測,讓模型從一個字一個字地想,進化成一次想好幾步再說。這個過程類似於人類說話,先想好完整的語義,然後在表達的過程中組織連貫的語言。
這對長文本生成、代碼補全、多輪對話等高頻場景帶來的是質變的體驗升級:問一個複雜的科普問題,10 秒內就能給出連貫的回答;寫一篇千字短文,幾秒就能生成初稿。
另一個被徹底解決的痛點,是大模型的上下文腐爛問題。
過去,大模型輸入上下文越長,就會讓模型的注意力越分散,有效信息被無效噪聲淹沒,輸出質量直線下降。一個完整的長內容,模型往往只會注意到開頭和結尾的內容,中間的關鍵信息被忽略,或者多輪對話之後,它會忘記你最初的問題或者要求。
針對這個痛點,Qwen3.5 對模型做了系統級的訓練穩定性優化,其中最核心的,就是阿里千問團隊斬獲NeurIPS 2025 最佳論文獎的注意力門控機制。
這個機制,本質上是在注意力層的輸出端,加了一個智能降噪開關:它能根據信息的重要程度,智能調控信息的傳遞,有效信息被放大,無效信息被過濾。
最終的結果是,哪怕是在 1M token 的超長上下文下,模型依然能精準記住所有的關鍵信息,開發者不用再把長文檔拆成十幾段反覆投餵,用戶不用再把需求翻來覆去重複三遍,百萬級上下文的全量信息精準調用,終於成爲了現實。
除了這些核心痛點的解決,千問 3.5 的細節升級,覆蓋了從個人用戶到企業開發者的全維度需求。
比如,它首次把支持的語言擴展到了 201 種,預訓練數據裏大幅新增了中英文、多語言、STEM 和推理類數據,不管是小語種的精準翻譯,還是複雜的數理化博士級難題,都能輕鬆應對。
測試案例:STEM 表現
在 Agent 能力上,千問 3.5 同樣實現了生產級的跨越式提升。目前,千問 3.5 在移動端已經與多個主流 APP 與指令打通,PC 端則能處理跨應用數據整理、自動化流程執行等複雜多步驟操作。
更關鍵的是,千問團隊構建了可擴展的 Agent 異步強化學習框架,端到端速度可加速 3 到 5 倍,並將基於插件的智能體支持擴展至百萬級規模,爲後續 Agent 的規模化落地打下了基礎。
如果說其他模型,還停留在開發者友好型,那麼千問 3.5,就是全民友好型。它既照顧了開發者對成本、效率的需求,也兼顧了普通用戶對體驗的期待,讓大模型真正走進了日常生活,而不是停留在實驗室裏的黑科技。
03
原生多模態,
千問 3.5 開始能讀懂複雜世界
如果說性能、成本、體驗的全面升級,是千問 3.5 在解決當下大模型落地過程中的困境,那麼統一多模態,就是 千問 3.5 把大模型推向 AGI 的重要一步探索。
長期以來,業界都有一個共識:統一多模態,是通往通用人工智能(AGI)的必經之路。但直到今天,行業裏絕大多數的多模態模型,都還是僞多模態:先訓好一個純語言大模型,再外掛一個視覺編碼器,靠適配層把兩個模塊粘在一起,本質上就是兩個語言不通的人靠翻譯聊天,信息傳遞必然出現折損。
千問 3.5 的不同之處在於,從預訓練第一天起,就是在文本+視覺混合數據上聯合學習,讓視覺與語言在統一的參數空間內深度融合。
簡單說,它看到一張圖,就能自然理解圖中的語義,不用先把圖像轉換成文本再進行理解;讀到一段文字,就能在腦中構建出對應的畫面,就像人一樣,真正具備了跨模態的直覺理解力。
測試案例:輸入一張電影截圖,千問 3.5 就能生成圖文並茂的電影解析
爲了實現這種原生的多模態融合,千問 3.5 對整個訓練架構都做了革新:它讓視覺和語言模態,各走各的最優路徑,只在關鍵節點上高效匯合,既保證了兩個模態各自的性能上限,又實現了真正的協同工作,大幅提升了多模態混合訓練的效率。
這種原生融合的架構,帶來的是視覺能力的飛躍式提升:在多模態推理(MathVison)、通用視覺問答 VQA(RealWorldQA)、文本識別和文件理解(CC_OCR)、空間智能(RefCOCO-avg)、視頻理解(MLVU)等衆多權威評測中,Qwen3.5 均斬獲最佳性能,碾壓同類開源模型,甚至比肩頂級閉源模型。
測試案例:通用視覺問答
還有一個容易被忽略,卻至關重要的細節優化,是精度策略的設計:千問 3.5 採用了 FP8/FP32 的精度策略,在保證模型性能零損失的前提下,把激活內存減少了約 50%,訓練速度提升了 10%。更關鍵的是,這套方案被統一部署到了強化學習訓練和推理的全流程裏,全面降低了多模態模型擴展的成本和複雜度。
這些性能提升,最終都轉化成了實實在在的生產力:
在學科解題、空間推理上,它比千問此前的專項多模態模型 Qwen3-VL 表現還要更優,空間定位、帶圖推理的精度大幅提升。
在視頻理解上,它支持長達 2 小時的視頻直接輸入,剛好對應 1M token 的上下文窗口,會議錄像、課程視頻、直播素材,一次性投餵就能完成核心內容提取、腳本生成、待辦梳理。
通過視覺與代碼的原生融合,手繪的 APP 界面草圖,也能直接轉化爲可運行的前端代碼;機械圖紙、建築結構圖、幾何題目,全都能精準拆解空間關係、完成推理計算。
測試案例:複雜網頁生成
而這,也是讓大模型從能聊天的工具,變成看懂現實世界的基座,最終通往 AGI 乃至 ASI 的關鍵一步。
04
尾聲
如果說架構與多模態的創新,讓 千問 3.5 打破了不可能三角的技術枷鎖,那麼開源生態,讓千問 3.5 徹底顛覆了行業對開源模型的固有偏見。
在此之前,開源模型在行業裏的定位,永遠是閉源模型的替代品:性能追不上閉源,體驗打不過閉源,只能作爲開發者的練手工具,無法進入核心生產環境。
現在千問 3.5 的問世,徹底打破了這種偏見——它用開源的身份,實現了超越同級閉源模型的性能,再加上極致的性價比和完善的生態支持,讓開源、高性價比、最強的不可能三角成爲可能。
一組可驗證的數據,足以證明千問開源生態的行業影響力:截至目前,阿里已開源 400 餘個千問模型,覆蓋全尺寸、全模態、全場景,全球下載量突破 10 億次;全球開發者基於千問開發的衍生模型超 20 萬個。
而站在千問生態的肩膀上,中小企業不用再爲頂級模型的 API 支付高昂的費用,用極低的成本就能落地自己的 AI 應用;
個人開發者不用再被閉源模型的商用權限鎖死,基於開源的千問 3.5,就能打造創新的 AI 產品;
科研機構不用再重複造輪子,基於開源的底座,就能專注於前沿技術的創新。
從此,AI 不再是巨頭的專屬遊戲,而是變成了全行業、全開發者都能參與的創新浪潮。
*頭圖來源:視覺中國
本文爲極客公園原創文章,轉載請聯繫極客君微信 geekparkGO
極客一問
你如何看待千問 3.5 ?
黃仁勳:我從來都不帶手錶,我習慣於等事情自然發生。
點贊關注極客公園視頻號,