

“在一次長談中,導師向我描繪了未來科研的場景:將來科學家只需拋出假設,背後成百上千個 AI Agents 會在幾分鐘內設計並完成實驗。要想抵達那個未來,首先得有一把可靠的‘尺子’去衡量大模型能否把一個研究想法成功轉化爲實驗代碼,而這便是我們做 Benchmark——ResearchCodeBench的初衷。”近日,美國斯坦福大學博士生華天羽告訴 DeepTech。

圖 | 華天羽(來源:華天羽)
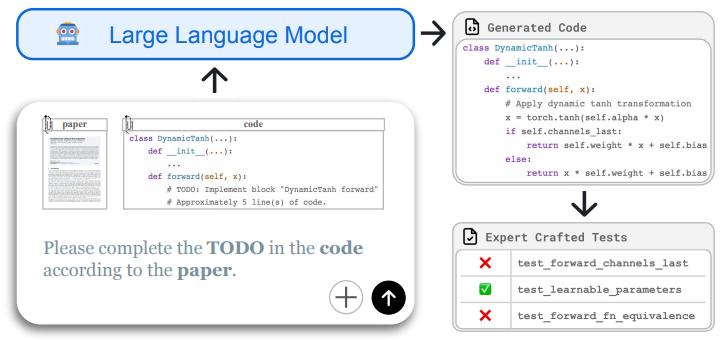
在這項研究中,華天羽等人先是打造了一個開源基準庫,其中包含 20 篇最新論文和 212 道代碼題,每道題都附有可跑的測試。跑完一套,立刻可知道模型在真正的“科研級編程”場景下到底有“幾斤幾兩”。
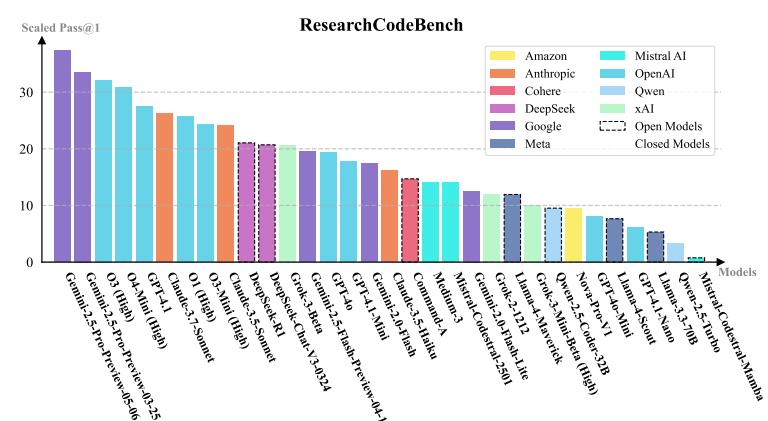
其次,他們收穫了兩個實驗發現。第一個發現是 SOTA 也難以及格,期間研究團隊測試了 32 個大模型,最好成績(Gemini-2.5‐Pro-Preview)也只通過 37.3% 的可執行行數,OpenAI O3(High)通過了 32.3% 的可執行行數,Claude 3.5 Sonnet 則更低。由此可見,讓模型學會“讀論文”很有必要:當將論文全文給到模型,它的通過率能夠顯著提升;當拿走論文、只提供代碼上下文的時候,模型性能普遍下滑。第二個發現是他們繪製出了一份錯誤分佈畫像,即近六成模型做科研編程的失敗原因是由於“語義/邏輯錯誤”,而語法錯誤和命名類錯誤已不再是主要瓶頸。
就應用前景來說:
首先,可作爲模型迭代的“驗收標準”:大模型公司可以把 ResearchCodeBench 當作迴歸測試,查看新版本大模型在科研場景到底有沒有真正取得進步。
其次,可作爲科研助手的對標基線:未來如果有人做“自動復現論文”的 AI Agent,就能拿 ResearchCodeBench 做公開橫評。
最後,可以延伸到跨學科:由於本次框架是通用的,因此後續可以加入生物、材料、量化金融等領域代碼,成爲更全面的“科學編程測評池”。
(來源:arXiv)
談及研究背景,華天羽表示過去兩年大家都在談“AI + 科研”,但是可落地的量化評測一直缺位。已有的代碼類基準比如 HumanEval、MBPP 等更像是編程題庫,它們測試的是常見算法。而科學研究的痛點是“實現沒見過的新想法”,這就需要大模型一邊讀論文、一邊寫出能跑通的實驗代碼。因此,研究團隊想知道“大模型到底能不能真正幫科研人員把最新論文裏的點子寫成可執行的代碼”。
於是,研究團隊提出了 ResearchCodeBench——把 20 篇 2024 年至 2025 年的頂會論文和預印本論文拆成 212 個“填空式”代碼挑戰,並配上單元測試。這樣做的目的只有一個:衡量大模型在真正“前沿場景”中的編程實力,而非僅僅只是背代碼。基於此,他們開展了本次研究。
(來源:arXiv)
據介紹,本次課題立項於 2024 年盛夏。當時,華天羽剛加入目前所在的課題組。不過,彼時他並不理解導師拋出的“代碼生成”命題。如前所述,他後來聽到了導師向他描繪的未來科研場景,於是便理解了這一命題。
2024 年初秋,課題進入需求拆解與打造技術路線的階段。由於資源有限,華天羽自己訓練頂級模型根本不現實,於是他和所在團隊把重點放在“考題”本身,
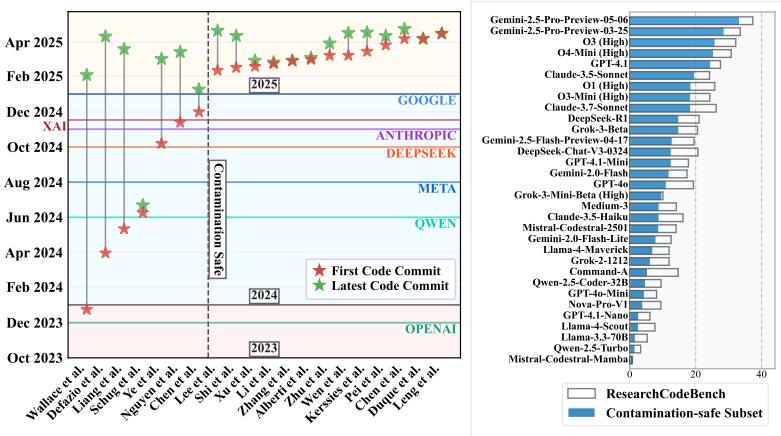
據瞭解,此次研究只選用 2024 年之後的新論文,以便確保模型在接受預訓練時沒有見過這些內容。同時,還得確保每道題都必須能夠執行和能夠自動判分,而且評測一定要快,確保普通筆記本在幾秒內就能給出結果。
2024 年深秋至初冬,華天羽開始進行指標實驗。期間,他和所在團隊嘗試了編輯距離、代碼向量距離、大模型評分等五六種度量方式,最後發現最可靠的方式居然是最笨的方式——即把模型生成的代碼塞回原項目,通過跑單項測試來查看結果。爲了“偷懶”,他花費了三個月時間“搗鼓”,目的就是想讓大模型自動寫這些測試,然而最終卻以失敗告終。“確實,在那個時候,複雜的科研代碼的測試用例還必須人工編寫。”華天羽表示。
隨後,他開始進行數據落地,從 20 篇頂會論文和 arXiv 預印本論文中進行“抽核心實現”和“埋 XML 標籤”等操作,然後手寫了 212 份單元測試。“找外包是不行的,因爲要看懂研究級別的代碼的門檻太高,只能我和同門硬啃。”他說。其中,最大的挑戰便是“剪枝”:要讓每道題既能反映論文亮點,又不牽出一大堆依賴鏈。
完成數據落地之後,開始進入大模型統測階段。期間,華天羽連續兩個月和 32 個長上下文模型較勁,面對不同 API 的上下文限制、速率限制和沙盒依賴,都要逐一地打補丁。最終,他得出了首批分數,儘管最好的分數也只過了僅僅不到 40 % 的行數,但這已經足夠爲科研社區拉出清晰的基線。
然後,他開始整理實驗、補做污染分析,並寫好了腳本和網頁表單,實現了讓任何人都能“一鍵提交論文、一鍵跑分”。
(來源:arXiv)
事實上,期間他曾因爲尋求幫助而喫閉門羹。爲了尋找合作伙伴協助標註,他和所在團隊逐一發郵件聯繫,但是大約一半的郵件都沒有收到回覆。“這逼得我快速改進溝通方式,把郵件主題精簡成一句話、正文先提供具體技術反饋,然後再說明合作需求,於是回信率明顯提升。”他表示。通過此,他不僅獲得了所需要的幫助,也練出了更主動、更直接的溝通習慣。
另據悉,Benchmark 最初叫 Paper2Code,上線之前他發現領域內已經有同名項目。於是,整個團隊商量着緊急“改名”,列出數十個候選之後逐一進行查重和討論,最終他們採用了 ResearchCodeBench 這一命名,該命名不僅含義清晰、不撞名,而且縮寫比較好記。
在後續計劃上:首先,他將進行半自動生成測試,現在大模型的代碼能力肉眼可見地提升,因爲他將在下一版中嘗試“模型 A 寫單測、模型 B 審覈、人類抽樣”,把新增題目的人力成本壓到數分鐘以內。其次,他將進行跨學科擴容,計劃在 2025 年之內再引入至少 40 篇生物、材料、量化金融等領域的新論文,讓基準覆蓋更廣。再次,他將開展 Agent-style 評測,即從“一次性填空”升級到“多輪 run-debug-refine”,以便更加貼近真實的科研工作流。另外,他將設置人類基線,通過邀請博士後和高級工程師在子集上手寫實現,記錄耗時與正確率,給出“人類上限”對照。最後,他將致力於實時 Live-Bench,即在每個月度裏進行新論文抓取,只要時間戳晚於主流模型的訓練截止,就自動進“新手村”子集,確保始終測試新題目,防止模型背答案。
據介紹,華天羽本科學習於中國地質大學(北京)。畢業時正逢疫情爆發,隨後在上海期智研究院工作了一年。之後,華天羽前往英屬哥倫比亞大學攻讀碩士。讀博時,他更希望與“人好、氛圍好”的導師長期合作。美國斯坦福大學 CS 系第一年需輪轉,可以到不同實驗室體驗。最終,華天羽選擇了現在的課題組,雖已不再專注於自己原先熟悉的計算機視覺方向,但導師的口碑和科研文化讓華天羽決定留下。比如,課題組之前做過一些 human cognition inspired AI 的研究,再比如課題組在三年前就有同學在做推理機制(reasoning)研究,而華天羽對這些帶有人文味道的科研項目很感興趣。
據瞭解,他對於 AI 與人類認知的興趣可以追溯到高中:當時填報志願時,華天羽直接問“哪個專業以後能做 AI?”,於是選擇了計算機。正好趕上深度學習崛起,雖然那時中文互聯網每年都在討論“算法崗秋招有多難”,但是華天羽仍然一路靠做 AI 研究“喫飯”走到今天。目前,他正在讀博士二年級,預計還有很多“AI 之山”等着這名無錫男孩去攀登。
參考資料:
Benchmark: https://researchcodebench.github.io
Paper: https://arxiv.org/abs/2506.02314
Code: https://github.com/PatrickHua/ResearchCodeBench
運營/排版:何晨龍



