Next Gen
歡迎來到“Next Gen”。人工智能的邊界每日都在被拓展,一羣富有遠見卓識的青年學者正站在浪潮之巔。我們追蹤並報道這些 AI 領域最具潛力的明日之星,展現他們在科研前沿的突破性工作,以及對未來智能時代的獨到見解。他們是誰?他們如何思考?他們又將把 AI 帶向何方?與我們一同發現那些正在定義未來的 AI 新生代。
在生成式 AI 發展進程中,效率瓶頸正逐漸成爲技術落地的關鍵阻礙。以 ChatGPT 爲例,當面臨複雜對話任務、高併發訪問場景時,響應常出現秒級等待;而訓練大型 AI 模型的能耗同樣驚人,部分規模堪比 GPT- 3 的模型,訓練產生的碳排放甚至相當於數百輛汽車的年排放量。這類效率與能耗問題,正從用戶體驗、成本投入等維度,對生成式 AI 的廣泛落地形成現實制約。
孫鵬是西湖大學與浙江大學聯合培養博士生,他與所在團隊的研究爲解決上述問題提供了新的解決方案——其提出的 UCGM(Unified Continuous Generative Models)框架,讓 AI 模型生成速度提升數十倍,而 RDED(Realistic and Diverse Dataset Distillation)數據蒸餾技術則實現了“用 1% 數據達到 90% 效果”的突破。
從數據壓縮到生成式 AI,他的研究軌跡始終瞄準 AI 產業最迫切的痛點,爲 6G 通信、自動駕駛等前沿領域劈開一條“高效 + 低耗”的技術路徑。

圖丨孫鵬(來源:孫鵬)

像“放大器”一樣提升模型訓練效果
西湖大學與浙江大學團隊合作,提出了一個統一的連續空間生成框架 UCGM,實現了模型統一的訓練、採樣和理解。
孫鵬向 DeepTech 解釋道:“UCGM 框架的最大價值在於統一性,它將分散的算法和理論整合到一個完整的體系中,爲我們提供了更宏觀的研究視角,這不僅有助於系統梳理現有算法,更爲更爲後續創新奠定了堅實基礎。”
在對連續空間生成模型的傳統研究模式中,不同生成範式的算法和理論往往相互割裂,甚至不同研究者對於同一個生成範式的理論理解角度不同,進一步導致可能採用個性化的算法框架和代碼實現習慣。
這種碎片化狀態使得後續研究者需要耗費大量時間來學習各種生成範式和適應不同實現方式,無形中增加了學習成本。而 UCGM 框架通過建立統一的理論,算法和代碼範式,顯著降低了這一隱性成本。
更重要的是,UCGM 框架的高層次理論視角還催生了創新的增強技術。這些技術如同“放大器”一般,可以無縫集成到統一框架中。
與傳統獨立框架下的增強技術不同,後者往往侷限於特定場景,而 UCGM 的“大一統”特性使得新開發的增強技術能夠自然地推廣到既有框架中,實現技術成果的快速傳播和應用。這種機制不僅提高了技術複用效率,還顯著提升了模型的訓練效果,爲生成式 AI 的性能優化開闢了新路徑。
UCGM 框架包含兩個關鍵部分:UCGM-T(統一訓練器)和 UCGM-S(統一採樣器),它的設計理念體現了雙重優化目標:從用戶體驗維度,它致力於減少生成延遲;從企業運營維度,它着眼於降低計算資源消耗和能源成本。目前研究團隊基於 0.675 億參數的中等規模模型驗證了核心思想,研究重點集中在減少生成步驟(如將傳統需要的 100 步生成縮減至 1-2 步)的同時,維持或提升生成質量。

圖丨使用 UCGM 在 ImageNet-1K 512×512 數據集上訓練的兩個 0.675 億參數擴散變換器模型生成的樣本(來源:arXiv)
以 256×256 分辨率的 ImageNet 數據集爲例,研究團隊採用一個包含 0.675 億參數的擴散變換器模型進行驗證:UCGM-T 訓練的多步模型在 20 個採樣步驟下實現了 1.30 的 FID(Frechet Inception Distance)值,而其訓練的少步模型僅需 2 個採樣步驟就能達到 1.42 的 FID。
更值得注意的是,當將 UCGM-S 應用於既有預訓練模型時,該技術在不增加任何計算成本的情況下,將模型的 FID 從原始 250 步採樣時的 1.26 顯著提升至僅需 40 步採樣時的 1.06。這些實驗結果表明,UCGM 爲高分辨率圖像生成這一計算密集型任務提供了高效的技術解決方案。
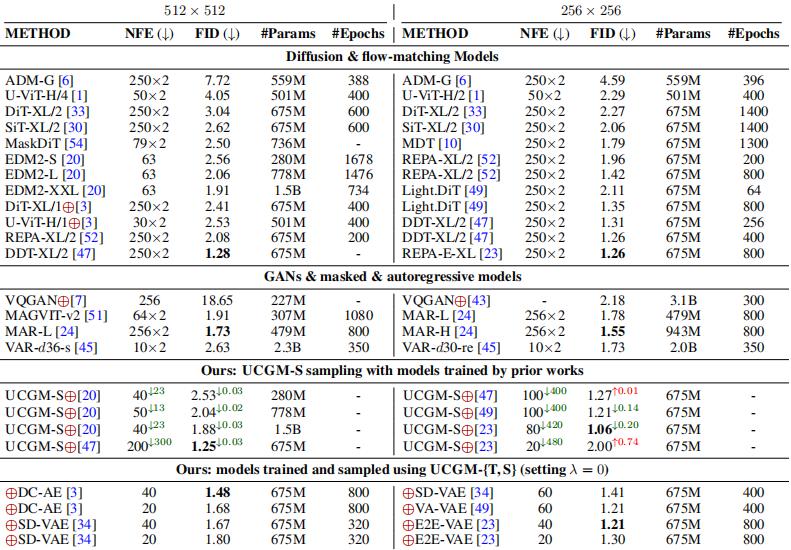
圖丨在類別條件 ImageNet-1K 數據集上進行的多步生成任務的系統級質量比較(來源:arXiv)
高分辨率圖像生成作爲計算機視覺領域的公認挑戰,常被用作驗證算法性能的基準任務,但 UCGM 的應用潛力遠不止於此。從理論層面看,該框架提出的核心思想具有普適性,其設計理念有望拓展到矢量圖生成,音頻和信號生成,乃至文本生成等多個領域。
該技術展現出直接應用的潛力,以當前工業界常見的文生圖模型爲例,採用 UCGM 框架可以顯著提升圖像生成速度。更重要的是,作爲基礎理論框架,UCGM 具有更廣泛的應用前景——通過將支持的數據類型從圖像擴展到文本等多個模態的數據,該框架同樣可以加速多模態模型的生成效率。
日前,相關論文以《統一連續生成模型》(Unified Continuous Generative Models)爲題發表在預印本網站 arXiv[1]。孫鵬是第一作者,西湖大學林濤助理教授擔任通訊作者。

圖丨相關論文(來源:arXiv)

僅需 7 分鐘即可蒸餾出每類 10 張圖像的核心子集
在當下“數據爲王”的人工智能時代,高質量數據是訓練強大模型的基礎,然而其收集、整理過程不僅成本高昂,還涉及用戶隱私問題,甚至可能需要付費獲取,使得數據本身成爲一種珍貴資源。
從模型訓練的實際需求出發,處理這些珍貴且規模龐大的數據集需要消耗巨大的算力成本。因此,數據集蒸餾(Dataset Distillation)應運而生,其能夠有效“輕量化”訓練數據及大幅提升訓練效率。
當前,整個深度學習領域對數據的依賴日益加深,對高質量、高效率數據的需求空前顯著。回顧發展歷程,數據蒸餾在四五年前尚屬小衆研究方向,然而,隨着近兩年依賴海量數據訓練的超大規模模型呈現井噴式發展,其核心價值才被真正廣泛認知。當巨量的高質量數據成爲各領域 AI 應用的關鍵驅動力時,高效的數據集蒸餾技術變得越來越重要且極具推廣價值。
孫鵬在早期便敏銳地關注到數據集蒸餾的價值,但他同時發現,當時最先進的方法存在一個顯著的悖論:壓縮數據集的初衷是減輕模型訓練的代價(例如將原本需要 1 天的訓練縮短至 4 小時),然而壓縮過程本身可能耗時冗長(例如長達 2 天),這極大地削弱了其實際應用價值。
爲了突破這一瓶頸,他及其所在團隊提出了一種名爲 RDED 的新型高效數據集蒸餾方法。RDED 的核心優勢在於能夠在顯著提升計算效率的同時,嚴格保持所蒸餾數據的多樣性和真實性。
其性能表現卓越:例如,在 ImageNet-1K 數據集上,RDED 僅需 7 分鐘即可蒸餾出每類 10 張圖像的核心子集,並在後續模型訓練中達到 42% 的 Top-1 準確率。這一結果不僅性能達到當時最優方法的 2 倍,其蒸餾速度更是提升高達的 52 倍。
孫鵬指出,這項研究是領域內首篇真正實現“壓縮時間遠小於訓練時間”突破的論文。具體而言,假設原始數據集訓練需要的時間爲 a,RDED 完成壓縮數據集的時間爲 b,隨後利用壓縮的數據集進行訓練時間爲 c 就能達到與原始數據集訓練相當的性能,我們可以有 b+c 遠小於 a,即使得“壓縮+訓練”的總耗時顯著少於原始訓練時間,從根本上解決了前述悖論。
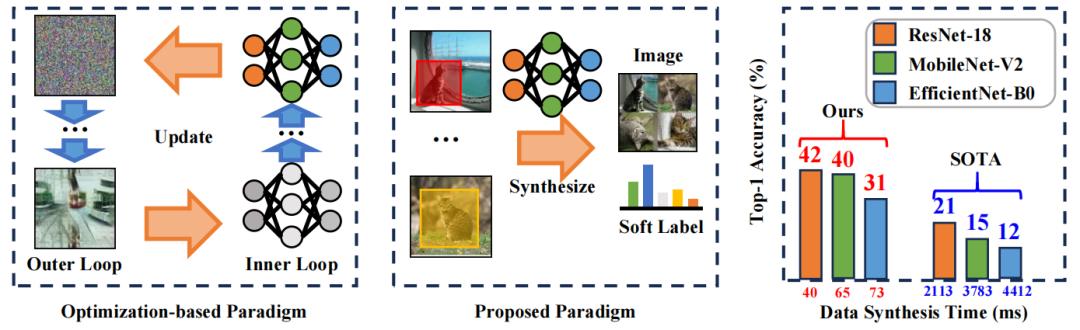
圖丨對比了提出的範式與基於優化的範式(來源:CVPR)
儘管 RDED 展現出巨大潛力,其當前的工業應用仍需結合前文所述的 UCGM 框架來發揮最大效能。這主要是因爲工業場景所需的數據類型通常極其複雜且具有高度針對性,而傳統數據集蒸餾技術主要聚焦於分類等特定任務,這與自動駕駛等實際應用中常見的多任務、場景化需求(如目標識別、場景理解)存在較大差異,導致直接應用面臨挑戰。
UCGM 框架爲解決此問題提供了關鍵橋樑:例如,在自動駕駛領域,可以首先利用 UCGM 強大的生成能力,高效地合成包含特定障礙物或罕見場景(如手持相機視角下疾駛而來的貨車)的高質量目標數據——這類數據在現實中極難獲取且收集成本或風險極高;隨後,再應用 RDED 技術對這些針對性生成的合成數據集進行高效壓縮和蒸餾。這種“生成-壓縮”的協同範式,有望爲工業界提供持續、高質量且高度定製化的數據流,更具實際應用前景。

圖丨使用不同數據集蒸餾方法合成的圖像可視化(來源:CVPR)
孫鵬指出,未來領域或將面臨一種新挑戰:算力和算法持續進步,速度越來越快,但真實有效的數據供給卻可能不足。究其根本,真正高質量的訓練數據源於人類活動或真實世界,其產生的速度存在物理上限。自動駕駛等領域難以收集的極端危險場景數據(如高速碰撞前瞬間)正是這種稀缺性的典型例證,這類數據對於安全算法(如緊急避險)又至關重要。
此時,結合 UCGM 框架按需生成高質量、高保真的特定場景數據,再通過 RDED 技術進行高效蒸餾和壓縮,形成一套完整的解決方案,或能夠爲工業界持續輸送定製化的高質量數據,有效應對未來可能出現的“數據荒”。
日前,相關論文以《論蒸餾數據集的多樣性與真實性:一種高效數據集蒸餾範式》(On the Diversity and Realism of Distilled Dataset:An Efficient Dataset Distillation Paradigm)爲題發表在 CVPR 2024 會議 [2]。孫鵬是第一作者,西湖大學林濤助理教授擔任通訊作者。

圖丨相關論文(來源:CVPR)

致力於創造真正“有益於未來”的技術
孫鵬的研究方向經歷了一個遷移的過程。在研究生涯早期,他聚焦於數據視角下的深度學習。然而,隨着研究的持續推進和深入,孫鵬逐漸認識到一個關鍵瓶頸:僅僅優化數據壓縮技術是不夠的。
他洞察到,如果高質量數據的產生長期且主要依賴人類活動,其生成速率必然存在根本性限制,未來極有可能遭遇數據供給短缺的挑戰。鑑於此,開發更高質量、更高效率的生成模型,尤其是能夠產出超越人類數據質量與效率的模型變得至關重要。
這一認識促使他的研究重心開始向深層人工智能,特別是生成式 AI 領域進行戰略性遷移。這一轉變也自然地塑造了他多元的研究風格,形成了兩條並行的主線:一條延續其在高效數據技術(如數據蒸餾)上的深耕;另一條則積極開拓生成式 AI 模型(如 UCGM 框架)的創新疆域。
回溯孫鵬投身科研的初心,其核心驅動力始終圍繞着解決實際需求:社會或人類究竟需要何種技術來推動文明進程?哪些技術能切實解決日常挑戰,加速文明發展?正是基於這種以實際問題爲導向的研究哲學,他最初敏銳地將目光投向了數據效率等關鍵領域。
談及研究方向的重要轉變,孫鵬坦言:“多數研究者並不輕易改變深耕的領域,例如從數據壓縮轉向生成式 AI 研究意味着巨大的沉沒成本和學習投入,需要深入掌握前沿領域的全新知識體系。”
但於他而言,研究的價值在於創造真正有益於未來、人類和社會的技術,只要方向符合這一目標,他都會堅定地選擇嘗試。未來,孫鵬的研究視野不會侷限於生成式 AI 領域,而是計劃探索人工智能的其他分支,甚至包括非深度學習的 AI 範式。但其目標始終如一:探尋更具潛力、能對人類未來生活產生實質性積極影響的技術場景,持續創造價值。
參考資料:
1.https://arxiv.org/abs/2505.07447
2.https://arxiv.org/abs/2312.03526
運營/排版:何晨龍、劉雅坤