

在半導體行業,設計一款領先的集成電路(IC)一直被視爲硬件工程的巔峯挑戰之一。通常情況下,從架構定義到最終流片(Tape-out),需要動輒數百人的工程團隊協作,研發生產週期長達 18 至 36 個月,投入數億美元。高昂的容錯成本使“一次性成功”成爲剛需,爲此,驗證環節甚至佔據了總工作量的 50% 以上。
然而,就在最近,芯片設計初創公司 Verkor 發佈的一項研究打破了這一常態。其開發的自主 AI 智能體——Design Conductor(簡稱 DC),僅憑一份219 字的自然語言需求文檔,在短短 12 小時內,便獨立完成了從微架構設計到可供流片的 GDSII(物理版圖數據)的全流程。由此誕生的 VerCore CPU,不僅主頻高達 1.48 GHz、具備運行 Linux 的能力,其性能更直逼 2011 年時期的主流商用處理器。這也是目前已知的首個由自主代理完整構建出的工作級CPU。

圖 | Verkor 團隊爲 DC 提供的需求文檔(來源:arXiv:2603.08716)
Design Conductor:半導體設計的“數字指揮官”
與簡單的代碼補全工具不同,Design Conductor 是一個具備長時程推理能力和複雜工具調用能力的自主代理系統。其核心架構旨在解決硬件工程中極爲嚴苛的功耗、性能、面積(PPA)多目標約束。在系統架構與基礎設施層面,爲應對電子設計自動化(EDA)極其密集的計算需求,DC 採用了雲端擴展架構。
其內部由多個關鍵模塊協同工作。首先是 LLM 推理引擎與上下文管理,DC 使用了尖端大語言模型作爲決策中樞;爲防止信息過載導致推理質量下降,系統又引入了上下文管理模塊,實時監控並優化跨併發會話的 Token 使用。
其次是跨迭代的自主內存系統承擔知識庫功能,負責存儲技術需求、代碼庫信息和設計規則。它確保智能體在長達 12 小時的任務中保持邏輯連續性。最後則是分佈式執行環境:智能體運行在裝有專業 EDA 工具的虛擬機或容器中,能夠直接編寫並運行 Verilog 代碼、執行邏輯仿真和物理合成。
DC 的工作模式模仿了傳統工程團隊的職能分工,通過多個子智能體(Subagents)執行鏈式流程,實現“多角色”協同的自動化工作流。其中設計規劃模塊負責分析用戶需求,生成微架構方案;邏輯實現與評審模塊可生成 Verilog RTL 代碼及配套測試平臺,通過設計評審智能體分析流水線衝突等潛在缺陷。接着,系統集成模塊隨即匯聚各個模塊,利用 RISC-V 標準指令集模擬器 Spike 進行全系統驗證。
此外,當測試失敗時,智能體還能自動解析 VCD(值變轉儲)文件並將其轉換爲 CSV 格式,對比硬件狀態與架構狀態,通過根因分析精準定位邏輯錯誤。最後,PPA 收斂是最關鍵的一步。智能體可根據後端工具生成的時序、功耗和麪積報告,迭代修改 RTL(如添加前推邏輯 Forwarding 或重構算術單元),直到滿足性能指標。
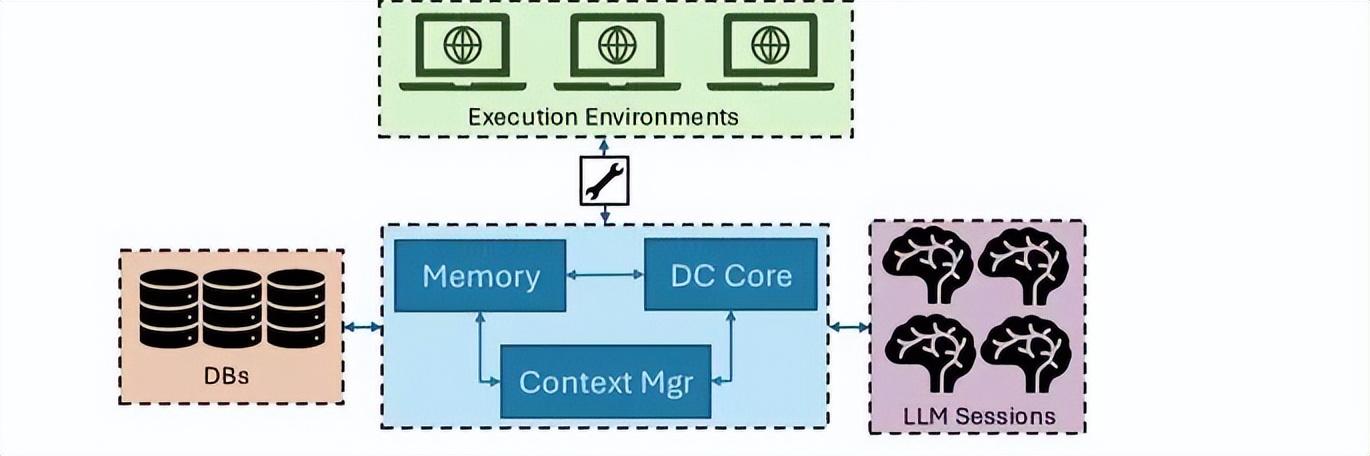
圖 | DC的設計指揮架構(來源:arXiv:2603.08716)
12小時的結晶:VerCore 處理器深度解析
爲驗證 DC 的實戰能力,Verkor 團隊設定了一個極具挑戰性的目標:在基於亞利桑那州立大學開發的 7nm 預測工藝設計包 ASAP7 工藝下,構建一款支持 Linux 的 RISC-V CPU。
在 12 小時內,DC 展現出令人驚歎的計算強度與工程精細度。項目運行週期內累計處理的 Token 流達到數十億量級,堪稱深層推理馬拉松。芯片設計對邏輯嚴密性的要求近乎苛刻,系統必須通過精密的上下文管理模塊,在長時程的會話中不斷同步技術規範與設計規則,確保智能體在處理龐大的 Verilog 代碼庫時不會因信息過載而產生邏輯幻覺。
這種跨越的底層支撐正是前文提到的那套高度自動化的“開發-驗證-修復”閉環體系。在編寫出支持 RV32I 基礎指令集與 ZMMUL 高性能乘法擴展的 RTL 代碼後,爲達到極限頻率,DC 智能體還經歷了多輪物理合成迭代,不斷調整邏輯深度與前推路徑。
在這種持續的反饋優化下,結果沒有令人失望。VerCore 最終成功在 1.48 GHz 的高頻下達成時序閉合,並以 2809 μm² 的極精簡面積(不含緩存)實現了 3261 分的 CoreMark 跑分。對比來看,這一性能水平與 2011 年中期的 Intel Celeron SU2300(雙核 1.2 GHz)相當,但考慮到其是在 12 小時內由 AI 獨立設計完成的,效率提升已達指數級。
在 VerCore 的開發過程中,DC 還展現出令人驚歎的硬件優化直覺。爲了達到 1.6 GHz 的預期目標,智能體在沒有明確人類指令的情況下,自主實施了包含早期分支解析(在解碼階段即進行分支處理以降低延遲)、前推邏輯(獨立解決數據相關性衝突)等在內的多項高級特性,還構建了一個平衡的 4 級 Booth-Wallace 乘法器。實驗顯示,該模塊在隔離狀態下主頻可飆升至 2.57 GHz。
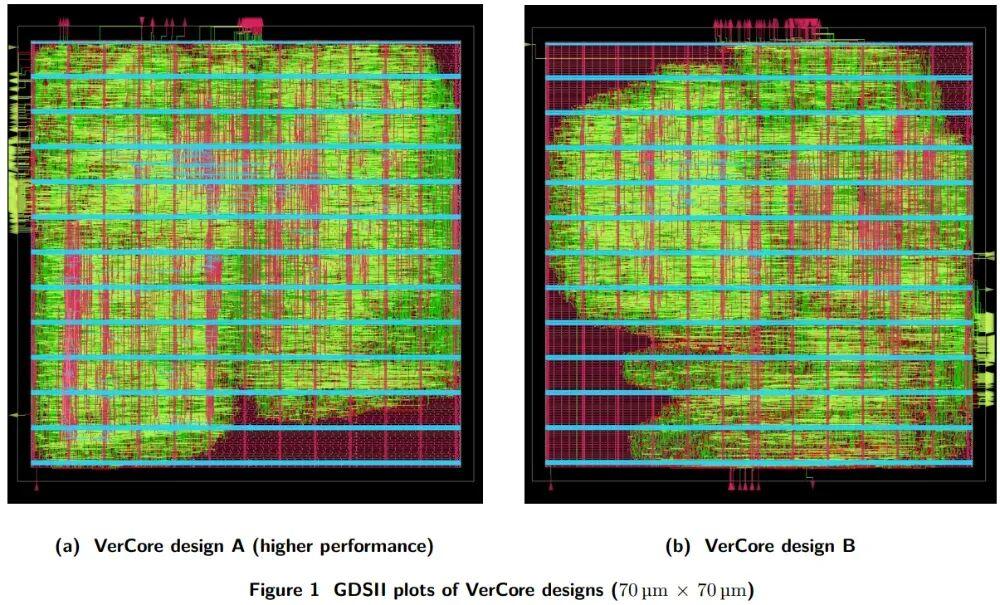
圖 | DC自主生成的最終物理設計輸出(來源:arXiv:2603.08716)
AI 真的“懂”硬件嗎?
儘管 DC 在實戰中展現了卓越性能,但研究團隊同時揭示了 AI 在硬件設計中與人類工程師不同的獨特思維邏輯及侷限性。
例如,研究人員發現,AI 智能體目前更多依賴於“反饋-糾錯”循環。DC 最初設計的前推邏輯可能導致關鍵路徑過長,但它無法直接預見這一問題,而是在接收到 EDA 工具的時序違例報告後,纔開始通過迭代嘗試來縮短路徑。
另外,大模型主要基於順序執行的軟件代碼訓練,但硬件描述語言(HDL,如 Verilog)本質上是由併發和事件驅動的。因此,這種軟件思維與併發邏輯的天然衝突,讓 AI 有時誤認爲減少代碼行數就能縮短時序路徑,然而,這在硬件設計中並不總是成立。
實驗還證明,“提示詞工程“對智能體而言依然相當關鍵,輸入需求的質量有時甚至會決定輸出結果。Verkor 指出,必須在需求中包含可度量的指標。例如,若文檔中未明確要求“每指令週期數(CPI)≤ 1.5”,DC 可能就會生成一個功能正確但性能極差的設計。AI 需要明確的性能錨點來引導其測試平臺進行鍼對性優化。
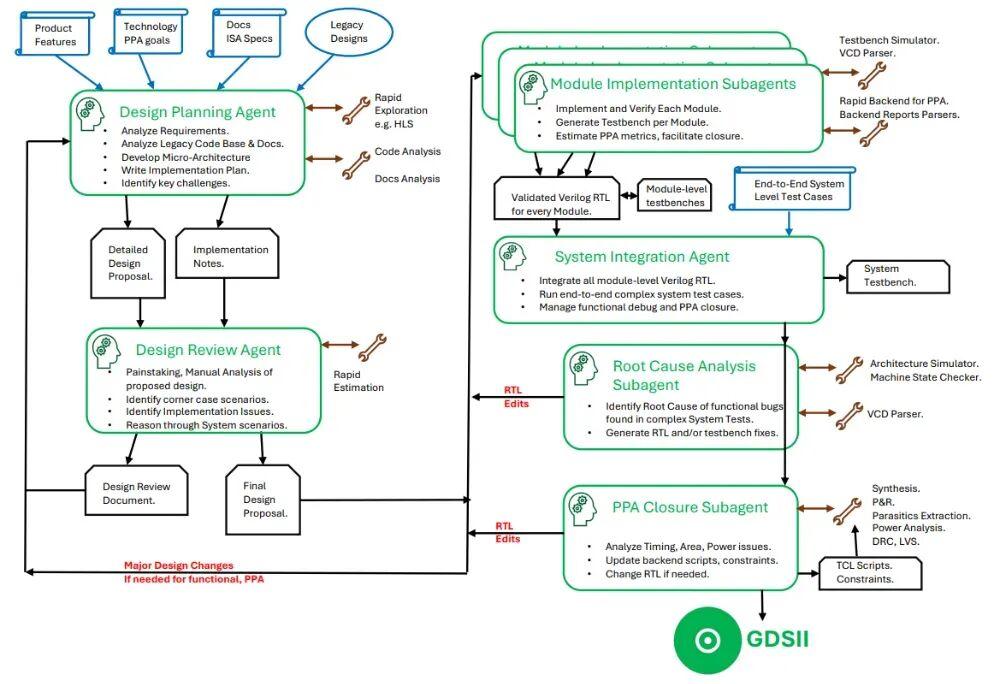
圖 | DC的“典型設計流程”(VerCore 沒有“傳統設計”的概念)(來源:arXiv:2603.08716)
硅片設計也將打破壟斷,迎來民主化?
除了技術上的突破,Design Conductor 的成功或預示半導體產業結構將發生劇變。原本 18-36 個月的流片週期有望在 AI 助力下壓縮至 3~6 個月;此前,許多針對特定領域、低產量的定製芯片設計,由於研發成本過高,被認爲不具商業可行性。AI 智能體將進一步降低設計門檻,讓專用芯片的開發變得廉價且快速。
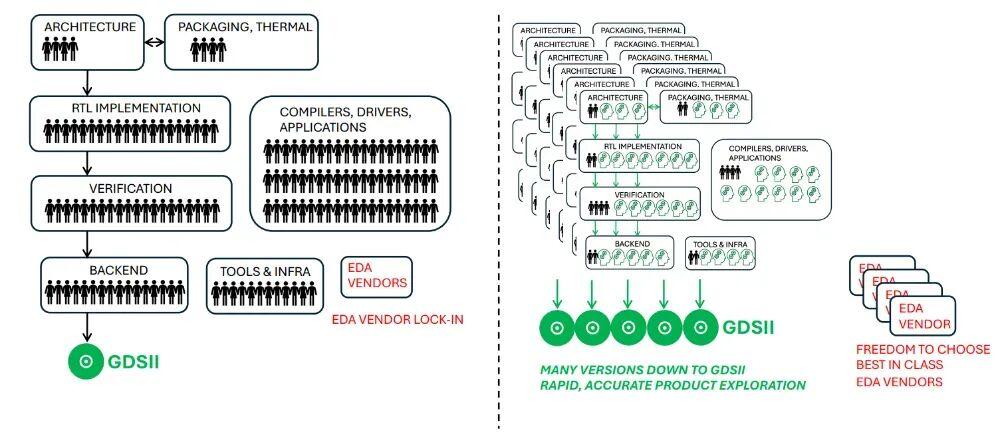
(來源:arXiv:2603.08716)
對於人類工程師而言,他們將從低級 RTL 編寫和繁瑣的 Bug 修復中解脫出來,轉而擔任“首席架構師”的角色,專注於戰略目標設定和高層級架構指導。另外,初步測試顯示,DC 的內存系統和子智能體結構可以擴展支持包含數百萬行 Verilog 代碼的項目。目前其已在嘗試設計 13 級亂序執行(Out-of-Order)處理器,爲硅片設計提供超大規模複雜性支持
一直以來,硬件設計都是一項高度受限的多目標耦合工程,但 Verkor 的這項研究證明,自主 AI 智能體完全足以勝任這種複雜任務。通過 200 餘字的文檔、半天內就能生成 1.5 GHz 的處理器,我們離“芯片隨需而變”的未來已不再遙遠。正如 Verkor 團隊所言,AI 正在攻克芯片設計的“最後邊疆”。
參考內容:
https://www.alphaxiv.org/overview/2603.08716v1
https://www.lesswrong.com/posts/uix7mr2DyjeJ5pmaL/an-agent-autonomously-builds-a-1-5-ghz-linux-capable-risc-v
https://verkor.io/
https://github.com/riscv-software-src/riscv-isa-sim
https://www.eembc.org/coremark/



