3 月 24 日,Google Research 發佈了一套名爲 TurboQuant 的向量量化壓縮算法,宣稱能將大語言模型的 KV 緩存(Key-Value Cache)壓縮至僅 3 比特,同時實現零精度損失。
在 NVIDIA H100 GPU 上的測試中,4 比特精度的 TurboQuant 在計算注意力 logits 時取得了相比 32 位未量化基線高達 8 倍的性能提升。這篇論文將於下月在 ICLR 2026 上正式發表,第一作者 Amir Zandieh 是 Google Research 的研究科學家,通訊作者 Vahab Mirrokni 是 Google Research 副總裁兼 Google Fellow。

圖丨相關論文(來源:arXiv)
消息發佈當天,資本市場給出了自己的解讀。內存芯片廠商 SanDisk(SNDK)股價在週三交易時段下跌約 5%,收於 677.86 美元。分析師指出,TurboQuant 所代表的極端壓縮技術路線,對於一家憑藉 AI 驅動的內存需求在 2025 年股價飆漲近 196% 的芯片公司而言,構成了直接的敘事威脅。這個市場反應或許有些過度,但華爾街的焦慮也不無道理,畢竟 KV 緩存的內存開銷,確實已經是 LLM 運營者賬單上最大的單項成本之一。
大語言模型在生成文本時,每處理一個 token 都需要計算並存儲一組 key 和 value 向量,以便後續生成時不必從頭重算。這些向量逐 token 累積,內存佔用隨上下文長度線性增長。
以 Llama 3 70B 參數模型爲例,當併發服務 512 個請求、每個請求的 prompt 長度爲 2,048 個 token 時,僅 KV 緩存就需要大約 512GB 的存儲空間,幾乎是模型權重本身所需內存的四倍。上下文窗口越長,這個數字就越誇張。對於任何在生產環境中運行 LLM 的團隊來說,KV 緩存的內存開銷早已從技術細節升級爲成本核心。
傳統的向量量化方法確實可以壓縮 KV 緩存,把浮點數映射到低比特的整數表示,但大多數方案都面臨一個共同的尷尬:爲了保證量化精度,每個數據塊都需要額外存儲一組全精度的量化常數(比如縮放因子和零點),這些常數本身會增加 1 到 2 個比特的額外開銷,相當於一邊壓縮一邊又把空間還回去。TurboQuant 瞄準的正是這個問題。
TurboQuant 本質上是三篇論文的組合成果。第一個組件叫 PolarQuant,將在 AISTATS 2026 上發表。它的核心思路是對輸入向量做一次隨機旋轉,將數據從標準的笛卡爾座標系轉換到極座標系。傳統量化方法在笛卡爾座標下工作,需要爲每個數據塊單獨計算歸一化參數,而極座標變換後,向量被分解爲一個半徑(代表信號強度)和一組角度(代表方向信息)。
關鍵在於,旋轉後每個座標的分佈會收斂到一個已知的 Beta 分佈(高維下近似高斯分佈),且不同座標之間近似獨立。這意味着可以對每個座標獨立地使用最優的標量量化器(通過經典的 Lloyd-Max 算法求解連續一維 k-means 問題),不再需要存儲逐塊的量化常數,從根本上消除了傳統方法的內存開銷。
第二個組件是 QJL(Quantized Johnson-Lindenstrauss,量化 JL 變換),已於 AAAI 2025 發表。QJL 利用經典的 Johnson-Lindenstrauss 變換將高維數據降維,同時把每個結果值壓到只剩一個符號位(+1 或 -1),整個過程零額外內存開銷。它的價值在於提供無偏的內積估計,這對注意力計算至關重要。
TurboQuant 將兩者組合成一個兩階段流水線:先用 PolarQuant 以 b-1 比特的精度完成主體壓縮,喫掉絕大部分誤差;再對殘差(主體壓縮後剩餘的微小誤差)施加 1 比特的 QJL 變換,消除內積估計中的偏差。論文從信息論角度證明,這種組合方案的失真率與 Shannon 下界之間只差一個約 2.7 的常數因子。換句話說,TurboQuant 在理論上已經非常接近任何壓縮算法所能達到的最優邊界。
實驗結果的亮點集中在幾個方面。在“大海撈針”(Needle-in-a-Haystack)測試中,TurboQuant 在將 KV 緩存壓縮至少 6 倍的情況下,取得了與未壓縮基線完全一致的 0.997 分,而此前廣泛使用的 KIVI 方法在同等壓縮條件下得分爲 0.981,SnapKV 和 PyramidKV 等 token 級剪枝方案的表現則更弱。
在 LongBench 基準上,覆蓋問答、摘要、代碼補全和 few-shot 學習等任務,3.5 比特的 TurboQuant 在 Llama-3.1-8B-Instruct 上取得了 50.06 的平均分,與 16 比特全精度緩存的 50.06 持平;即便壓到 2.5 比特,平均分也只微降至 49.44。
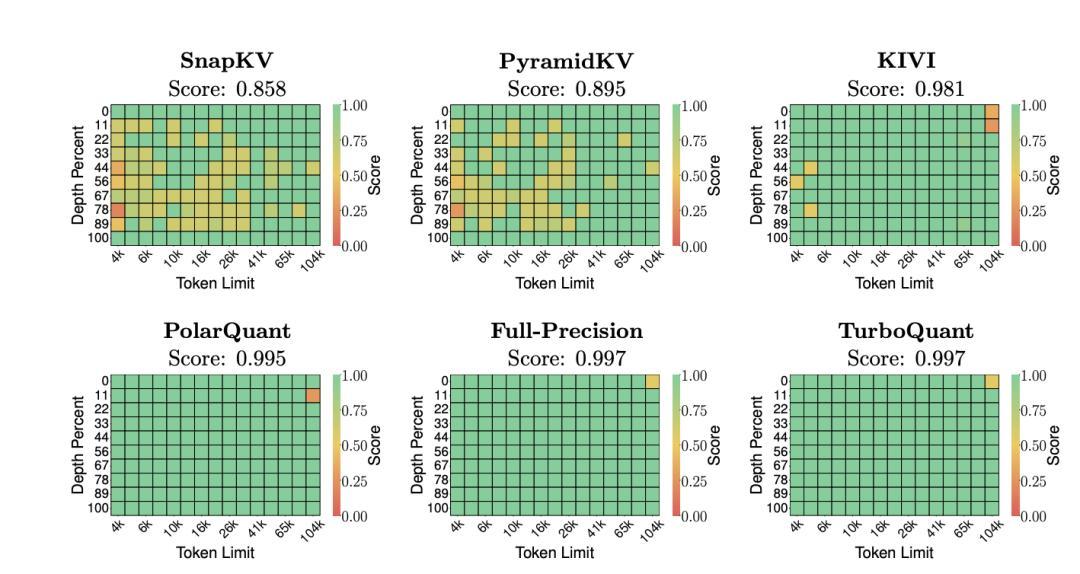
圖丨大海撈針基準測試結果(來源:arXiv)
在向量搜索場景中,TurboQuant 同樣表現突出。研究團隊在 GloVe(200 維)和 OpenAI 嵌入(1536 維、3072 維)數據集上將其與 Product Quantization(PQ)和 RabitQ 做了對比。TurboQuant 在各個維度和比特精度下的 1@k 召回率均優於兩個基線,且完全不需要離線構建碼本,PQ 需要 37 秒的碼本構建時間(200 維、4 比特),RabitQ 需要 597 秒,TurboQuant 只需 0.0007 秒,幾乎可以忽略。這意味着它天然適合數據持續更新的在線索引場景。
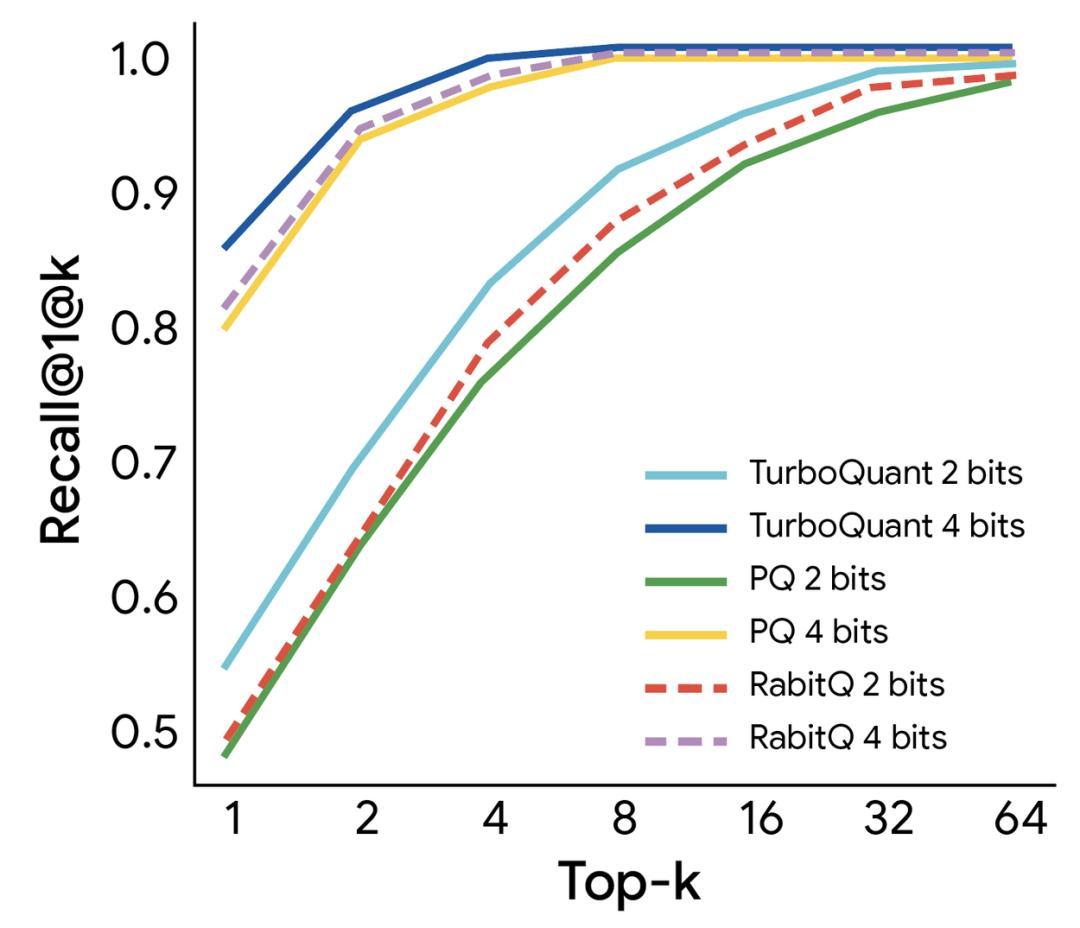
圖丨GloVe 數據集(d=200)基準測試結果(來源:Google Research)
值得一提的是,近期英偉達發佈的 KVTC(KV Cache Transform Coding)也致力於這一方向(同樣被 ICLR 2026 接收),且宣稱可達 20 倍壓縮,精度損失控制在 1 個百分點以內。不過兩者嚴格來說解決的是不同環節的問題。
TurboQuant 是向量量化路線,目標是在推理過程中即時把 KV cache 壓到低比特,然後直接用量化後的數據計算注意力,同時還兼顧向量搜索場景。 KVTC 走的是變換編碼路線,借鑑 JPEG 圖像壓縮的思路:先用 PCA 去相關,再做自適應量化,最後用 DEFLATE 熵編碼進一步壓縮。它更側重於 KV cache 的緊湊存儲與傳輸,典型場景是多輪對話之間把 cache 卸載到 CPU 或 SSD 再恢復,或者跨請求複用 cache。
NVIDIA 研究員 Adrian Lancucki 在接受 VentureBeat 採訪時也明確表示,KVTC 針對的是長上下文、多輪對話場景。相比較而言,TurboQuant則針對的是推理計算路徑上的實時壓縮。
在此之前,KV 緩存量化領域的標準基線是 2024 年發表於 ICML 的 KIVI,它引入了非對稱 2 比特量化方案,實現了約 2.6 倍的內存壓縮。KIVI 已經集成進了 HuggingFace Transformers,是目前部署最廣泛的方案之一。TurboQuant 在同類向量量化路線上直接把壓縮比從 2.6 倍拉到 6 倍以上,且不需要任何校準數據,進步幅度相當明顯。
需要指出的是,TurboQuant 論文中的實驗模型規模止步於 8B 參數左右(Llama-3.1-8B-Instruct、Ministral-7B-Instruct),尚未在 70B 或更大規模的模型上驗證。而恰恰是在這些大模型上,KV 緩存的壓縮才最迫切、收益也最大。
另外,這篇論文最早於 2025 年 4 月就出現在 arXiv 上,到現在快一年了,谷歌也沒有公佈官方的代碼實現或與現有推理框架(如 vLLM、TensorRT-LLM)的集成計劃,雖然社區已經出現了基於 Triton、MLX 和 llama.cpp 的第三方實現嘗試。
Mirrokni 團隊此前的 Titans 架構和 Nested Learning 範式也是類似情況,論文效果亮眼,學術社區討論熱烈,但官方代碼始終沒有釋出,落地全靠第三方復現。TurboQuant 是否會重複這個模式,目前還不好說。
從這一點上來說,內存股價跌得可能有點太早了,更何況,AI 模型對內存的胃口,總是會迅速膨脹到填滿所有可用空間。SemiAnalysis 此前在分析 HBM 發展路線時提過一個觀察,可以叫“內存帕金森定律”:每一輪硬件升級或軟件優化釋放出來的餘量,很快就會被更長的上下文窗口、更大的批處理規模、更復雜的推理管線吞掉。
所以,TurboQuant 省下來的那 5 倍內存,大概率不會讓 GPU 閒着,它會被用來服務更多併發請求、處理更長的文檔,或者跑原本塞不下的大模型。壓縮技術擴大的是推理效率的供給側,不是在縮減內存的需求總量。
參考資料:
1.https://arxiv.org/pdf/2504.19874
2.https://arxiv.org/pdf/2511.01815
3.https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
運營/排版:何晨龍