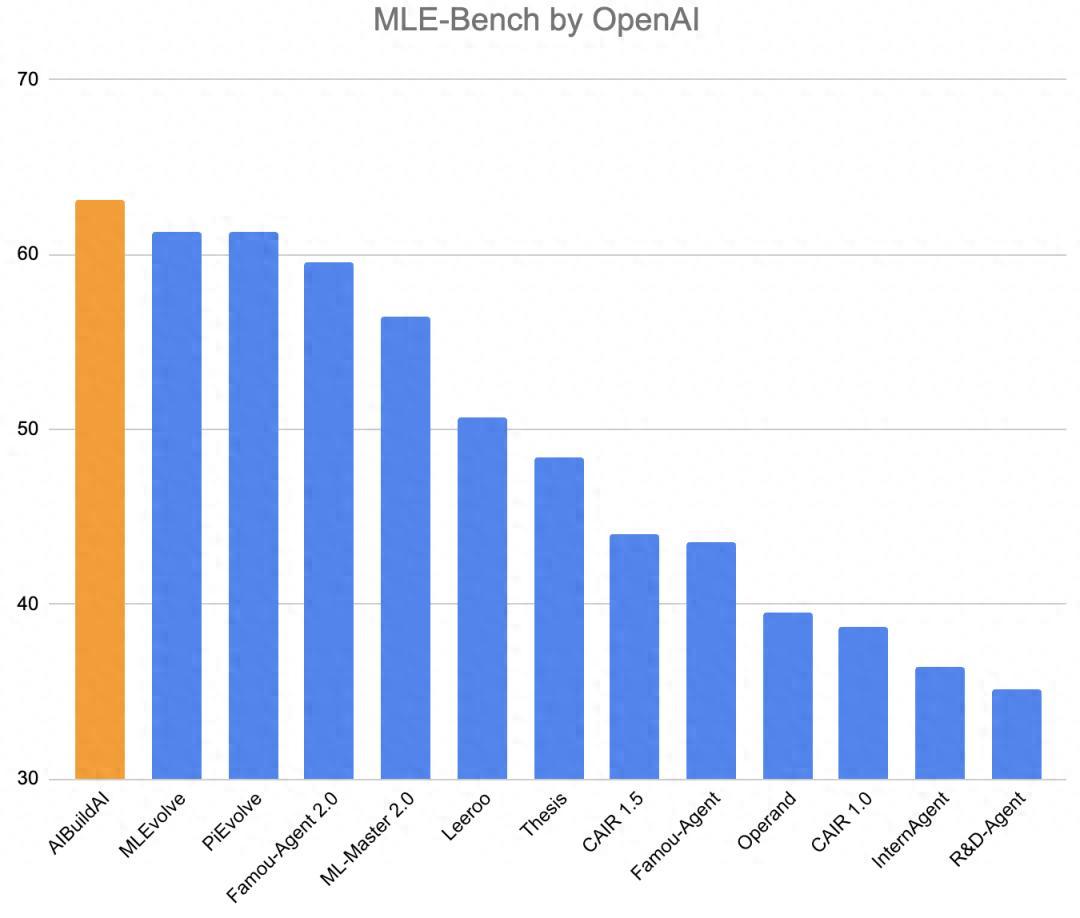
近日,在 OpenAI 發佈的機器學習工程師基準測試(MLE-bench)中,一個名爲 AIBuildAI 的智能體系統以 63.11% 的整體得分穩居第一。
AIBuildAI 是一個可以自動構建 AI 模型的 AI 智能體。這意味着,你只需給它一個自然語言任務描述和數據文件夾,它就能在一天內獨立完成模型設計、代碼生成、模型訓練、超參數調優、性能評估,並持續迭代改進模型性能。
(來源:受訪者提供)
這個“AI 工程師”背後的主要負責人,正是加州大學聖地亞哥分校(UCSD)電氣與計算機工程系副教授謝澎濤(Pengtao Xie)。他擁有卡內基梅隆大學機器學習系博士背景,研究方向聚焦人類學習技能啓發的機器學習,並將其應用於大語言模型、基礎模型以及生物醫學領域。
據謝澎濤介紹,AIBuildAI 的誕生,最初是爲了解決實驗室內部一個非常現實的困境。
“我們團隊有兩類學生。一類是生物醫學背景的,他們希望用 AI 預測 RNA 功能、蛋白質結構等具體問題,但缺乏建模和編程能力;另一類是 AI 方法背景的,雖然能自己寫代碼,卻要花好幾天甚至幾周反覆實驗。”謝澎濤告訴 DeepTech。
“如果有一個智能體,能讓用戶只用自然語言描述任務,後續所有步驟——模型架構設計、代碼編寫、訓練、超參數調優、性能評估、甚至自我覆盤改進——全部自動完成,那對兩類學生都是巨大解放。”他補充道。
於是,AIBuildAI 項目正式啓動。“智能體本身大約做了半年,但底層的推理、合成數據等技術我們已經積累了好幾年。”謝澎濤透露,團隊對於這款智能體的定位也十分明確:基於成熟 AI 模塊組合設計模型,解決落地性強的常規任務。
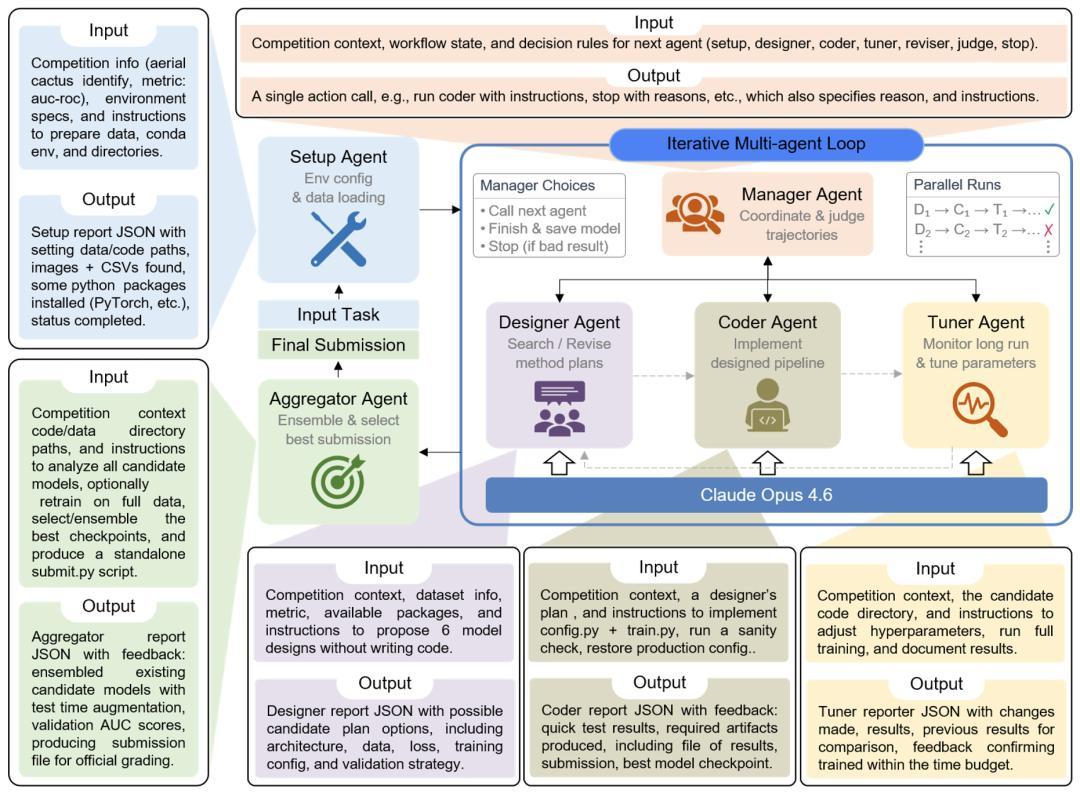
據悉,AIBuildAI 是一套模塊化、可閉環運行的 AI 智能體系統,整體分爲三層,各司其職又深度聯動,實現從任務理解到模型交付的全流程無人干預。
頂層是任務理解與決策層。當用戶輸入“預測 RNA 功能”或“蛋白質酶分類”等自然語言指令時,這一層負責解析意圖、判斷任務類型並拆解執行步驟。它是整個系統的“指揮中心”,決定了建模的方向和邏輯。
在這一核心中樞的選擇上,團隊選用了 Claude-Opus-4.6 大模型。“我們測試對比了多個模型,雖然 GPT-5 在某些設計思路上表現出色,但在智能體最關鍵的環節——‘寫代碼’上,Claude 的穩定性、長流程邏輯理解和結構化指令執行力是最適配建模場景的。”
中層是推理與代碼生成層,也是 AIBuildAI 的技術核心,搭載團隊自研的 Dream PRM(過程獎勵模型)、Dream ORM(結果獎勵模型)推理模塊,負責模型設計、代碼編寫、迭代覆盤。PRM 負責步驟級精準推理,ORM 負責結果校驗與優化建議,雙重保障每一步執行不出錯,避免“一步錯、全流程崩”的問題,也是實現自動覆盤改進的關鍵。
底層是執行與訓練層,其承接中層生成的代碼和方案,自動完成數據加載、模型訓練、超參數調優、性能評估、結果輸出,同時管控硬件資源和算力消耗。這一層把上層的“設計思路”轉化爲可運行、可部署的實際模型。
(來源:受訪者提供)
爲了驗證 AIBuildAI 的能力,團隊在 MLE-bench 的 75 個任務(涵蓋醫療、物理、生物等多個學科)中進行了測試。MLE-Bench 是 OpenAI 推出的全球頂尖的全自動機器學習測評平臺,專門考覈 AI 智能體 “獨立構建有效 AI 模型” 的能力,測評覆蓋簡單(Low)、中等(Medium)、高難度(High) 三類真實 AI 任務,最終按整體準確率排名,是行業內公認的“全自動 ML 能力試金石”。
AIBuildAI 在這個測評中交出了亮眼的成績,在無測試數據泄露的前提下排名第一。其中簡單任務準確率77.27%;中等任務準確率 61.40%;高難度任務準確率 46.67%;整體綜合準確率 63.11%。
以“蛋白質酶類別預測”爲例,該任務基於發表在 Science 論文的數據集,AIBuildAI 自動構建的模型,效果完全對標論文成果,普通用戶藉助簡化數據集就能快速復現。
“對比學生手動寫代碼需要好幾天,AIBuildAI 十幾分鍾就能完成代碼編寫,大多數數據量不大的任務,一天內就能落地。”謝澎濤介紹道。
目前,AIBuildAI 已深度融入團隊實驗室工作,主要服務生物醫學背景的研究者,完美適配分類、迴歸、序列分析等單模態任務,無論是生物信息數據分析,還是產業界的預測建模需求,都能輕鬆勝任。但對於 AI方向博士生的前沿研究、多模態融合任務,目前仍無法完全滿足,團隊仍在持續迭代優化。
針對用戶關心的系統適配問題,謝澎濤表示,現階段 AIBuildAI 僅支持 Linux 系統,暫無適配 Mac、Windows 的計劃。“AI 模型訓練依賴 GPU,而 99% 的 GPU 環境都部署在 Linux 上,足以覆蓋絕大多數使用場景。”
據悉,AIBuildAI 已開啓中小企業試用,收穫了不少真實反饋,也明確了下一步優化方向。用戶反饋的核心問題集中在兩點:數據處理能力不足,難以應對缺失值、標註混亂等問題;對用戶意圖理解不夠精準。
謝澎濤坦言,數據處理的技術難點並不大,通過增加數據質量檢查工具就能逐步優化,但現實場景中數據問題繁雜,實現泛化適配仍有挑戰。這也是團隊接下來的重點攻堅方向。
對於 AIBuildAI 的長遠未來,謝澎濤有着更宏大的構想:讓智能體具備自我學習、自我進化的能力。“未來它能主動閱讀最新論文,歸納新知識、轉化爲自身技能,不用人工干預就能實現能力升級。”
參考鏈接:
1.https://pengtaoxie.github.io/
2.https://github.com/aibuildai/AI-Build-AI
3.https://github.com/openai/mle-bench/pull/126
4.https://www.science.org/doi/10.1126/science.adf2465
運營/排版:何晨龍