據媒體The Verge報道,被谷歌起訴的SerpApi是一家網絡內容抓取工具公司,或者更直接一點,叫網絡爬蟲公司。他們在上週五提交的駁回動議裏反嗆一嘴,稱谷歌纔是網絡爬蟲的始作俑者,是“全球最大的網絡爬蟲”。
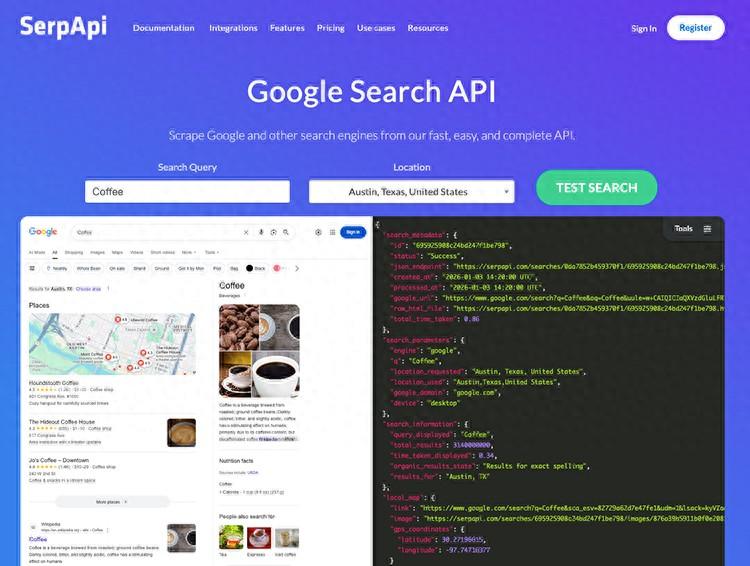
衆所周知,搜索引擎爲什麼能幫你搜到內容,靠的就是網絡爬蟲。搜索引擎的網絡爬蟲可以遍歷開放的各個網絡,從網站上爬取所有的信息並記錄,這才能讓你搜索到。它還會定時回訪已經抓取過的網站,爲的就是確保對網站數據的技術更新。
以上說的這些都是良性的行爲,它其實也有惡意行爲,比如某些爬蟲程序可以無視網站訪問頻率限制,用極高的頻率抓取數據,這就會導致網站服務器崩潰;比如某些爬蟲程序不遵守君子協議,抓取了網站規定範圍之外的隱私數據,侵犯了用戶的利益等等。

SerpApi的駁回動議書裏稱“谷歌纔是全球最大的網絡爬蟲”
在谷歌訴SerpApi的案件中,谷歌指控的罪名是“以驚人的規模”抓取搜索結果,而且使用了“欺騙手段”訪問並抓取谷歌的搜索結果,相當於用谷歌搜索的數據庫來“煉丹”,谷歌稱這違反了《版權法》,並且還指控SerpApi發現了繞開其反抓取功能SearchGuard的方法,對谷歌造成了損失。
在SerpApi的駁回動議中,他們表示只是在做“谷歌對其他所有人做的事情,只是規模小得多。”而且還說谷歌並沒有“對其搜索結果主張所有權”,其從公共網站抓取的公開信息並不受版權保護,繞過SearchGuard的行爲也沒有違反《版權法》,因爲這個功能只保護谷歌的業務,而不是用來保護版權內容。
SerpApi的態度也挺明確的,咱都是幹這行的,你谷歌能爬得,我SerpApi就爬不得?你擱哪兒狂啥呢?只能說,這場訴訟純屬賊喊捉賊的行爲,大家都是靠爬蟲起家的,同行是最瞭解同行的,谷歌你也別想着高人一等了。