

一週前,當 Andrej Karpathy 在 X 平臺上發佈他的新項目 autoresearch 時,整個 AI 社區被迅速吸引。因爲這個項目只用了大約 630 行 Python 代碼,就實現了讓 AI 自主開展研究的機制。
(來源:Karpathy)
截止目前,上線不到兩週,項目的星標數已超過 4 萬。有人在自家 H100 GPU 上運行了 83 次實驗,保留了 15 次有效改進,驗證損失從接近 1,000 穩步下降到 0.975 附近。
autoresearch 的核心在於給 AI 智能體提供一個真實的、簡化的 LLM 訓練環境,讓它徹夜迭代。倉庫主要由三個文件構成:prepare.py 固定負責數據準備和 BPE 分詞器訓練;train.py 是可編輯的核心腳本,包含 GPT 模型、優化器和訓練循環;program.md 則作爲人類編寫的指令手冊,指導 AI 的行爲。
每次實驗嚴格限定 5 分鐘牆鍾時間,評估指標用 val_bpb,確保不同改動間公平比較。智能體修改代碼、運行訓練、檢查結果、決定保留或回滾,整個過程在 git 分支上記錄,形成完整的演化歷史。這延續了 Karpathy 一貫的極簡風格,從 micrograd 到 nanoGPT,再到 nanochat,他總是在把複雜系統壓縮到最小可運行規模,只是 autoresearch 這一次把主角換成了 AI。
但開發者們沒有止步於此。就在 autoresearch 發佈後不到兩週,一支來自美國北卡羅來納大學教堂山分校(UNC)AIMING Lab 的華人團隊,將這個自主實驗循環的概念大幅擴展,開源了 AutoResearchClaw。
這個項目本質上是一個端到端的自主科研 Agent,能從用戶輸入的一個原始研究想法開始,自動完成從文獻檢索到論文撰寫的完整流程。目前倉庫星標已超過 4,500,版本從 v0.1 快速迭代到 v0.3.0(最新於 3 月 17 日發佈),並引入了自進化機制。
(來源:GitHub)
與 autoresearch 主要聚焦 LLM 訓練代碼的超參優化和模型改進不同,AutoResearchClaw 把輸入端直接拉到“一個原始研究想法”。用戶只需在命令行輸入一行 CLI 命令,附上 idea,比如“探索新型注意力機制在長上下文建模中的效率”,系統就會啓動一個 23 階段的端到端流水線,覆蓋 8 個主要階段:從 idea scoping、文獻發現、合成,到實驗設計、執行、分析、寫作和最終定稿。
首先,系統會處理文獻部分。它通過 arXiv 和 Semantic Scholar 檢索真實論文,然後用 DataCite 和 CrossRef 進行交叉驗證。每條引用都要經過四層過濾:arXiv ID 校驗、DOI 查找、標題匹配以及 LLM 相關性打分,任何幻覺引用都會被自動剔除。這一步的嚴謹程度,已經超過了不少人工文獻綜述。
進入實驗階段後,AI 根據前期文獻生成可運行代碼。它會自動檢測用戶硬件(例如是 NVIDIA CUDA、Apple MPS 還是純 CPU),並適配沙箱環境。代碼出錯時,系統自我修復,無需人工介入;如果實驗結果不支持初始假設,它會主動轉向新方向,而不是執着於一條路徑。這個過程繼承了 autoresearch 的緊反饋循環,但範圍大大擴展:不再侷限於調參,而是真正設計對比實驗、生成圖表、記錄各項指標。
實驗完成後,多智能體評審機制接管,幾輪“同行評議”檢查方法論與證據的一致性,並輸出修訂建議。最後,系統生成一篇 5,000 詞以上的完整論文草稿,包括引言、相關工作、方法、實驗、結論等標準章節。
數學公式用 KaTeX 渲染,對比圖表自動繪製,直接套用 ICML、ICLR 或 NeurlPS 的 LaTeX 模板。用戶最終拿到的是可直接編譯的 .tex 文件、驗證過的 BibTeX 引用列表、全部實驗腳本、沙箱運行結果以及同行評審筆記。如果選擇全程無人值守,只需加上 --auto-approve 參數;如果更謹慎,也可以設置三個審批關卡(對應階段 5、9、20),逐步人工介入。
(來源:GitHub)
AutoResearchClaw 的團隊主要來自 AIMING Lab,核心貢獻者包括 Huaxiu Yao 等研究者。他們明確表示,項目站在兩個重要基礎之上:一是 Karpathy 的 autoresearch,提供了代碼自主迭代的微循環;二是 OpenClaw 框架,提供了多 Agent 編排的底層支持。
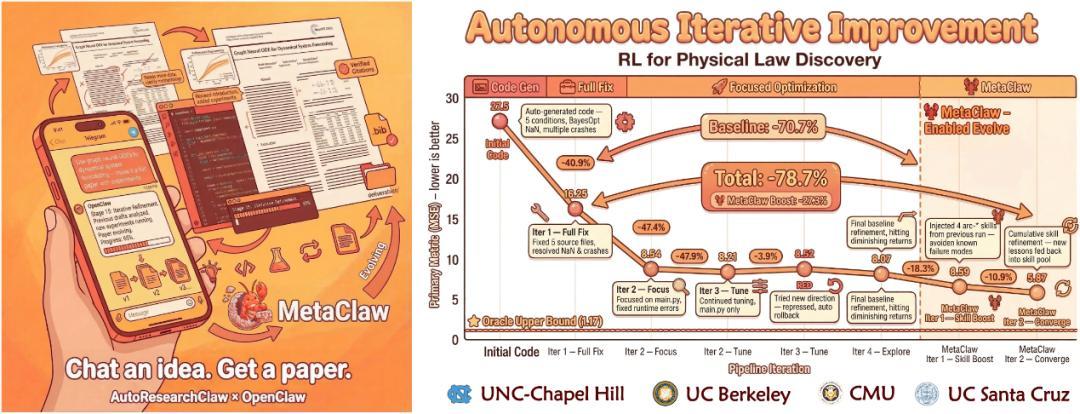
v0.2 版本引入 MetaClaw 自進化引擎,從失敗案例中提取教訓,轉化爲可複用技能,注入後續運行,實測減少 40% 的 refine 週期;v0.3 則進一步強化速率限制防護、多 API 級聯搜索(從 OpenAlex 到 Semantic Scholar 再到 arXiv),以及多 Agent 辯論模塊。這些更新都在 GitHub 上公開,issue 區非常活躍,用戶反饋直接推動下一版迭代。
從實際案例來看,這個項目的工程魯棒性超出預期。一位早期測試者輸入“Unity 資產剪枝優化”作爲 idea,系統自動完成文獻蒐集、代碼生成、實驗驗證,最後輸出一篇會議級論文,連圖表都完整配齊。
另一個例子中,智能體在實驗失敗後主動調整假設,避免了 p-hacking 式的偏差。這與早期 AI 論文生成工具的根本區別在於:它不是簡單文本拼接,而是將 autoresearch 的“實驗自我迭代”真正擴展到科研全鏈條,從選題到投稿準備,一氣呵成。
項目也注重開放性和可審查性。所有輸出包括完整實驗腳本和結果日誌,便於人類複覈;引用列表全部可追溯;代碼沙箱默認隔離,降低潛在風險。目前還不支持所有邊緣硬件,但團隊已表示社區 fork 和適配工作正在推進。倉庫 README 反覆強調,這套工具的目標不是取代研究員,而是把“從靈感和 arXiv 投稿”的週期從幾個月壓縮到一個晚上。
今天,AutoResearchClaw 仍在快速迭代。最新 release 優化了多 Agent 辯論和 LaTeX 導出,用戶反饋顯示,配合 Claude Code 這類編碼智能體,整體成功率已超過 85%。
參考鏈接:
1.開發者主頁:
https://x.com/HuaxiuYaoML/status/2033038170653405308/photo/1
2.項目地址:
https://github.com/aiming-lab/AutoResearchClaw
運營/排版:何晨龍



