

豐田研究院(TRI,Toyota Research Institute)近日發佈了一項關於大行爲模型(LBMs,Large Behavior Models)研究成果,這項技術或有望給機器人的學習方式重大變革。研究顯示,通過預訓練的 LBMs,機器人可以在學習新任務時減少高達 80% 的數據需求,單一模型能夠掌握數百項不同的操作技能。相關論文以《大行爲模型多任務靈巧操作的細緻檢驗》(A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation)發表在 arXiv 上。

圖丨相關論文(來源:arXiv)
研究的作者之一,豐田研究院副總裁、美國麻省理工學院教授 Russ Tedrake 在社交媒體上表示:“LBMs 確實有效!隨着預訓練數據量的增加,我們看到了一致且具有統計學意義的改進。”
圖丨相關推文(來源:X)
傳統的機器人訓練方法存在諸多限制:每個任務都需要單獨編程,學習過程緩慢且不一致,往往侷限於狹窄定義的任務和高度受限的環境。相比之下,LBMs 採用了類似於大語言模型(LLMs,Large Language Models)的架構思路,但專門針對機器人的物理操作行爲進行優化。
TRI 此次研究採用的 LBM 架構,是一種基於擴散模型和 Transformer 的複雜神經網絡。它能夠整合來自多路攝像頭(包括機器人手腕和場景攝像頭)的視覺信息、機器人自身的姿態和位置等本體感知數據,以及人類通過自然語言下達的任務指令。這個多模態系統通過學習,直接輸出機器人需要執行的一系列連貫、精確的動作指令。具體來說,這些模型能夠一次性預測未來 16 個時間步(約 1.6 秒)的動作序列,從而實現平滑而具有預見性的操作。
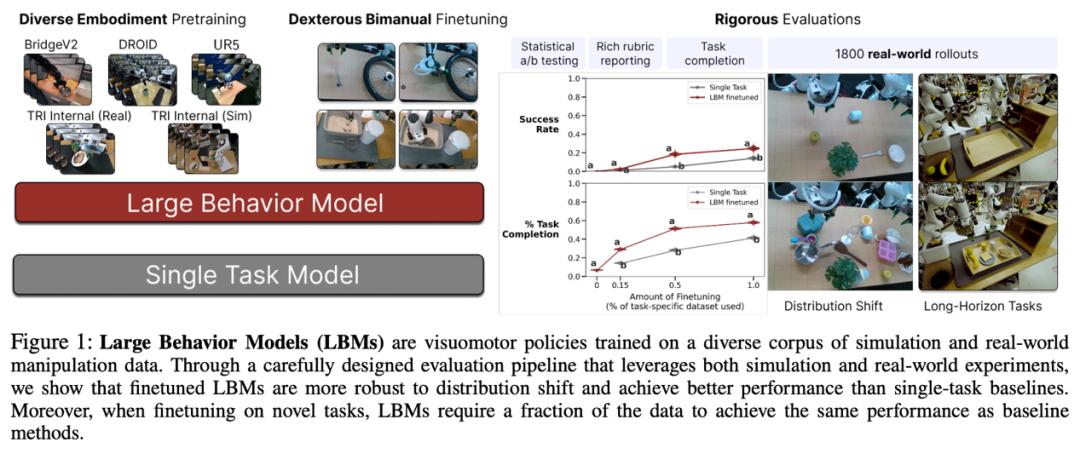
圖丨大型行爲模型(LBMs)是基於多樣化的仿真和真實世界操作數據訓練的視覺運動策略(來源:arXiv)
爲了驗證 LBMs 的有效性,研究團隊在近 1,700 小時的機器人演示數據上訓練了多個 LBMs,這些數據包括 468 小時的內部收集雙臂機器人遙操作數據、45 小時的仿真收集遙操作數據、32 小時的通用操作接口(UMI,Universal Manipulation Interface)數據,以及約 1,150 小時從 Open X-Embodiment 數據集中精選的互聯網數據。
在評估環節,研究團隊進行了 1,800 次真實世界評估試驗和超過 47,000 次仿真試驗,覆蓋 29 個不同任務。爲確保結果的可靠性,他們採用了盲測 A/B 測試方法,並建立了新的統計評估框架來確保跨不同任務和設置的結果置信度。
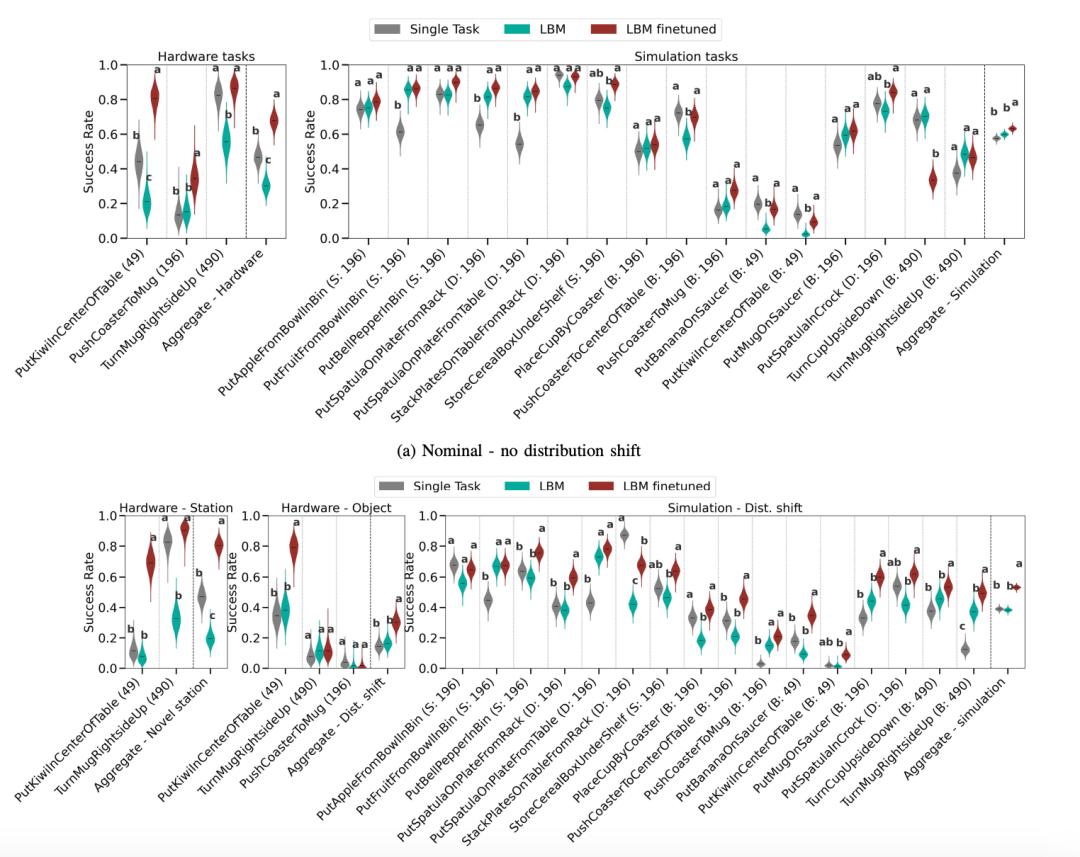
(來源:arXiv)
研究中使用的硬件平臺基於 Franka Panda FR3 機械臂的雙臂操作系統,配備多達六個攝像頭——每個手腕最多兩個,以及兩個靜態場景攝像頭。在感知層面,模型使用預訓練的 CLIP 視覺變換器提取圖像特徵,並通過 CLIP 文本編碼器處理任務描述的語言特徵。這些視覺和語言特徵與本體感受信息以及擴散時間步編碼相結合,形成觀察特徵。
在動作生成方面,LBMs 採用去噪擴散隱式模型(DDIM,Denoising Diffusion Implicit Models)來生成連續的機器人動作。通過 K 步迭代去噪過程,從高斯噪聲樣本開始,逐步生成精確的動作序列。
研究得出了三個關鍵發現。首先,微調後的 LBMs 在已見任務上的表現始終優於單任務基線模型。在名義條件和分佈偏移條件下,無論是在仿真還是真實世界環境中,微調的 LBM 都表現出統計學上的顯著優勢。
其次,LBMs 展現出更強的魯棒性。當引入分佈偏移時,雖然整體任務性能有所下降,但微調的 LBMs 比從零開始訓練的策略表現出更強的適應能力。在仿真環境中,LBMs 在分佈偏移條件下統計上優於單任務策略的比例從名義條件下的 3/16 提升到 10/16。
第三,也是最重要的發現是,LBMs 能夠顯著減少學習新任務所需的數據量。研究表明,要在仿真中達到相似的性能水平,需對 LBM 進行微調。所需的數據量不到從零開始訓練所需數據的 30%。在真實世界任務中,這一優勢更加明顯——LBM 僅用 15% 的數據就能超越使用全部數據訓練的單任務基線模型。
研究還驗證了 LBM 的 Scaling Law。通過使用不同比例的預訓練數據,研究人員發現隨着預訓練數據量的增加,模型性能穩步提升。即使在當前的數據規模下,研究人員也沒有發現性能的不連續性或急劇拐點,這表明人工智能擴展在機器人學習領域同樣有效。
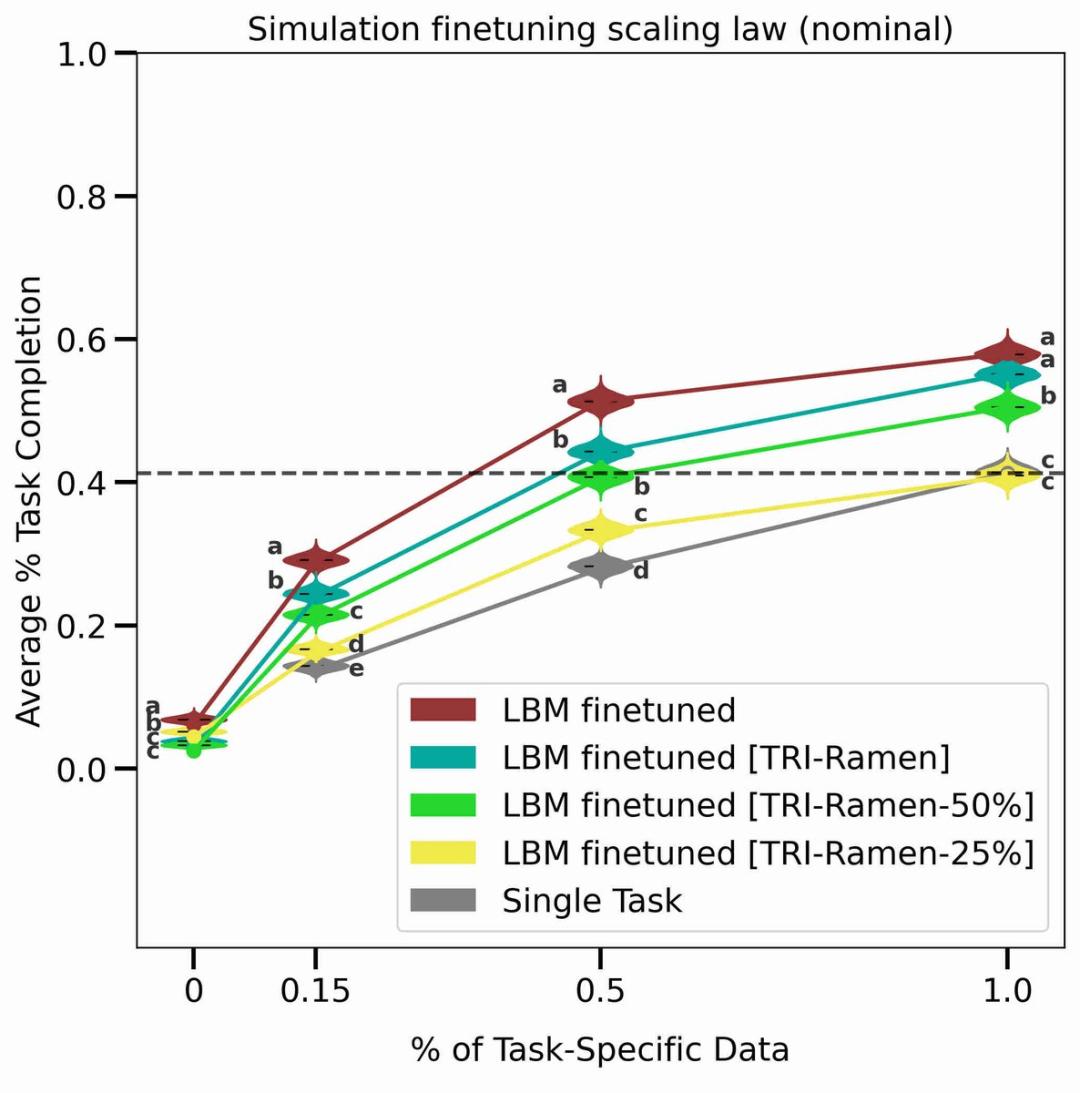
圖丨LBM 上的 Scaling Law(來源:arXiv)
爲了測試 LBMs 的能力極限,研究團隊還設計了多種複雜的長期任務。例如,“切蘋果”任務要求機器人使用蘋果取芯器給蘋果去核,從器具架中取出刀具,拔出刀鞘將蘋果切成兩半,再將兩半切成片,最後用布擦拭刀具並重新裝鞘放回器具架。在這類複雜任務中,LBMs 同樣展現出了優於傳統方法的性能。
這項研究的一個重要貢獻是強調了統計嚴格性在機器人學習評估中的重要性。研究團隊指出,許多機器人學習論文可能由於統計功效不足而測量的是統計噪聲而非真實效果。他們展示了在不同試驗次數和真實成功率下的置信區間寬度:以 50 次試驗爲例,得到的置信區間寬度通常爲 20%-30% 的絕對成功率,這使得除了最大規模的效應之外,其他效應都無法可靠測量。
爲了解決這一問題,研究團隊採用了貝葉斯分析方法,使用均勻 Beta 先驗計算成功率的後驗分佈,並通過緊湊字母顯示(CLD,Compact Letter Display)方法指示統計顯著性。這種方法爲機器人學習領域設立了新的評估標準。
研究結果表明,即使在數據規模相對較小的情況下,預訓練也能帶來一致的性能提升。這使得建立數據獲取和性能提升的良性循環得以可能。隨着更多任務被納入預訓練混合數據中,LBM 的整體性能將持續平穩改善。然而,研究也發現了一些侷限性。非微調的預訓練 LBMs 表現參差不齊,這部分歸因於模型語言引導能力的侷限性。
研究團隊表示,在內部測試中,更大的視覺-語言行爲原型在克服這一困難方面顯示出良好前景,但需要更多工作來嚴格驗證這一效果。此外,數據標準化等看似次要的設計選擇對下游性能有重大影響,往往超過架構或算法改進的影響,提醒研究者在比較方法時需要仔細隔離這些設計選擇,避免混淆性能變化的來源。
參考資料:
1.https://arxiv.org/pdf/2507.05331
2.https://toyotaresearchinstitute.github.io/lbm1/
3.https://x.com/RussTedrake/status/1942931808422875640
運營/排版:何晨龍



