

“其實我已經不需要發論文,也已經很久不再自己動手寫代碼做實驗了,但是爲了這篇論文我重新下場做實驗。主要動力是希望把事情搞清楚。”亞馬遜雲上海人工智能研究院院長張崢告訴 DeepTech。

圖 | 張崢(來源:https://zzhang-cn.github.io/)
在最近一篇論文中,他提出了計算裂腦綜合徵的新概念,藉此闡述了大模型的一個根本性缺陷:即它們能夠清晰地闡述正確的原則,卻無法可靠地應用這些原則。也就是說,從結構角度來看,大模型並沒有掌握規則,它只是表面上看懂,並沒有真正做符號上的推理。

知其然而不能其然
張崢舉例稱,包括人類在內的生物在進化過程中獲得了很多能力,但是生物卻無法描述自己爲何擁有了新的能力。“能而不知其所以然”(Competence without Comprehension)是美國哲學家丹尼爾·克萊門特·丹尼特(Daniel Clement Dennett III)提出的一個觀察。對於生物來說它們更多是因爲環境壓力而長出了某種能力,比如變色龍爲了躲避敵人而讓自己的皮膚改變顏色。但是,這個能力是怎麼來的?它的規則和計算是怎樣的?變色龍本身並不清楚。
但對於大模型來說卻正相反,它們展現出理解而不能執行的現象,能夠流利地解釋原理,卻無法可靠地執行這些原理。當讓它抽象地判斷兩個數字的大小、血緣關係如何分析時,它可以講得頭頭是道,但是它自己執行起來卻經常搞錯。而本次論文正是研究了這一問題。
儘管當前有很多 Transformer 的變種,但只要依賴大量文本的無監督訓練,只要模型大框架不變,就會面臨一個本質問題:模型能夠回答問題,但本身並不是在做計算,因此不具備抽象的推理能力。所以,涉及多個步驟的問題,即便看上去非常簡單,往往都不能放心地交給大模型。
本次研究之中,張崢通過受控實驗和架構分析揭示了這種現象的根本原因,即這種計算裂腦綜合徵源於 Transformer 架構的三個相互依賴的約束條件。值得注意的是,單獨的任何一個約束都不會致命,但它們系統性地相互強化,阻止了大模型在理解和能力之間建立可靠的橋樑。

Transformer 架構中的三個限制
上下文平均化
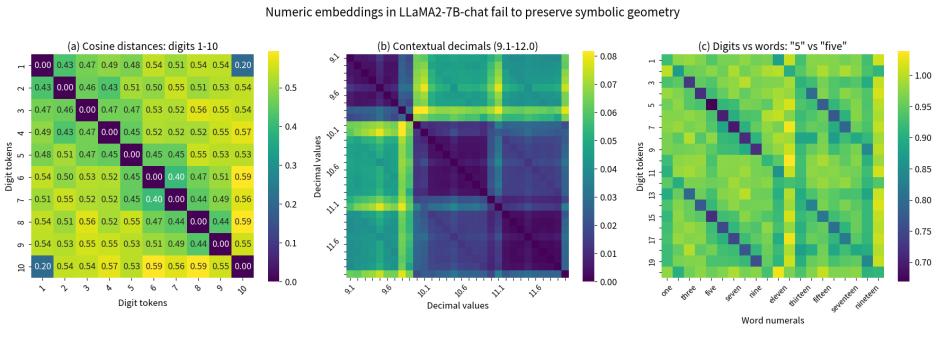
上下文平均化,是 Transformer 架構中的第一個限制。不管計算是黑盒還是明盒,都會有輸入和輸出。假如你面前有一個計算器,不管你在上面按什麼數字,在計算之前這些輸入都會遵循數學上的規律,比如它明確地知道 9 比 11 小了兩個數字。更重要的是,這些數字在計算器的內部表示中保持着等距性質——數值之間的大小關係在表示空間中得到一致的保持。
但是,由於大模型在訓練的過程中,它本身的向量表達中混合了很多上下文的內容。比如,“9.11”可以是一個軟件的版本,也可以指一個歷史事件,因此當大模型看到“9.9”和“9.11”的時候也混入了軟件版本或日期等信息。這種上下文混合破壞了數值表示的等距性質。大模型會把所有單個輸入都壓縮成爲一個向量,這個向量包含了訓練中出現過的所有上下文的信息。因此,無論是讓大模型做數學計算還是做日期計算,都要把數值的性質去模糊化,而這個是大模型不能自動做的。
(來源:https://arxiv.org/pdf/2507.10624)
對於人類來說,當我們說 9.11“小於”9.9,我們是在比較兩個數值;而說“大於”時可能是指版本號。人類能夠根據上下文自動進行域綁定,將同一個符號映射到不同的語義空間。
但是,大模型並不會做這種轉化。在訓練完成後,所有 token 都隱含了上下文的語義關係,導致它在做數學計算時出現混亂。
此前,業內已有研究將 Transformer 從零開始訓練,專門針對數學或邏輯推理單一領域,似乎能夠找到一些“腦回路”。但這種單域訓練的結論無法泛化到通用場景。
對於通用大模型,優化目標是在所有上下文中都表現良好,這必然導致不同上下文的混雜。這種上下文污染是結構性的、不可避免的。即使在邏輯推理中平衡“A 是 B”和“B 是 A”的訓練頻率,模型仍會爲每種句法形式學習獨立的模式匹配規則,而不是理解對稱的邏輯關係。
計算不可能性
計算不可能性,是 Transformer 架構中的第二個限制。
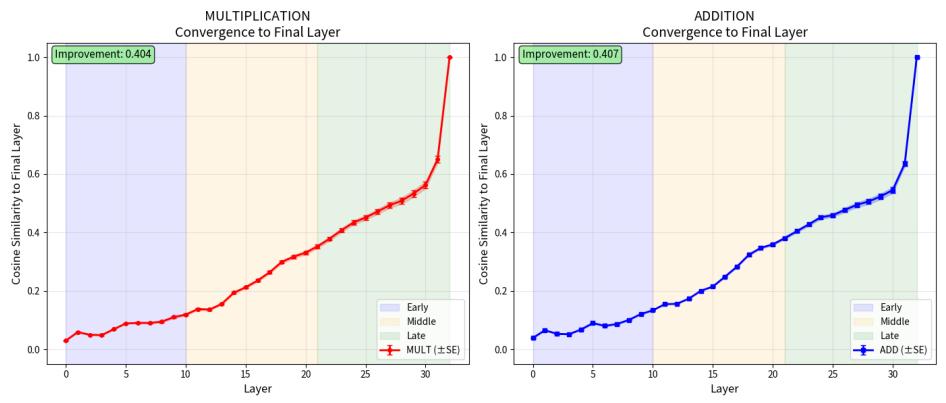
假設輸入向量沒有被上下文污染,大模型要做的似乎就是一個簡單的乘法。但這種“簡單”只是假象。要實現精確的乘法,模型參數必須恰好優化到能夠激活專門的乘法迴路——這在理論上是不可能的。
從數學角度看,問題的根源在於架構限制。基於 ReLU 激活函數的前饋網絡只能實現分段線性函數,而精確的符號運算(如乘法)需要非線性變量交互。這種交互無法通過權重配置單獨實現,構成了架構上的根本障礙。
因此,Transformer 模型無法直接執行乘法,更無法處理任何高階算法,只能進行近似模擬。大模型本質上採用“分層擬合”策略:將複雜運算拆解成小塊,通過多層協調逐步逼近目標輸出。
(來源:https://arxiv.org/pdf/2507.10624)
這揭示了大模型的核心機制——"知識打碎-重組"過程。如何拆解、如何重組完全依賴於訓練過程和語料分佈,這正是大模型可解釋性面臨根本困難的原因。
指令執行分離
指令執行分離,是 Transformer 架構中的第三個限制。
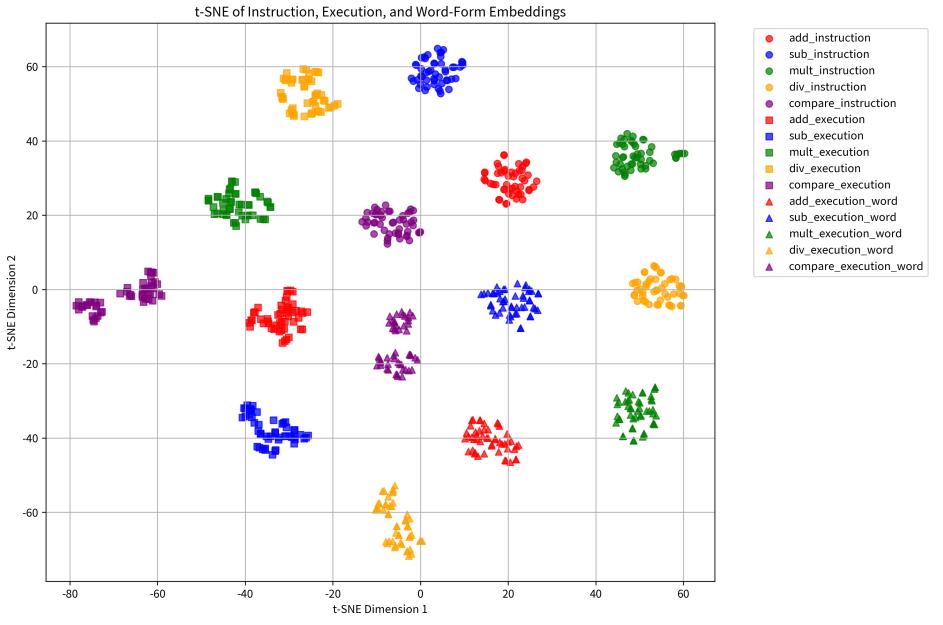
以豎式乘法爲例:人類執行時需要按位對齊、逐位相乘、記錄部分積、最後求和——這是一套完整的符號計算算法。大模型可以將這個算法背得爛熟,甚至能夠教授給兒童,展現出完美的“理解”能力。
但是,當輪到自己執行時,大模型依然只是在做擬合,無法自動調用已學會的算法。
問題的根源在於訓練目標的無差別性。對於下一個 token 預測而言,算法描述和具體計算實例都只是需要預測的文本序列,訓練過程不存在將兩者自動綁定的機制。換句話說,“算法知識”和“執行能力”在模型內部佔據着不同的表徵空間。
(來源:https://arxiv.org/pdf/2507.10624)
這種分離是結構性的:大模型天生無法將抽象算法自動匹配到具體實例。指令理解和執行實現在幾何空間上的分離,正是“計算裂腦綜合徵”的根本原因。

何時用大模型,何時不用大模型
張崢指出,這篇論文揭示了一個根本性問題:這種“計算裂腦”現象具有普遍性——無論數值計算還是邏輯運算,只要涉及符號計算和算法應用,都會出現這一問題。“理論上可能不存在可解釋的神經計算迴路,至少當前的通用大模型沒有,只有一些抽象的統計規律。”
這帶來了深刻的可解釋性問題。大模型自我生成的解釋(如思維鏈)以及機制可解釋性研究,從理論上說都可能是"不忠實的",存在訓練路徑依賴。在當前 Transformer 架構下,這個問題是結構性的,需要根本性創新而非漸進式改進。
這一發現對高風險應用意義重大。在醫療診斷、法律分析等關鍵領域,不應將大模型作爲獨立推理系統,而需要"腳手架"、外部驗證或混合架構支持。
那麼,張崢希望這篇論文帶來怎樣的影響?首先是讓大家明確何時能用、何時不能用大模型。
“大模型的工具調用歷來被視爲效率優化,但這篇論文指出:工具調用不是可選項,而是架構必需。”這種認知轉變帶來新挑戰:攻擊面大幅增加,同時面臨關鍵的元認知問題——大模型需要準確判斷何時調用工具,避免多步調用中的累積錯誤。
張崢還提醒可解釋性研究者:狹窄範圍內的可解釋性研究缺乏泛化性。一旦構建通用大模型,這些研究基礎可能完全失效。
“既要認識大模型的強大,也要認識其侷限。”以 AI+Science 爲例,大模型無法學會可泛化的理論公式。“如果模型無法通過觀察推導普適定律或可泛化的算法,就不具備真正智能。大模型刷榜意義不大,關鍵是完成科學研究閉環。”他說。
這項研究的深層意義在於爲下一代智能系統指明方向:需要元認知腳手架、提升表示能力、原則性執行的架構支持——能夠推理而非僅僅反應的系統。
當前約束似乎不可避免:上下文平均化源於多樣化語料預測,前饋網絡被迫進行模式組裝而非原則計算。計算裂腦綜合徵將持續存在,除非通過根本性架構創新解決。

“我只是一個好奇心很重的研究者”
對於自己在當前 AI 領域的角色定位,張崢表示自己只是一個好奇心很重的研究者,他說自己當然希望 AI 能夠蓬勃發展,但也希望國內 AI 圈不要過於聚焦刷榜,不要總是圍繞一個小補丁做改進。他說:“我還是希望大家冷靜地回到一些貌似很簡單但深挖下去很有趣的問題上,沉下心做一些比較基礎的研究。”
如果說寫這篇論文是爲了帶給大模型領域一些新的思考,那麼作爲一名曾在上海紐約大學教過書的老師,張崢也於 2025 年春天啓動了一個獨特的嘗試:用大模型來教大模型做課程。他說這是一個"活"的課程,可以根據最新的研究成果來翻新課程,同時可以成爲科研從業者的很好的老師。總之,作爲中國 AI 研究領域的前輩,他還將繼續行走下去,“可以做、值得做的問題太多了。”他說。
參考資料:
1.https://zzhang-cn.github.io/
2.https://arxiv.org/pdf/2507.10624
3.https://github.com/zzhang-cn/LLM4LLM/
4.https://www.goodreads.com/user/show/50187028-zheng-zhang
運營/排版:何晨龍



