

Next Gen
歡迎來到“Next Gen”。人工智能的邊界每日都在被拓展,一羣富有遠見卓識的青年學者正站在浪潮之巔。我們追蹤並報道這些 AI 領域最具潛力的明日之星,展現他們在科研前沿的突破性工作,以及對未來智能時代的獨到見解。他們是誰?他們如何思考?他們又將把 AI 帶向何方?與我們一同發現那些正在定義未來的 AI 新生代。
今年 24 歲的王禹來自安徽蕪湖,他本科畢業於中國科學技術大少年班,目前在美國加利福尼亞大學聖迭戈分校(UCSD)三年級博士在讀,並曾在 IBM、亞馬遜等公司實習。

圖丨王禹(來源:王禹)
近期,他發佈了多智能體個人助理系統 MIRIX,這是一款創新的記憶系統產品。MIRIX 具備處理高分辨率的屏幕截圖的能力,這是現有記憶系統無法做到的,其適用於 AI 助理公司、Agent 框架、垂直 SaaS、自動化辦公系統、AI 客服、代碼智能體等多個領域。目前,王禹正在推進公司的創立籌備工作。

曾經每天只睡 6 小時,只爲“柳暗花明”的時刻
截至目前,王禹已在機器學習領域累計發表 20 餘篇學術論文,其中 11 篇爲第一作者或共同第一作者成果。其研究呈現出明顯的聚焦性和延續性,特別是在近兩年的 5 篇第一作者論文中,他系統性地探索了“大模型記憶機制”這一前沿方向,其創新性工作在不增加 GPU 內存開銷的前提下,顯著提升了大規模語言模型的記憶能力。
王禹選擇這一研究方向源於對 ChatGPT 等大語言模型的實際使用觀察。他在日常使用中發現兩個顯著痛點:
首先,模型存在會話記憶的時效性缺陷——當日對話內容在次日即完全丟失,這對需要連續數日討論的項目造成嚴重阻礙,用戶不得不反覆複述項目背景信息;
其次,模型在長程對話中會出現性能衰減現象,隨着上下文累積,後續應答質量逐步降低。這種侷限性迫使用戶頻繁開啓新對話,而新對話又完全無法繼承歷史會話的認知狀態,導致多輪對話間形成記憶斷層。
這些實踐中的發現促使王禹系統性地探索機器記憶的實現路徑。他向 DeepTech 解釋說道:“構建真正具備社會適應性的智能體,記憶系統是不可或缺的底層能力。這種記憶不僅要實現事件記錄的存儲功能,更需要發展出類似生物體的自主記憶機制。從技術演進角度看,記憶模塊很可能是實現通用人工智能(AGI)或構建未來數字人的關鍵架構要素。”
回顧科研歷程,王禹用“堅韌、自律、不達目的誓不罷休”來形容自己的特質。這種執着和熱愛的特質早在本科階段便已顯現:大二時,他的第一個項目是做推薦系統的去噪。但實際上,項目進展並不順利,他曾連續一個多月沒有任何進展。轉折點出現在一次其師兄的項目分享會,受到啓發的他回到宿舍連續兩天高強度推導公式,並大量驗證實驗,最終完成了項目。
這段經歷成爲他投身機器學習研究的起點,尤其是當他發現模型在下棋方面竟然能夠戰勝自己時,那種震撼讓他至今難忘。此後他的研究興趣從強化學習逐步拓展到推薦系統,再延伸到當前專注的自然語言處理領域。
在科研方法論方面,王禹形成了獨特的工作節奏。本科期間他曾創下同時推進 4 個科研項目、日均僅睡 6 小時的記錄。面對高強度工作壓力,他發展出一套有效的壓力管理方式:通過健身房力量訓練、游泳、足球等體育運動,以及與朋友聚餐等社交活動來保持身心平衡。
“項目研究經歷讓我深刻體會到,科研很多時候都是處於高壓、‘山重水複疑無路’的狀態,但一旦出現‘柳暗花明’的時刻,就會覺得之前的努力都是有意義的,這也是科學研究的魅力所在。”王禹回憶道。
王禹的學術成長得益於兩位重要導師的指導。本科階段,中國科學技術大學何向南教授安排博后辛鑫專門指導,並建立每兩週一次的定期彙報機制,這種“手把手”的科研訓練極大地帶領了科研“新手”快速成長。
攻讀博士學位期間,導師朱莉安·麥考利(Julian McAuley)教授給予的學術自由則讓他能夠深耕感興趣的研究方向,同時靈活安排研究計劃以兼顧學業與個人生活,特別是維繫與國內女友的異地戀情。這種張弛有度的培養模式,既保證了系統的科研訓練,又保留了學術創新的自主空間。
2022 年 ChatGPT 系列模型的橫空出世成爲王禹科研生涯的關鍵節點。此前他長期困擾於人工智能技術在實際應用中的精度瓶頸,對技術商業化方向感到迷茫。GPT 展現的強大能力不僅解答了他的技術困惑,更清晰地指明瞭人工智能產品的落地路徑,直接啓發了他後續的創業規劃。

如何讓 AI 擁有類人記憶?
人們希望大模型或機器人可以具備類似人類記憶,那麼人類記憶具備怎樣的特質呢?在探索這個方向時,王禹的此前研究提供了重要啓示。
在他作爲一作發表在 Transactions on Machine Learning Research 的論文《邁向生命週期認知系統》(Towards LifeSpan Cognitive Systems)中提到 [1],從記憶應用的初始階段來看,要做一個能夠“終身對話”的系統需要具備兩個關鍵能力:抽象與經驗合併(Abstraction & Experience Merging)以及長期記憶保持(Long-Term Retention)。
首先,系統不應像傳統存儲系統那樣機械地記錄原始數據,而是需要像人類記憶一樣,能夠提取核心信息並建立關聯。
例如,多次接觸“某人考試失利”相關信息後,系統應能整合這些經驗,推導出“考試難度”等更高層次的結論——這種動態的知識整合能力,正是記憶系統區別於普通 RAG(Retrieval-Augmented Generation)或 RUG(Retrieval-Useful Generation)系統的關鍵特徵。
其次,系統必須長期保留這些抽象後的知識,既包括常識性記憶,也需支持精準細節的調取,這是實現終身認知功能的基礎。
圖丨記憶智能體應該具備的四種互補能力(來源:arXiv)
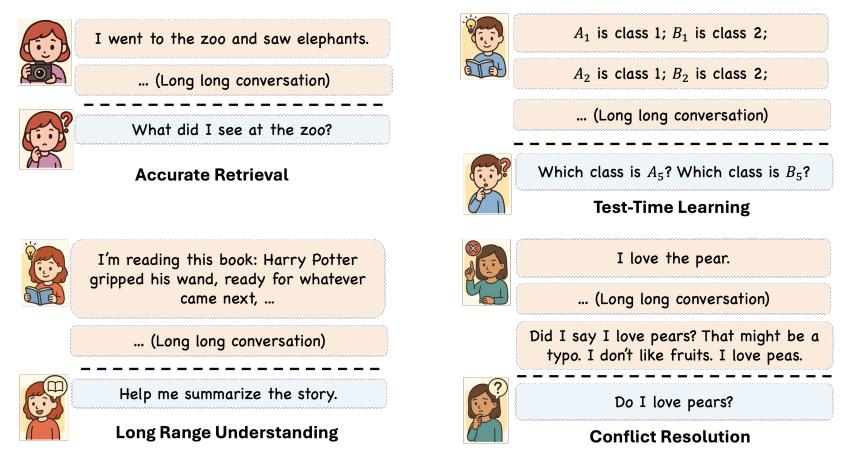
在最近發表在 arXiv 的論文《通過增量式多輪交互評估大語言模型智能體的記憶能力》(Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions)[2] 中,王禹進一步細化了記憶智能體應具備的四大能力:精準回憶(Accurate Retrieval)、傳導學習(Test-Time Learning)、長距離理解(Long-Range Understanding)和衝突解決(Conflict Resolution)。
王禹指出,這四項能力覆蓋了實際應用中的主要需求,也是人類記憶系統的核心功能。這些研究不僅揭示了大模型記憶機制的優化方向,也爲 MIRIX 等系統的開發和設計奠定了理論基礎。

MIRIX:準確率提升 35%,存儲需求降 99.9%
MIRIX 作爲新一代多智能體記憶系統,通過截屏理解用戶,能壓縮並提取有效信息。
其技術架構和功能設計在近期發表在 arXiv 的論文《MIRIX:面向基於大語言模型的智能體的多智能體記憶系統》(MIRIX: Multi-Agent Memory System for LLM-Based Agents)中得到了系統闡述 [3]。

圖丨相關論文(來源:arXiv)
該系統突破了傳統記憶系統簡單劃分短期/長期記憶的二元模式,創新性地構建了六個模塊協同的樹狀記憶架構。每個記憶模塊不僅實現獨立功能,還通過屬性化組織方式(包括總結、嵌入、細節、關鍵詞、執行者等元數據標籤)實現信息的結構化存儲與關聯。
“我們的系統不僅能看到當前屏幕,還能通過六個模塊管理記憶,由專門的代理進行操作,從而記住之前的內容。”王禹說。
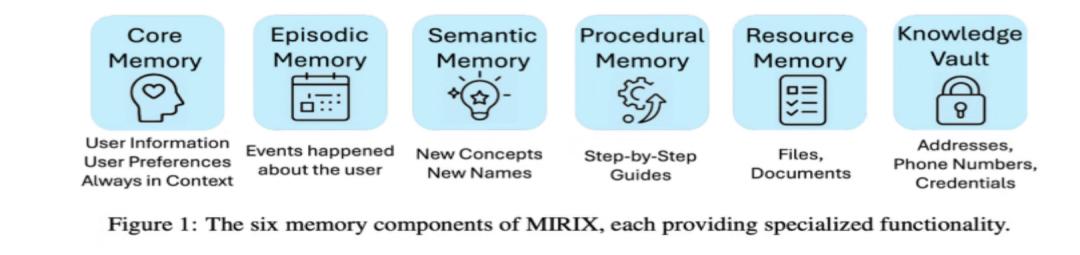
圖丨 MIRIX 的六個記憶模塊,每個提供專門的功能(來源:arXiv)
具體來說:
核心記憶(Core Memory)模塊:記錄用戶的基本信息和偏好,比如用戶的名字、喜好等。這些信息對於與用戶的交流至關重要,需要一直存儲在系統提示(system prompt)和上下文(context)中。
情景記憶(Episodic Memory)模塊:記錄用戶生活中發生的具體事件,比如之前開過的會議、打過的電話等,這些記憶通常與時間相關。
語義記憶(Semantic Memory)模塊:存儲與時間無關的信息,例如“《哈利·波特》是 J.K. 羅琳(J.K. Rowling)寫的”這樣的事實性陳述。這些信息是長期存在的,還包括一些概念、人物等。
(來源:arXiv)
程序記憶(Procedural Memory)模塊:包含各種逐步指南(step-by-step guides)和工作流程(workflows),比如如何在 GitHub 上合併分支、如何在 Minecraft 中調用服務等。
資源記憶(Resource Memory)模塊:用於存儲文件和文檔,比如查看一個文檔、合同等。這些內容不適合存儲在前面四個模塊中,而是專門存儲在資源記憶中。
知識庫(Knowledge Vault)模塊:存儲敏感信息,如地址、電話號碼、憑證、社會安全號碼或身份證號碼等。這些信息在需要時會被使用,例如填寫表格時需要提供身份證號碼。
需要了解的是,MIRIX 重視數據安全方面的保護,其所有的信息都存儲在本地的一個文件夾裏(SQLite 數據庫),所有的處理也都在本地完成。而涉及到上述比較敏感的信息時,MIRIX 會將其單獨存放,並且在需要使用時會徵求用戶的同意。據介紹,只有當數據被髮送至 API 模型時會被 API 模型看到。
值得關注的是,論文中提到,MIRIX 中的反思代理(reflection agent),點擊該功能後會調用後端代理來組織記憶。
例如,John 最近在爲期末考試做準備,過了幾天又說他很累,還沒睡好。MIRIX 會把這些信息連接起來,形成一個新的記憶,記錄在其記憶系統中,比如“John 最近可能正在經歷考試焦慮,智能體在對話中應給予更多支持”。
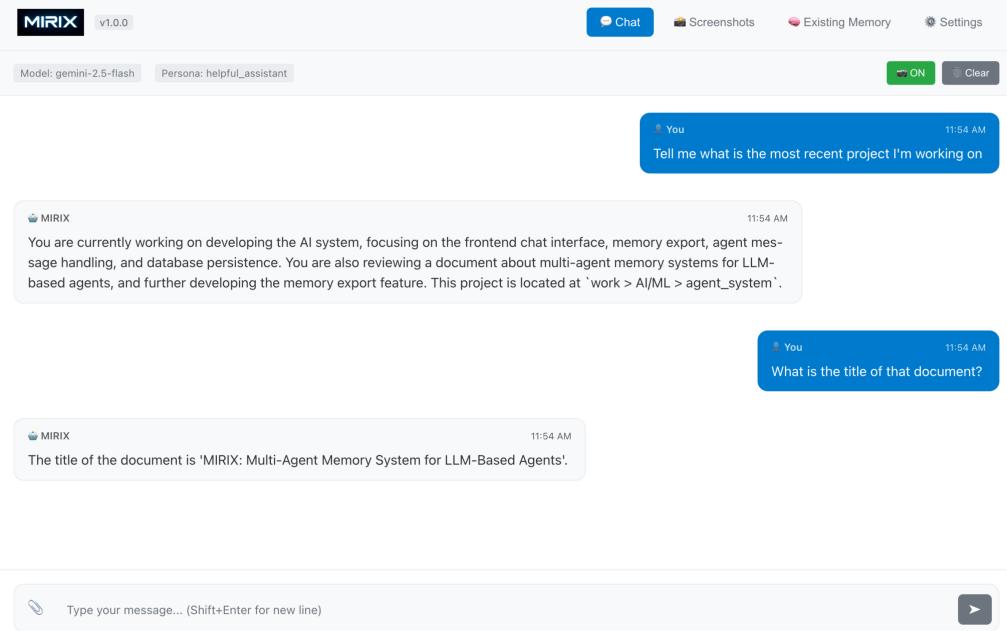
圖丨MIRIX 對話界面(來源:王禹)
研究團隊在兩個具有挑戰性的場景中驗證了 MIRIX。首先,在多模態基準測試 ScreenshotVQA(包含近 20,000 張高分辨率計算機截圖)上,需要深度上下文理解,MIRIX 的準確率比 RAG 基線高出 35%,同時將存儲需求減少了 99.9%。
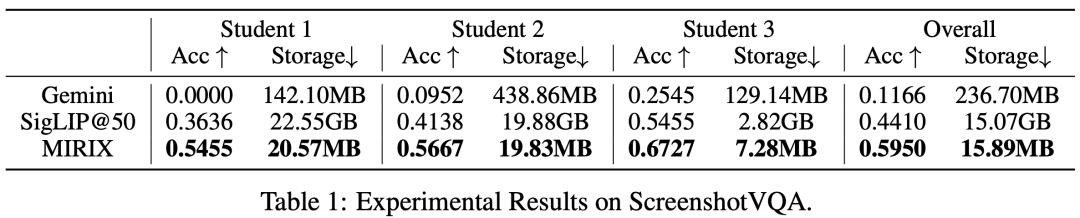
圖丨屏幕截圖 ScreenshotVQA 數據集中的評分(來源:arXiv)
其次,在單模態文本輸入的長篇對話基準測試 LOCOMO 上,MIRIX 達到了超 85% 的最新性能,遠遠超過了現有的基線。
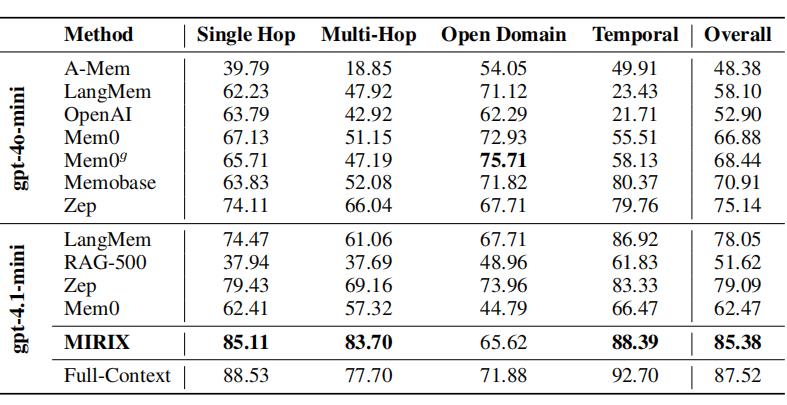
圖丨LOCOMO 數據集中各題型不同記憶系統評分(來源:arXiv)
MIRIX 的系統應用場景覆蓋範圍廣泛,既可以應用於 C 端,也可以應用於 B 端。
對於 C 端,目前王禹與團隊已開發了測試版 APP,比如可以讓它告訴用戶“昨天做了什麼”,或者幫助寫一封求職信。此外,MIRIX 還可以和用戶一起追劇,並討論相關劇情。如果用戶同時在處理多個工作項目,它還可以幫助梳理每個項目的具體進程。
對於 B 端,團隊計劃與 AI 眼鏡廠商、AI 平板廠商、AI 玩具廠商或者小型機器人廠商合作,希望爲其產品增加長期記憶功能,讓產品能夠記住用戶,成爲個人助手,有望真正實現“你的生活記憶,從此不會丟失”。
此外,MIRIX 還有望將各種場景的記憶結合中,但可能需要進行一些適配和專門的調整。王禹進一步說道:“未來,可穿戴設備的個人 Agent 與電腦、手機的個人 Agent 可以是一體化的,它們都能夠訪問用戶的信息,並且共享內存,我覺得這會是一個非常有趣的場景。”
談及科研和開發產品方面,王禹認爲,最重要的是需要耐心打磨。“用戶對於半成品可能只是淺嘗輒止,不會長期使用。我們希望打造能夠留住用戶的產品。科研也是如此,只有提供最好的技術內容,纔會有人關注。”
目前,王禹正在與各投資人洽談中,希望在不久後在美國成立公司並持續推動 MIRIX 等產品的發展。當然,他也不排除未來機會合適將業務拓展到中國。
參考資料:
1.https: //openreview. net/ forum? id= LZ9FmeFeLV
2.https://arxiv.org/abs/2507.05257v1
3.https://arxiv.org/abs/2507.07957
運營/排版:何晨龍



