

AI 在醫學領域終於能做生成式任務了,而且並不是簡單的分類任務。這次,它成功將最常規的病理切片,“翻譯”成原本昂貴而稀缺的免疫檢測圖像。
“我們用更便宜易得的病理圖片,通過 AI 生成了更昂貴耗時的免疫組化圖片,這是癌症免疫療法領域的里程碑工作之一,可能會極大加速癌症的臨牀檢測流程。”談及這項發表在 Cell 的論文,美國華盛頓大學王晟教授對 DeepTech 如是說。

圖丨王晟(來源:受訪者)
近期,微軟研究院潘海峯博士、華盛頓大學王晟教授團隊合作,開發了一種 AI 框架 GigaTIME,基於多模態 AI 技術,實現了將醫院中常規的癌症病理切片(H&E 染色)轉化爲多通道免疫熒光(mIF,multiplex immunofluorescence)。
該研究不僅展示了從 H&E 生成 mIF 圖片的可能性,更重要的是,基於虛擬圖片實現了下游的臨牀發現:研究人員將 GigaTIME 應用於 1.4 萬餘名病人的 H&E 圖像中,這些數據來自美國最大的醫療機構 Providence Health,共包括美國 7 個州、51 家醫院和 1,000 多家診所。
研究人員一次性生成了近 30 萬張虛擬 mIF 全切片圖像,涵蓋 24 種癌症類型和 306 種亞型。憑藉這些空前規模的數據,研究人員系統地揭示了 1,200 多個蛋白質和生物標誌物(如 TP53、KRAS 突變、TMB、MSI 等)、病理分期(TNM 分期)與具體癌症及亞型的關鍵聯繫。
這些數據有助於理解腫瘤免疫逃逸的機制,並首次基於此預測病人生存時間和初步評估免疫療法的藥效。目前,研究團隊已公開預訓練的 GigaTIME 模型代碼,爲腫瘤微環境大規模建模、臨牀生物標誌物發現及精準免疫治療方面提供了新的思路。
相關論文以《多模態人工智能生成腫瘤微環境建模的虛擬人羣》(Multimodal AI generates virtual population for tumor microenvironment modeling)爲題發表在 Cell[1]。

圖丨相關論文(來源:Cell)
當病理圖像學會“翻譯”另一種檢測
H&E 染色作爲臨牀常規病理檢查的基礎技術之一,其優勢是成本低且應用範圍廣泛,即便欠發達地區也能實現,但它的侷限性在於細胞形態和組織結構。
相對而言,mIF 是一種多重蛋白質空間表達信息的金標準技術,儘管其能夠準確反映癌症病人狀態,但因成本高和通量低難以大規模應用。目前,只有極少數發達國家、頂尖醫院才配備 mIF。
從檢測技術價格來看,一個顯著對比是:病理圖片僅需要 20-50 美元,從切片、染色、封固全流程最快半天完成;由於人力與試劑成本高,免疫熒光/免疫組化相關檢測通常需要 1,500 美元,用時至少 5 天。
臨牀中的一個長期的“惡性循環”是:因爲不瞭解 mIF 圖像到底在哪類病人、哪種蛋白質、哪種癌症上有用,所以臨牀上不會花幾千美金做 mIF 檢測;因而做 mIF 檢測的病人數量很少,更難收集大規模數據;沒有數據,又反過來不知道哪裏有用。
這項研究始於 Providence Health 提出的實際臨牀需求:是否有可能將低成本的 H&E 圖像生成更高價值的 mIF 圖像?
此前,病理專家基於醫學圖像推斷病人腫瘤狀態:如果只有便宜的醫學圖像,需要資深專家才能基於此進行推斷;而一旦有了高價值、更清晰的醫學圖像,普通專家甚至剛入門的病理醫生也能做出準確判斷。
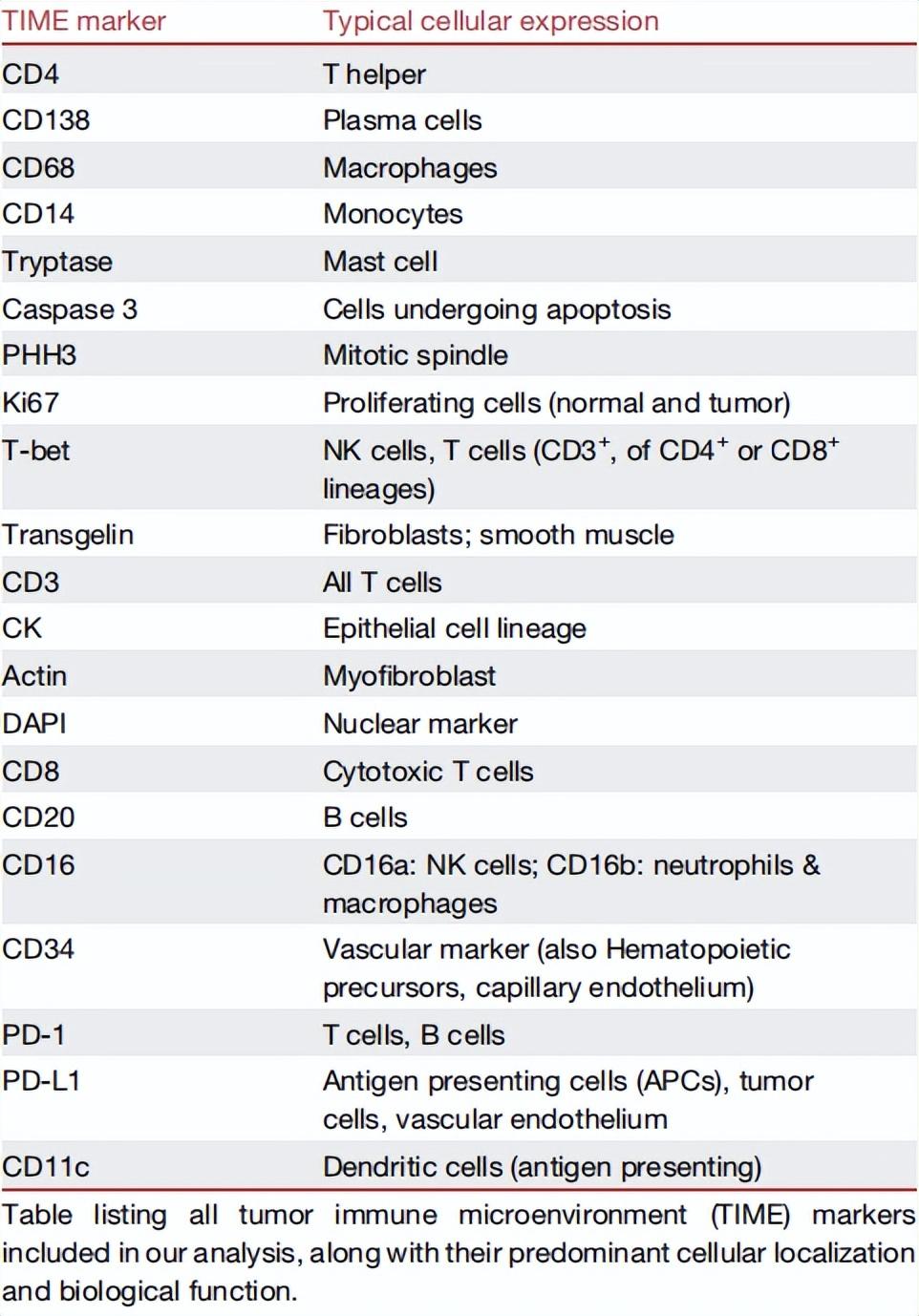
表丨本研究中使用的 TIME 標記物及其細胞表達(來源:Cell)
跨模態翻譯模型是 GigaTIME 的核心所在。基於深度學習算法在不依賴昂貴試劑和複雜設備的條件下,將 H&E 染色切片轉化爲高分辨率的虛擬的 mIF 圖像。研究人員對 4,000 萬細胞的配對 H&E 和 mIF 數據進行訓練,涵蓋了 21 種蛋白質通道。
多模態 AI 技術的最大優勢,是讓模型同時“喫透”不同模態的數據,實現數據利用效率最大化,而不是給每種模態單獨訓一個模型。也就是說,各模態間共享的特徵信息能同時被遷移。
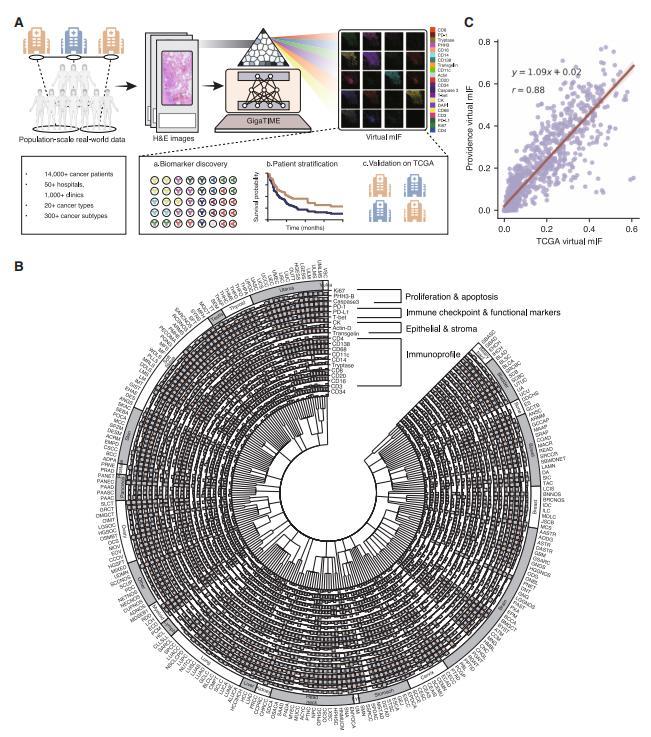
圖丨 GigaTIME 實現羣體規模腫瘤免疫微環境分析(來源:Cell)
此外,GigaTIME 的虛擬人羣可根據虛擬蛋白質的激活狀態,支持對病理階段和病人分層的系統性研究,並預測病理分析與生存期。
通過整合所有 21 個虛擬蛋白質通道,GigaTIME 能夠更有效地對病人進行分層,預測癌症分期和生存結果。傳統病理指標只能靠 H&E 圖像分層,而這項研究使用的虛擬 mIF 圖像分層是傳統手段無法實現的。
從泛癌水平角度,GigaTIME 發現腫瘤大小(T 階段)與免疫檢查點標記物(如 PD-L1 和 PD-1)以及免疫浸潤標記物(如 CD68 和 CD138)呈正相關。
研究人員進一步在特定癌種和亞型水平進行了深入研究。即便虛擬 mIF 是從 H&E 生成,其分層效果仍優於真實的 H&E 圖像。未來某些癌症亞型可能繼續用便宜的真實 H&E 分層更好,但在另一些亞型上,用虛擬的 mIF 圖像分層效果更佳。
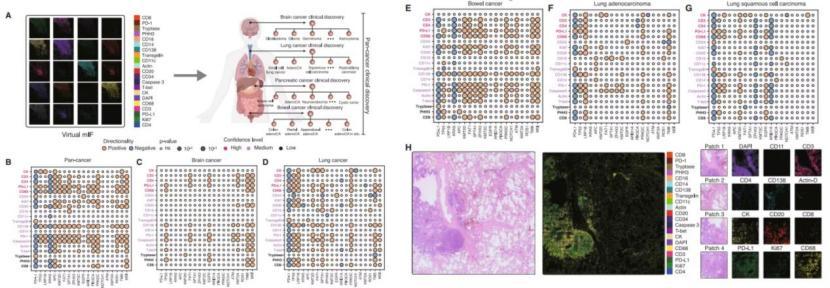
圖丨 GigaTIME 在泛癌、癌症類型及癌症亞型水平上鑑定新型 TIME 蛋白與生物標誌物的關聯(來源:Cell)
“我們並非要全盤取代傳統指標,而是爲不同亞型、不同人種、不同病人提供另一種分層工具,以補充現有臨牀分層的不足。”王晟表示。
此外,GigaTIME 還揭示了蛋白質激活之間的協同作用。通過結合漿細胞標記物 CD138 和巨噬細胞標記物 CD68 的虛擬激活,研究人員發現,該組合與多個生物標誌物的關聯強於單獨的蛋白質。這種協同作用有可能反映了抗體介導的免疫反應,其中漿細胞產生的抗體可激活巨噬細胞攻擊腫瘤細胞。
30 萬張虛擬 mIF 圖像,是如何被“算”出來的?
研究團隊在數據預處理方面投入了大量精力。由於使用的是臨牀真實病人數據,而不是爲研究特意新建的數據集,因此必須從醫院現有病歷裏篩出“高質量、多樣化、又不過於罕見”的病例。同時,圖像本身還要統一染色、去噪、對齊等。
研究人員發現,此前領域內只有簡單數細胞,但這些遠遠不夠,更關鍵的圖像層面空間特徵仍然空白。
爲此,他們搭建了一整套科研流程,並加上了數據、模型、驗證的相關指標。“我們直接借用了傳統圖像領域已被反覆驗證、久經考驗的空間指標,首次把它們搬到免疫圖像分析裏。通過大量實驗和摸索捋順了這套預處理流程,未來從事該方向的研究人員可以直接沿用。”王晟表示。
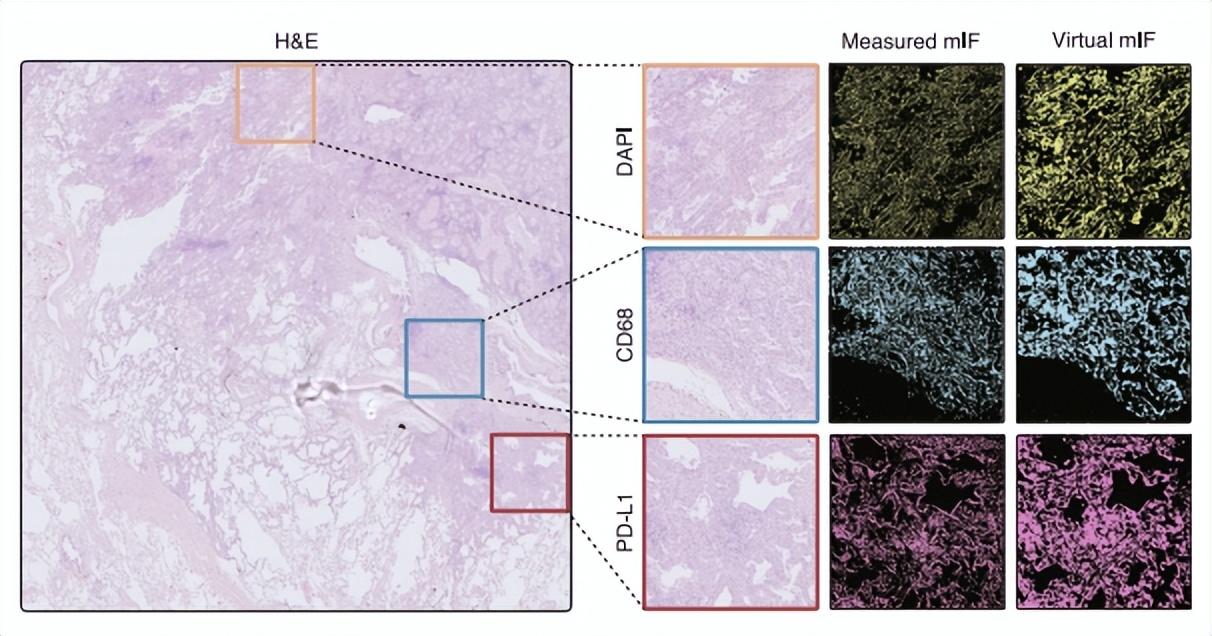
圖丨 GigaTIME 支持 H&E 圖像向 mIF 圖像轉換(來源:Cell)
另一方面,將訓練好的 AI 模型應用到 1.4 萬餘名病人,並一次性生成 30 萬張虛擬 mIF 圖像也帶來了不小的挑戰。爲解決 GPU/CPU 資源大量消耗的問題,研究人員進行了大量純工程層面的並行優化,將生成周期壓到 1-2 個月,並使用了微軟研究院提供的海量計算集羣。
GigaTIME 相當於用簡單圖像學習出複雜圖像,就像搭起了一座橋樑,通過爲初級病理醫生提供高價值圖像參考,縮短其從初級到專家的學習和經驗累積週期。
“得益於生成式 AI 近年來的發展和進步,我們把海量真實的成對數據餵給 AI 模型,再用生成式 AI 技術把模型建起來,這個全新的醫學問題纔有了這種新的方案。”王晟表示。
數據規模帶來的直接影響是,臨牀流程因此顯著降低了成本。研究團隊用 AI 虛擬手段打破了傳統的“惡性循環”:生物學家和醫生在得到這些關鍵信息後,相當於可“按圖索驥”大致判斷哪些蛋白質可能關鍵,有了突破後再針對特定的蛋白,用較低的成本補做真實的 mIF 檢測以及深入挖掘。
比如,當醫生髮現某些蛋白質在肝癌中具有關鍵作用,就大規模給肝癌病人上真實 mIF,同時配合虛擬圖像,真實數據量隨之暴漲,最終讓 mIF 變成臨牀常規技術。
用虛擬圖像開啓“數字試驗”新範式
王晟指出,虛擬細胞、虛擬圖片方向的 AI 技術,並不會取代醫生或取代生物學家。AI 承載的使命並不是從頭到尾地“包辦”新藥開發和科學發現,而是通過生成虛擬病人、虛擬樣本來驗證醫生或生物學家所開發藥物的效果。
用 AI 生成虛擬病人做療效和毒性的驗證,相當於 AI 生成的“數字小白鼠”來做實驗,不僅可以大幅度提高開發效率,也能降低試藥對受試者帶來的損傷。“生成式 AI 更像是一個用於驗證的高通量數字試驗平臺,這也是團隊後續持續推廣的方向。”他說。
此前,領域內只能基於真實的 mIF 數據推斷哪些蛋白質對癌症重要。王晟指出,儘管近 30 萬張虛擬的 mIF 圖像未必像真實圖像那樣完美,但它能清晰地看到蛋白質和癌症之間的顯著關係,這也是這項工作中最大的貢獻之一。
未來,研究團隊希望通過引入更多前沿 AI 技術來生成醫學圖像和病人特徵,來解決更多以往難以解決的問題。
此前,研究團隊在 Nature 報道了數字病理學全切片基礎模型 GigaPath[2],其中針對肺癌的一項指標已在美國紀念斯隆凱特琳癌症中心完成臨牀驗證。本次研究是上以工作的延續,需要了解的是其並非覆蓋所有癌種,從癌症種類來看,這項研究中核心驗證的是肺癌,其次是腦癌和胃癌。
目前,研究團隊正在開展更大規模的跨人種、跨國家的數據驗證,預計數月後會呈現初步結果。後續驗證若持續成功,將繼續擴展到更多國家驗證,並進入臨牀審批等環節。
基於本次 H&E 到 mIF 的跨模態生成技術基礎,他們計劃在接下來的研究中進一步突破模態邊界,打通病理圖片與影像科圖片之間的關聯。其希望未來不僅用 H&E 圖像生成病人的 mIF,還能進一步用 CT、X 光、核磁共振成像這類影像科圖像,配合少量病理圖來更好地生成 mIF。
“即便 H&E 圖像病人也需半天時間,還要打麻藥、取切片。如果能用更簡單的 CT 或核磁圖像,能減少對病人帶來的創傷。”王晟說。
現在,該團隊正致力於構建一個更大的多模態模型,不僅將影像科圖像納入其中,未來還將加入 DNA、基因等更多種類數據,其終極目標是形成能統一理解各種模態生物醫學臨牀數據的超大模型。
這或許預示着,醫學正在從“一次檢測得到一個結果”,走向“一個模型理解整個病人”。
參考資料:
1.https://doi.org/10.1016/j.cell.2025.11.016
2.https://doi.org/10.1038/s41586-024-07441-w
排版:劉雅坤



