

近日,2017 年圖靈獎得主、被稱爲“RISC 之父”的 David Patterson 最近與 Google DeepMind 高級工程師馬曉宇在 IEEE Computer 聯合發表了一篇論文——“關於大語言模型推理硬件的挑戰與研究方向”,引發了科技圈的關注與討論。

(來源:arXiv)
David Patterson,這位 RISC 架構的奠基人、影響了全球 99% 微處理器設計的計算機科學家,在論文開篇就拋出了一個尖銳的判斷:當前 AI 芯片的設計思路,即滿載的算力、堆疊的 HBM(High Bandwidth Memory,高帶寬內存)、帶寬優先的互聯,與大語言模型推理的實際需求嚴重錯配。

(來源:UC Berkeley)
在某種程度上,這可以說是對整個 AI 芯片產業的當頭棒喝。Patterson 在文中直言,LLM 推理正處於危機之中,不是技術上的危機,而是經濟上的。因爲,越來越多的公司們發現,即便擁有最先進的 GPU 集羣,爲最先進的模型提供推理服務依然在大把燒錢。
根據多家媒體報道,微軟、亞馬遜、谷歌、Meta 四大科技巨頭在 2026 年 AI 相關資本總開支預計達到約 6,000 億美元。這一規模相比 2025 年約 3,880 億美元,增長約 50% 以上。
儘管具體數字可能存在分歧,但行業共識是:推理成本正在吞噬 AI 公司的利潤空間。一邊是飆升的成本,一邊是爆炸式增長的需求,這個行業正在經歷一場嚴峻的經濟考驗。
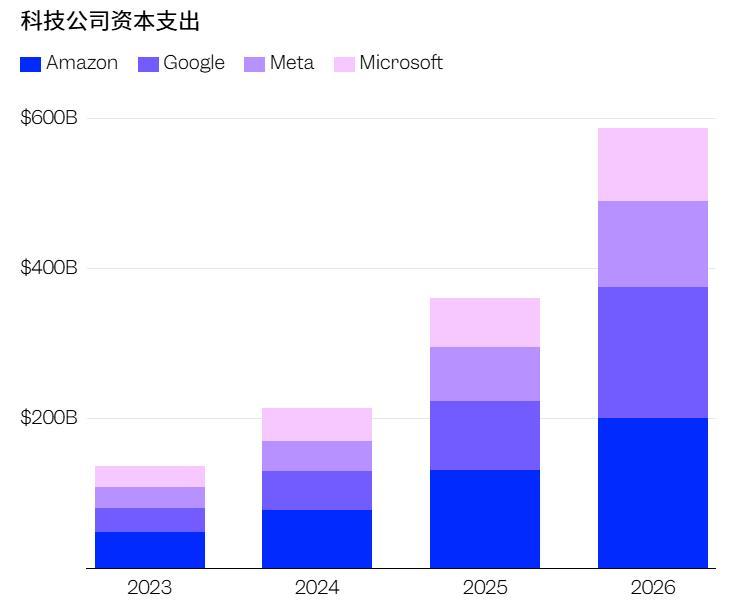
(來源:四家公司財報數據)
對於這個問題,Patterson 和馬曉宇在論文中指出,根源在於 LLM 推理的兩個階段有着截然不同的計算特性。
Prefill(預填充)階段處理輸入序列的所有 token,類似於訓練過程,是計算密集型的,現有 GPU/TPU 可以較好地應對。但 Decode(解碼)階段則完全不同。它是自迴歸的,每一步只生成一個輸出 token,這使得它天然是內存帶寬受限的。
現有的 AI 加速器,從設計之初就是爲訓練優化的,推理只是被當作訓練系統的“縮小版”來對待。結果就是,最昂貴、最強大的芯片,在跑推理任務時可能只發揮了很小一部分能力。
而且讓情況雪上加霜的是,最近湧現的一系列 LLM 新趨勢正在進一步加劇推理的難度。論文列舉了 6 大壓力源:
首先是 MoE(Mixture of Experts,混合專家)架構的興起,以 DeepSeek V3 爲例,它使用了 256 個路由專家,雖然每個 token 只激活其中 8 個,但整個模型的參數量達到了 6,710 億。MoE 雖然降低了訓練成本,卻大幅擴展了推理時的內存佔用和通信開銷。
其次是推理模型(Reasoning Models)的流行,它們在輸出最終答案前會生成大量思考 token,這不僅拉長了生成時間,還讓內存中的 KV Cache(Key Value Cache,鍵值緩存)承受更大壓力。
此外還有多模態的擴展:從純文本走向圖像、音頻、視頻生成,數據量急劇膨脹。長上下文(Long Context)需求的增長同樣帶來計算和內存的雙重壓力;RAG(Retrieval-Augmented Generation,檢索增強生成)通過引入外部知識庫增加了推理的資源消耗;最後是 Diffusion 模型,雖然它與上述趨勢不同,只增加計算需求而非內存,但也代表了推理複雜度提升的又一個方向。
面對這些挑戰,論文將問題歸結爲兩堵“牆”:內存牆與延遲牆。
內存牆的本質是硬件發展的不均衡。Patterson 引用了一組數據:從 2012 年到 2022 年,NVIDIA GPU 的 64 位浮點運算能力提升了 80 倍,但內存帶寬只增長了 17 倍。這個差距還在持續擴大。
更麻煩的是,HBM 的成本不降反升。論文援引花旗銀行的研究數據指出,從 2023 年到 2025 年,HBM 的單位容量成本(/GB)和單位帶寬成本(/GB)和單位帶寬成本(/GB)和單位帶寬成本(/GBps)都上漲了約 35%。這與傳統 DDR DRAM 形成了鮮明對比,後者的成本在同期下降了近一半。
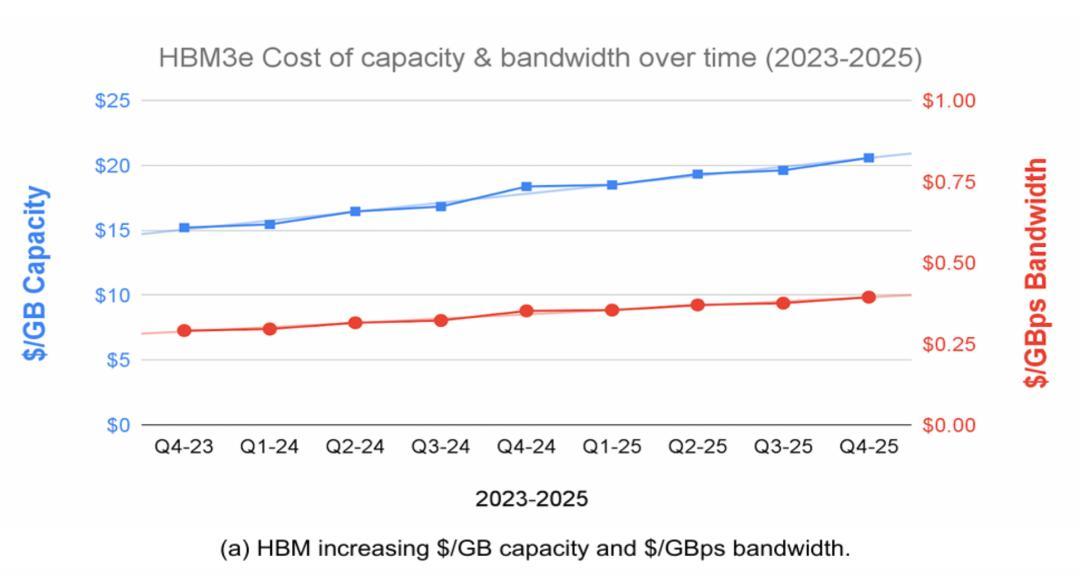
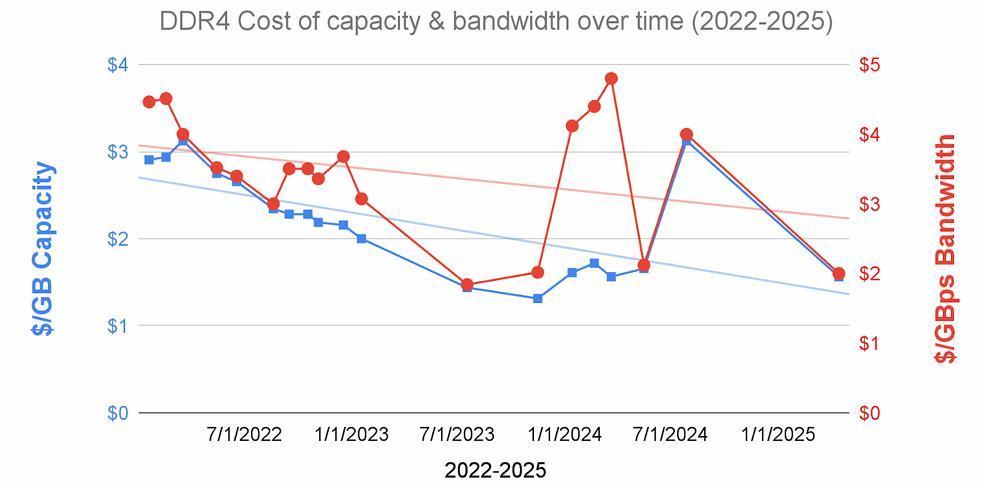
圖 | HBM(上)和 DDR(下)的單位容量成本和單位帶寬成本隨時間變化的趨勢線(來源:論文)
造成這種分化的原因在於製造工藝:HBM 需要堆疊多層 DRAM die,封裝難度隨着堆疊層數和密度的增加而上升,良率問題愈發嚴峻。
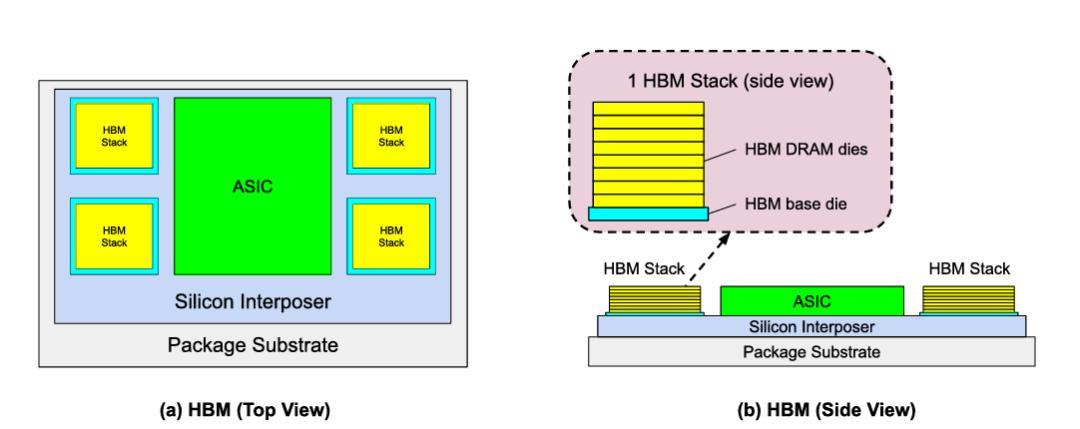
圖 | (a) 高帶寬內存 HBM 封裝俯視圖,(b) HBM 側視圖(來源:論文)
與此同時,DRAM 密度增長正在減速。從 2014 年推出 8Gbit DRAM die 到實現四倍增長,將耗費超過 10 年時間,而之前這一週期只需 3 到 6 年。
有些公司曾嘗試用純 SRAM 的方案繞開 DRAM 和 HBM 的限制,比如 Cerebras 用晶圓級集成堆滿 SRAM,Groq 也採用了類似策略。但 LLM 的參數規模很快就超出了片上 SRAM 的容量,兩家公司後來都不得不加入外部 DRAM 支持。
延遲牆的問題同樣棘手。與動輒數週的訓練不同,推理是實時的。用戶發出請求,期望在幾秒甚至更短時間內得到響應。這意味着端到端延遲至關重要。論文區分了兩種延遲指標:time-to-completion(完成時間)和 time-to-first-token(首 token 時間)。長輸出序列會拉長前者,長輸入序列和 RAG 會影響後者,而推理模型由於生成大量思考 token,會同時拖慢兩者。
過去,數據中心的推理通常在單芯片上完成,只有訓練需要超級計算機級別的集羣。因此,連接這些芯片的互聯網絡主要優化帶寬而非延遲。但 LLM 改變了遊戲規則:模型太大,推理也需要多芯片系統;軟件層面的分片(sharding)意味着頻繁通信;而 Decode 階段的小 batch size 導致網絡消息往往很小。對於這種“頻繁、小消息、大網絡”的場景,延遲比帶寬更重要。
基於這些分析,Patterson 和馬曉宇提出了四個值得研究的方向,試圖重新思考 LLM 推理硬件的設計邏輯。
第一個方向是高帶寬閃存(HBF,High Bandwidth Flash)。這個概念最早由 SanDisk 提出,SK Hynix 後來也加入了開發。它的思路是像 HBM 那樣堆疊閃存 die,從而獲得接近 HBM 的帶寬和 10 倍於 HBM 的容量。論文給出了一組對比數據:單個 HBF 堆棧可以提供 512GB 容量和超過 1,600GB/s 的讀取帶寬,而單個 HBM4 堆棧只有 48GB 容量。
HBF 的弱點在於寫入耐久性有限和讀取延遲較高(微秒級),這意味着它無法替代所有 HBM,但非常適合存儲推理時幾乎不更新的模型權重,或者變化緩慢的上下文數據,比如用於 LLM 搜索的網頁語料庫、用於代碼助手的代碼庫,甚至研究論文庫。更重要的是,閃存容量還在以每三年翻倍的速度增長,這是 DRAM 已經難以企及的節奏。
第二個方向是近內存計算(PNM,Processing-Near-Memory),它與歷史上的 PIM(Processing-in-Memory,內存內計算)概念有所不同。PIM 將計算邏輯直接集成在 DRAM die 內部,雖然帶寬極高,但面臨軟件分片複雜、計算能力受限於 DRAM 工藝的功耗和麪積約束等問題。
DRAM 工藝節點並不適合高性能邏輯電路。PNM 則將計算邏輯放在內存附近但仍是獨立 die,通過 3D 堆疊或高速互聯與內存連接。
論文認爲,對於數據中心 LLM 推理而言,PNM 比 PIM 更實際:它的分片粒度可以大 1,000 倍(GB 級而非 MB 級),邏輯工藝可以獨立優化,且不影響內存密度和成本。不過論文也指出,對於移動設備上的 LLM,由於模型更小、批次更小、能耗約束更嚴格,PIM 的劣勢可能不那麼明顯,反而值得探索。
第三個方向是 3D 計算-邏輯堆疊。與傳統 2D 芯片通過 die 邊緣連接內存不同,3D 堆疊使用垂直的 TSV(Through Silicon Via,硅通孔)實現寬而密的內存接口,可以在更低功耗下獲得更高帶寬。
這個方向有兩種實現路徑:一種是在 HBM 的 base die 上集成計算邏輯,複用現有 HBM 設計,帶寬與 HBM 相當但功耗降低 2 到 3 倍;另一種是定製化 3D 方案,通過更寬更密的接口和更先進的封裝技術,實現超越 HBM 的帶寬和效率。挑戰在於散熱:3D 結構的表面積更小,散熱更難,以及需要建立內存-邏輯接口的行業標準。
第四個方向是低延遲互聯。論文建議重新審視網絡設計中延遲與帶寬的權衡。具體措施包括:採用高連接性拓撲(如樹形、蜻蜓、高維 Torus),減少跳數從而降低延遲;引入網絡內處理(Processing-in-Network),讓 LLM 常用的通信原語(如 all-reduce、MoE 的 dispatch 和 collect)在交換機中加速;優化芯片設計,讓小包數據直接存入片上 SRAM 而非外部 DRAM,或將計算引擎靠近網絡接口以縮短傳輸時間;甚至在可靠性設計上做文章,部署本地備用節點減少故障遷移的延遲和吞吐影響,或者在 LLM 推理對完美通信要求不高時,用假數據或歷史結果替代超時消息,而非等待掉隊者。
Patterson 在論文中還不忘強調個人觀點:他批評了當前學術界與產業界的脫節。1976 年他入行時,計算機架構會議上約 40% 的論文來自工業界,而到 2025 年的 ISCA(International Symposium on Computer Architecture),這個比例已經跌破 4%。
他呼籲學術研究者把握 LLM 推理這個"誘人的研究目標",並建議開發基於 Roofline 模型的性能模擬器,配合現代的性能/成本指標(如 TCO、功耗、碳排放),爲 AI 推理硬件創新提供更實用的評估框架。
當前,全球正經歷一場因 AI 引發的內存供應危機。由於 HBM 生產擠佔了傳統 DRAM 的晶圓產能,2026 年全球 DRAM 價格大幅上漲。三星、SK Hynix 等廠商正將更多資源轉向高利潤的 HBM 產品線,這雖然滿足了 AI 數據中心的需求,卻加劇了消費級內存的短缺。這種供應緊張可能持續到 2027 年甚至更久。
在這種背景下,Patterson 提出的 HBF、PNM 等替代路徑,或許不僅是技術上的探索,也是產業尋找 Plan B 的現實需求。
當然,論文也承認這些方向並非可以一蹴而就的方案。每一個都涉及複雜的工程權衡:HBF 需要解決軟件如何處理有限寫入耐久性和高延遲讀取的問題;PNM 和 3D 堆疊需要新的軟件分片策略和內存-邏輯接口標準;低延遲互聯可能需要犧牲部分帶寬。
論文鼓勵將這些方向組合使用,因爲它們在很大程度上是互補的。更高的內存帶寬可以縮短每次 Decode 迭代的延遲,更大的單節點內存容量可以減少系統規模從而降低通信開銷。
作爲 RISC 架構的共同發明人、RAID 存儲系統的開創者,Patterson 的職業生涯幾乎就是"挑戰現有範式"的代名詞。40 多年前,他和 John Hennessy 提出的精簡指令集思想曾被工業界視爲異端,如今 99% 的新芯片都採用 RISC 架構。
Patterson 和馬曉宇選擇發表這篇論文的方式也很有意思,它不是一篇技術細節密集的頂會論文,而是發在 IEEE Computer 這本面向更廣泛讀者的雜誌上,語氣像是在發佈一封公開信。值得注意的是,他們在致謝中提到了 Martin Abadi、Jeff Dean、Norm Jouppi、Amin Vahdat 和 Cliff Young,這串名字幾乎覆蓋了 Google AI 基礎設施的核心架構師。
參考鏈接:
1.https://arxiv.org/pdf/2601.05047
2.https://techcrunch.com/2026/02/28/billion-dollar-infrastructure-deals-ai-boom-data-centers-openai-oracle-nvidia-microsoft-google-meta/?utm_source=chatgpt.com
運營/排版:何晨龍



