

網上匿名評論或匿名發帖真的是“隱藏”模式嗎?現在,AI 能以九成的精確率扒下你的“馬甲”。並且,整個過程只需要幾分鐘,單次成本僅幾美元。
來自瑞士蘇黎世聯邦理工學院、Anthropic 等機構的研究人員在一項研究中得出了驚人結論:他們在 Hacker News、Reddit 等平臺開展測試後發現,大模型通過匿名賬號的零散帖子,在特定數據集與實驗中能以 90% 的精確率(precision)識別出這些匿名的網絡賬號對應的真實用戶 [1]。
可以將大模型看作一名 AI 偵探。過去,想要獲得匿名用戶的相關信息,通常需要人工花費數小時去翻閱帖子、搜索線索,再進行對比分析。現在,這個 AI 偵探自己就能完成這項任務,還能一次規模化查多個賬戶。你只需要向它提供匿名賬號的相關發言,它就會在幾分鐘後告訴你用戶大概率是誰。
這個研究就是針對 AI 偵探的性能進行的實驗。研究人員開發了四步攻擊流程:特徵身份提取、語義匹配搜索、推理篩選最優候選結果、置信度評分校準。結果表明,在 90% 精確率條件下召回率(recall,指被正確識別出的目標用戶佔比)達 68%。與之對比的是,傳統方法的召回率接近於 0%。

圖丨相關論文(來源:arXiv)
這項研究還警告說,AI 很可能重新識別在網上留下痕跡的用戶,這讓互聯網隱私問題再次成爲人們討論的焦點。
網絡匿名,是一種保護參與話題討論發言者隱私的措施,旨在讓他們能夠暢所欲言。但現在一切都改變了,所謂的“匿名”發帖模式已被 AI 顛覆,你以爲的匿名處處指向“你是誰”。
AI 能以低成本在短時間內,快速找到這些匿名賬戶背後的真實用戶,使後者面臨隱私、人肉搜索以及廣告推銷等風險。這意味着,在論壇上隨口吐槽的內容、家鄉美食、公司工牌、行文習慣……都可能成爲大模型鎖定發言者真實身份的關鍵線索,包括居住地、職業和其他個人信息。
研究人員在論文中提到:“我們的發現對網絡隱私意義重大。長期以來,網民一直遵循防禦假設,他們認爲匿名性足以提供充分的保護,因爲傳統去匿名化方法需要耗費大量精力,還需要投入高成本。然而,大模型推翻了這一假設。”
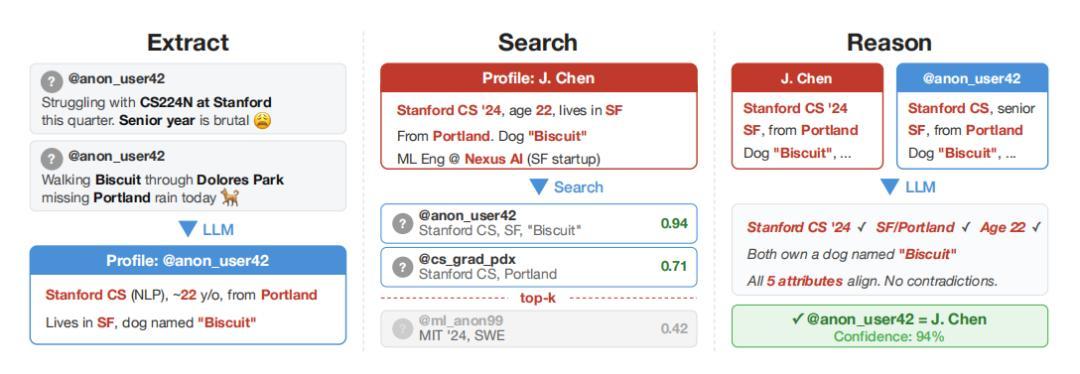
圖丨大規模去匿名化框架的總體流程(來源:arXiv)
爲了驗證技術的有效性,同時保護髮言者的隱私,研究人員從公共社交媒體網站收集了多個數據集。其中,一個數據集收集於 Hacker News 和 LinkedIn 個人資料中的帖子,然後再基於用戶資料中出現的跨平臺引用將它們關聯起來。之後,研究人員從帖子中移除了所有識別信息,並讓大模型開始工作。
第二個數據集來自 Netflix 發佈的用戶身份信息,包括個人偏好、推薦和交易記錄等。從歷史上的去匿名化先例來看,美國德克薩斯大學奧斯汀分校團隊於 2008 年發表的論文中提到 [2],利用 Netflix Prize 技術能夠識別匿名用戶,並確定他們的政治取向和其他潛在的個人信息。
而第三種數據集的構建方式,則是將單個用戶的 Reddit 歷史記錄做時間拆分處理。
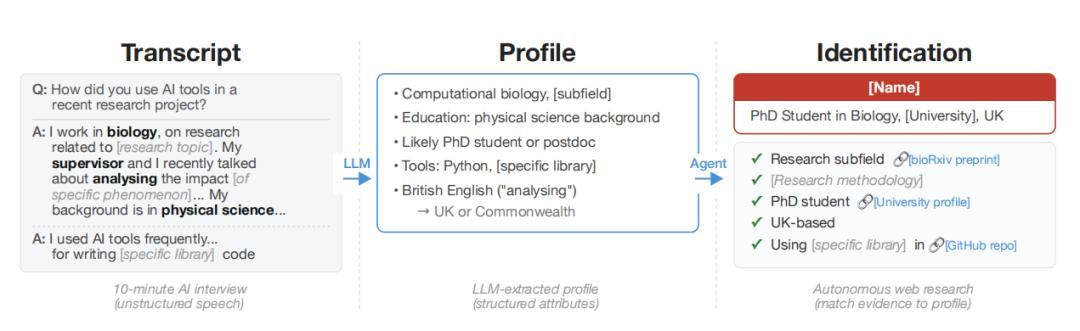
(來源:arXiv)
“我們發現,這些 AI 智能體可以做到以前非常難實現的事情:從自由文本(例如匿名訪談記錄)出發,它們可以逐步還原出一個人的完整身份。”該論文作者之一 Simon Lermen 在接受媒體採訪時表示,“這是一項全新的能力,以前的身份重識別方法通常需要結構化數據,以及兩個具有相似模式且可以鏈接在一起的數據集。”
他指出,與傳統匿名識別方法最大的不同在於,AI 智能體能夠像人類一樣瀏覽網絡、與網絡內容互動,並通過類人推理逐步縮小候選範圍。
爲系統驗證該能力,研究團隊設計了三組實驗。在第一項實驗中,研究人員分析了 Anthropic 公司關於不同人羣在日常生活中如何使用 AI 的問卷調查結果。然後,他們利用這些信息成功識別出 125 名參與者中的約 7%(9 人)。
儘管 7% 的召回率相對較低,但這表明 AI 已實現了能力的跨越:即便信息極其有限且非結構化,大模型也可基於有限信息識別用戶身份。研究團隊認爲,未來隨着 AI 技術的進一步發展,有望越來越擅長識別更多身份。
在另一項研究實驗中,研究人員收集了 2024 年 Reddit 平臺 r/movies 子版塊以及 r/horror、r/MovieSuggestions、r/Letterboxd、r/TrueFilm 和 r/MovieDetails 五個社區中至少一個社區的評論。結果表明,用戶討論的電影越多,就越容易識別出他們的真實身份。
從數據的平均值來看,在分享一部電影的用戶中,AI 能以 90% 的精確率實現去匿名化 3.1%,能以 99% 的精確率識別其中 1.2% 的用戶;當用戶分享 5 到 9 部電影時,90% 和 99% 的精確率對應的識別用戶分別上升到 8.4% 和 2.5%;而當用戶分享超過 10 部電影時,這兩個比例進一步提升至 48.1% 和 17%。
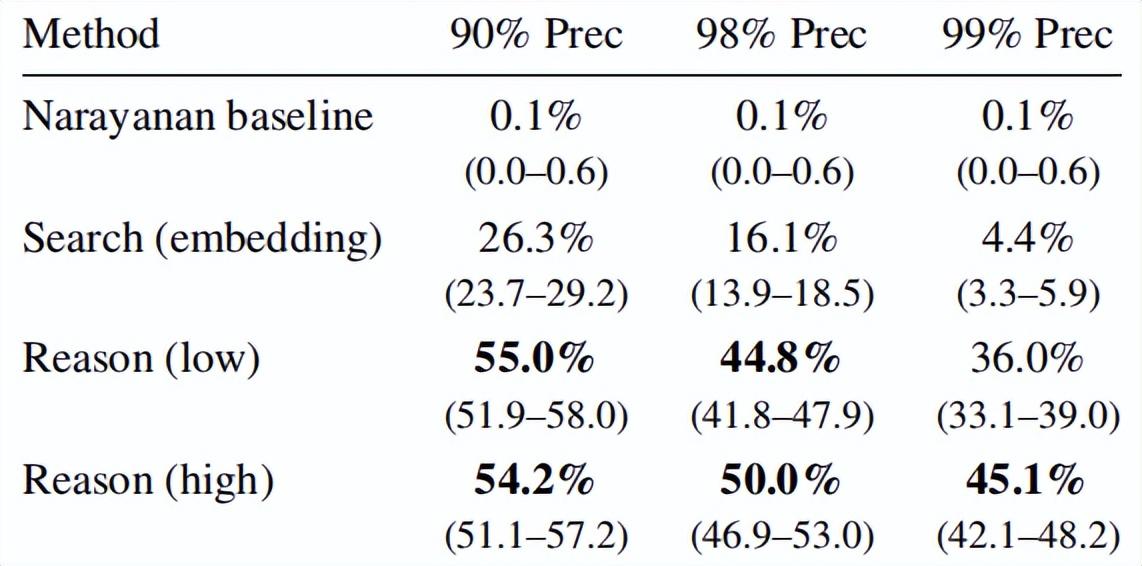
表丨在不同精確率閾值下,HNLinkedIn 跨數據集用戶匹配任務的召回率(共 987 條查詢)(來源:arXiv)
在第三項研究實驗中,研究人員選取了 5,000 名 Reddit 用戶,並對這些用戶添加了“干擾”身份。研究人員將新方法與前文提到的 Netflix Prize 攻擊技術進行比較。
然後,他們向 10,000 個候選用戶列表中添加了 5,000 個查詢干擾項,這些干擾項包含僅出現在查詢集中的用戶,這些用戶在候選池中沒有真正的匹配項。結果顯示,新方法顯著優於模仿 Netflix Prize 攻擊的經典基線。
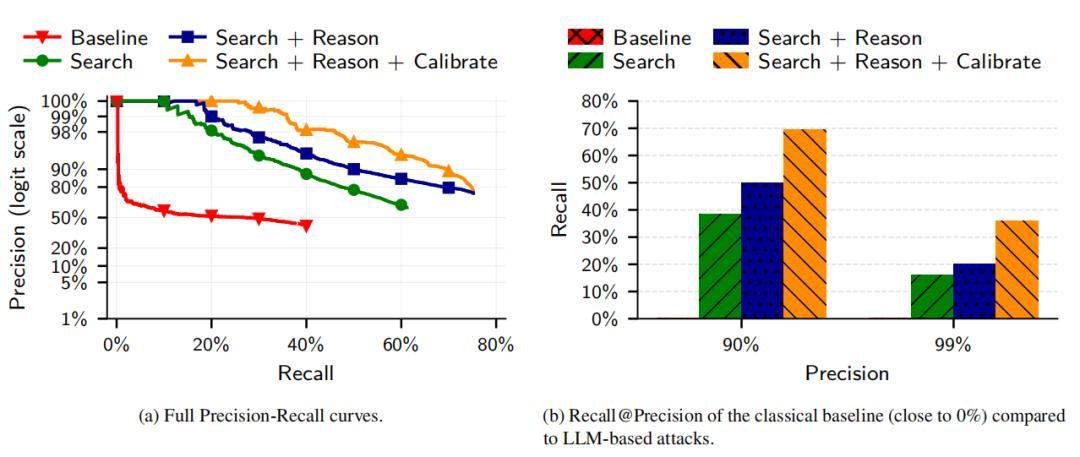
(來源:arXiv)
儘管大模型仍然容易出現誤報和其他缺點,但從結果中可以看出,它在識別在線用戶方面正迅速超越更傳統的、資源密集型方法。隨着大模型在去匿名化方面成功率的提高,政府部門可能會用這些技術揭露網絡不法分子或詐騙人員的身份,企業則可能會利用這種技術進行個性化廣告推薦。
研究人員提出了一系列應對措施,包括平臺應限制 API 對用戶數據的訪問速率、檢測自動抓取行爲以及限制批量數據導出。大模型提供商還可以監控模型在去匿名化攻擊中的濫用情況,並建立防護機制,以讓模型可拒絕去匿名化請求。
這項研究指引我們思考一個新的問題:當你在互聯網的每條痕跡都有可能成爲 AI“扒”出你真實身份的線索,還會選擇繼續匿名發帖嗎?當匿名已從默認安全變爲不安全,對於用戶來說最穩妥的方案是大幅減少使用社交媒體,或者定期刪除帖子來防止那些歷史痕跡被利用。
參考資料:
1.https://arxiv.org/pdf/2602.16800
2.https://arxiv.org/pdf/cs/0610105
3.https://arstechnica.com/security/2026/03/llms-can-unmask-pseudonymous-users-at-scale-with-surprising-accuracy/
運營/排版:何晨龍



