

今年 10 月,當硅谷兩家最火熱的 AI 編程工具公司 Cursor 和 Windsurf 前後腳發佈自己的“首個自研模型”時,整個開發者社區一片歡呼。然而慶祝的聲音還未散去,就有眼尖的網友發現了蹊蹺之處:這些號稱“自研”的模型,在推理過程中竟然會突然冒出中文,甚至有模型在被越獄後直接承認自己來自中國公司智譜 AI。這個發現迅速在社交媒體上發酵,有人調侃道:“這邊一開源,那邊就自研。”那時候,這種借用還帶着幾分遮遮掩掩的羞澀,彷彿借了鄰居的東西怕被發現,總要刷上一層新漆。
但到了昨天,這種遮掩似乎已無必要,甚至演變成了一種理直氣壯的實用主義宣言。
總部位於舊金山的初創公司 Deep Cogito 發佈了其最新一代旗艦模型 Cogito v2.1 671B。公司 CEO Drishan Arora 在社交平臺 X 上豪情萬丈地宣佈:“今天,我們發佈了由美國公司製造的最好的開源大語言模型。”
圖丨相關推文(來源:X)
爲了證明這一點,CEO Drishan Arora 甩出了一組極其漂亮的數據:在 GPQA Diamond 推理測試中,它逼近了 GPT-5;在多語言 MMLU 上,它擊敗了 Claude Sonnet 4.5;在數學和代碼能力上,它把 Meta 引以爲傲的 Llama 系列甩在了身後。看着那些直衝雲霄的柱狀圖,你差點就要相信這是美國開源 AI 的一次反擊。
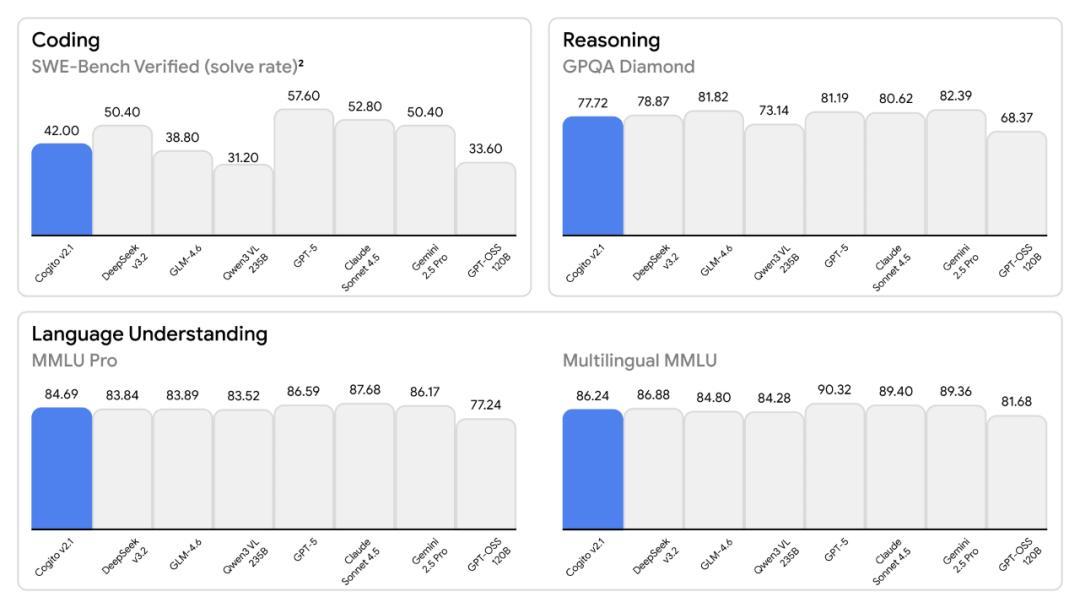
圖丨基準測試結果(來源:Deep Cogito)
其實對於 AI 圈內人來說,看到 671B 這個比較奇特的數字大概就能發現一些端倪了,它恰好就是 DeepSeek-V3 的參數規模
而沒多久之後,網友們就在該模型的 HuggingFace 的配置文件裏發現了一行代碼:“base_model:
deepseek-ai/DeepSeek-V3-Base”。
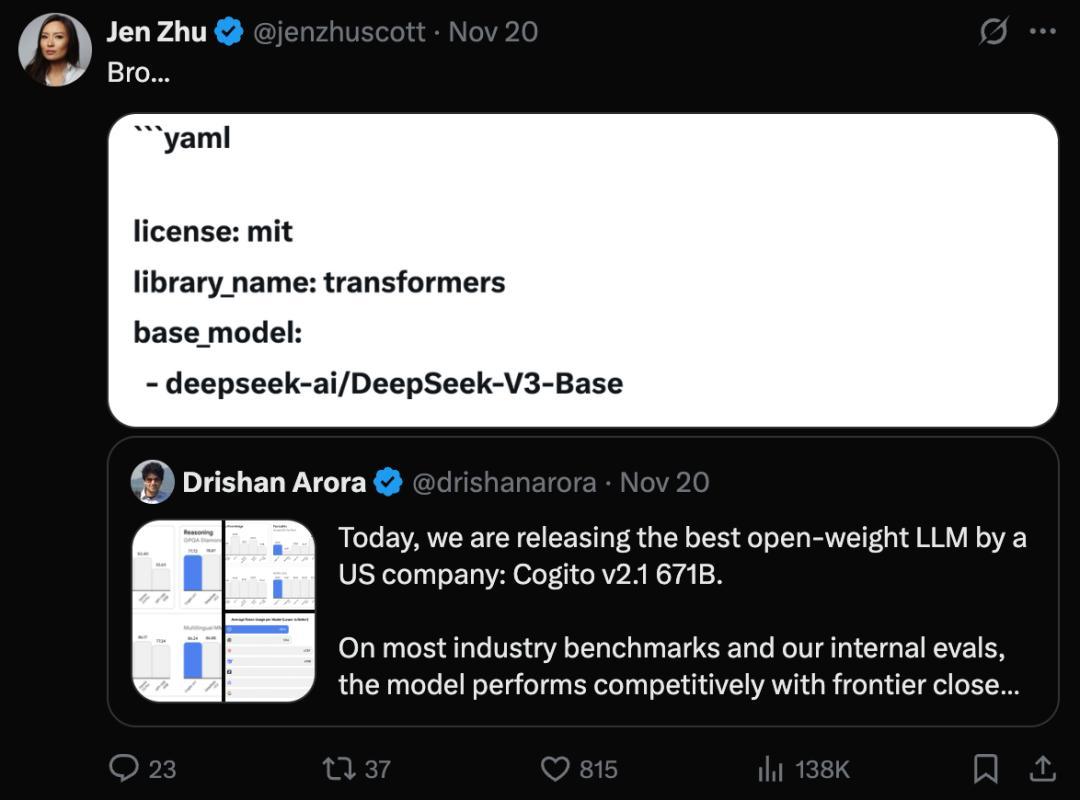
圖丨相關推文(來源:X)
不過,與此前 Cursor 那種死鴨子嘴硬直到被抓包才承認的態度不同,Deep Cogito 完全沒打算藏着掖着。Drishan Arora 表現得相當坦蕩。他直接承認了分叉(fork)自 DeepSeek-V3-Base,並解釋道:在今天的 AI 領域,預訓練(Pre-training)已經變成了像發電一樣的通用商品(commodity)。
“真正困難的問題,是如何將一個基礎模型進行後訓練(Post-training),使其達到前沿智能的水平。”他還補了一刀:“具有競爭力的前沿開源模型,只有極少數大型研究實驗室發佈過。而在美國,除了 Meta,幾乎沒有其他選擇。”也因此,DeepSeek 是一個顯而易見的選擇, 因爲 DeepSeek 架構周圍已經建立了廉價推理的生態系統。
既然底座是別人的,那 Deep Cogito 到底造了什麼?
正如我們此前在關於 Cogito v1 發佈的報道中所提及,這家由 DeepMind 前產品經理和 Google 前高級工程師聯手創立的公司,從一開始就不是爲了“從零開始預訓練”而生的。在他們看來,目前大多數預訓練模型的能力都在趨同。在這種背景下,競爭的焦點已經從預訓練轉向了後訓練。
Deep Cogito 的核心在於一套被稱爲“前沿後訓練棧”的技術。簡單來說,他們基於了 DeepSeek 的基礎模型,利用自己獨創的強化學習算法和迭代蒸餾放大(IDA,Iterated Distillation and Amplification)技術,對其進行了極其複雜的“再教育”。
根據官方披露的技術細節,他們利用了數百個 GPU 節點進行了大規模的分佈式強化學習。與其前代產品 Cogito v1 相比,v2.1 在推理效率上實現了巨大進步。在達到同等推理能力的水平下,Cogito v2.1 消耗的 Token 數量顯著低於競爭對手。例如,在處理複雜邏輯問題時,Cogito v2.1 平均消耗 4894 個 Token,而 Google 的 Gemini 2.5 Pro 則高達 9,178 個。
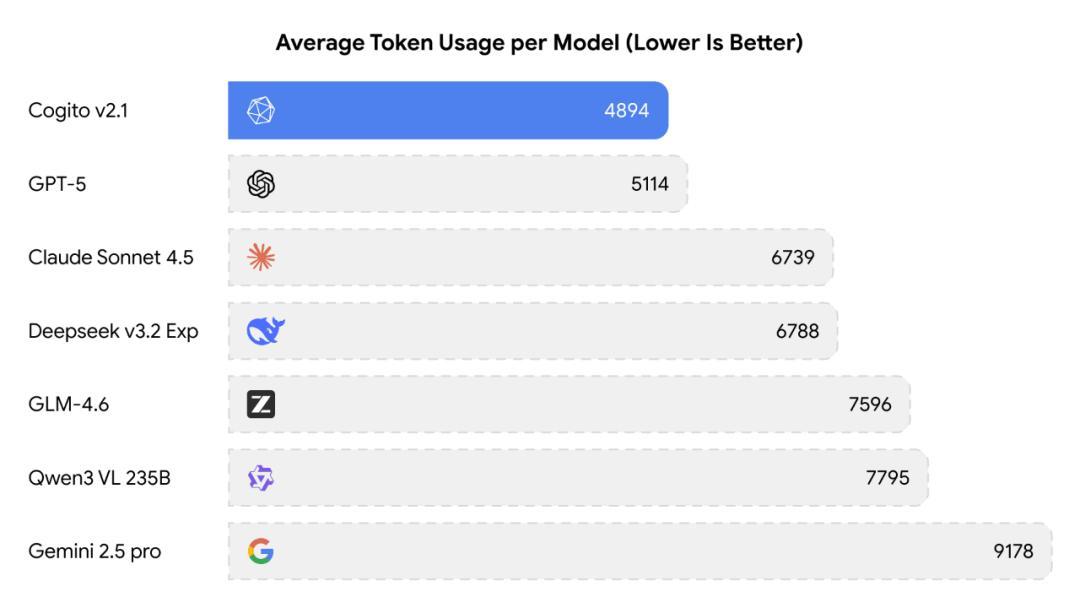
圖丨平均使用的 token 數對比(來源:Deep Cogito)
Deep Cogito 的技術團隊將其歸功於“過程監督”(Process Supervision)。傳統的推理模型往往通過生成冗長的思維鏈(Chain of Thought)來逼近答案,這既費時又費錢。而 Cogito v2.1 通過強化學習,培養了模型更強的直覺,使其能夠以更短的搜索路徑找到正確的推理軌跡。這種“少即是多”的能力,恰恰是 IDA 方法論的體現,即不僅要讓模型會思考,還要讓它高效地思考。
在數學基準測試 MATH-500 中,Cogito v2.1 得分 98.57%,微弱優勢領先於“老師”DeepSeek v3.2(97.87%),且大幅領先於 Llama 4 Scout。在代碼修復任務 SWE-Bench Verified 中,它也展現出了比較出色的解決率。
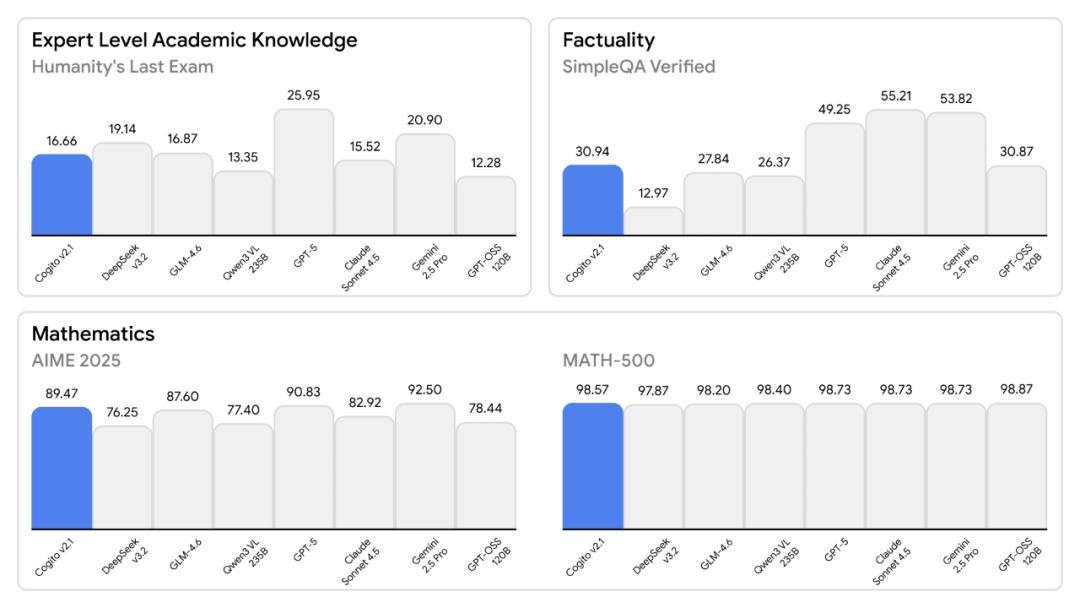
圖丨基準測試結果(來源:Deep Cogito)
客觀而言,Cogito v2.1 確實是一款性能不錯的模型。在代碼修復、數學推理等任務上都展現出了出色的能力,而且在推理效率上實現了有價值的突破。Deep Cogito 在後訓練方面投入的技術努力也值得認可,將一個基礎模型訓練到前沿水平,並在效率上有所創新,本身就需要深厚的技術積累。
而且,Deep Cogito 在技術文檔中明確標註了使用 DeepSeek-V3-Base 作爲基礎模型,並沒有刻意隱瞞這一事實。只是一個模型的基礎架構、核心參數規模都來自中國的 DeepSeek,只是在後訓練階段由美國公司完成優化,就宣稱這是“由美國公司製造的最好的開源大語言模型”,確實有些言過其實。
另外還要夾帶私貨,在模型中植入特定意識形態傾向的做法,也偏離了開源精神的初衷,讓人有所不齒。
只能說,Deep Cogito 的這一舉動實際上是在 Cursor 和 Windsurf 事件之後,又一次印證了中國開源 AI 模型在全球範圍內日益增長的影響力。
無論對於哪個國家的 AI 初創公司或者開發者來說,基於中國開源模型進行開發已經成爲一種務實的選擇。從零預訓練一個 671B 規模的模型需要數千萬甚至上億美元,而基於現成的高質量開源模型進行後訓練優化,不僅成本低廉,還能快速推向市場。這種實用主義的選擇,本身並無可厚非。
而 Deep Cogito 這種“既要技術裏子,又要地緣面子”的矛盾心態,恰恰折射出部分硅谷從業人員在面對新興競爭對手時複雜的心理活動:既無法忽視對方的技術價值,又難以完全放下長期以來的領跑者身段。
這種執念背後,或許是對技術競爭被簡化爲國家競賽的焦慮,但它恰恰忽視了開源生態最寶貴的特質:超越地域的協作與創新。真正的技術自信,應該體現在坦誠的態度和實實在在的創新貢獻上,而不是包裝出來的“X 國最強”敘事。
參考資料:
1.https://www.deepcogito.com/research/cogito-v2-1
2.https://x.com/drishanarora/status/1991204769642475656
運營/排版:何晨龍



