

大型語言模型(LLM)的“大”既是智慧的象徵,也是落地的枷鎖。模型規模越來越大,計算資源、內存佔用、能耗和部署成本急劇上升,這讓許多企業和開發者難以實際應用其前沿能力。
2 月 24 日,一家西班牙初創公司 Multiverse Computing 在 Hugging Face 平臺免費開放其最新壓縮模型 HyperNova 60B 2602 的完整訪問權限。
這是這家公司過去發佈多款開源壓縮模型的延續,今年 1 月份,他們開放了基於 OpenAI 開源模型 gpt-oss-120B 的 50% 壓縮版本,HyperNova 60B。這次又在工具調用和代理式工作流上實現顯著迭代。他們試圖用量子計算技術打破這一僵局,以“身量減半、性能不減”的姿態,向全球開發者展示了模型輕量化的新路徑:無需鉅額基礎設施,即可調用接近前沿水平的 AI。
量子技術啓發模型壓縮:身量減半、性能不減
Multiverse Computing 成立於 2019 年,創始理念源於創始人恩裏克·利薩索(Enrique Lizaso)與量子物理學家羅曼·奧魯斯(Román Orús)的一次 WhatsApp 聊天,他們討論了將量子技術應用於金融複雜問題的可能性,並迅速邀請營銷專家阿方索·魯比奧(Alfonso Rubio)和計算物理學家塞繆爾·穆格爾(Samuel Mugel)加入,還獲得了西班牙巴斯克地區政府的支持孵化。
公司最初深耕於金融領域的量子計算軟件開發,這種通過量子方法解決複雜優化問題的思路,之後也被逐步擴展到 AI 模型的“瘦身”領域。
現在,Multiverse Computing 已將自身定義爲“量子啓發 AI 模型壓縮領域的領導者”。其專有技術 CompactifAI 正是這一路線的結晶。

(來源:Multiverse)
在傳統壓縮方法中,剪枝、蒸餾和低秩近似專注於減少網絡中的有效神經元數量,量化的重點則放在了降低單個權重的數值精度,以在保持神經元數量不變的情況下減小模型尺寸。
CompactifAI 另闢蹊徑,將量子計算中的張量網絡(Tensor Networks)數學思路應用於神經網絡分析與重組,關注模型的關聯空間,僅保留信息最豐富的核心組件,從而實現更可控、更精細和更可解釋的模型壓縮。
Multiverse 的研究團隊在 2024 年發表論文《CompactifAI:基於量子啓發式張量網絡的大型語言模型極致壓縮》(CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks,arXiv:2401.14109),首次詳細闡述了 CompactifAI 的工作原理和具體技術路徑:
對模型的自注意力(Self-Attention, SA)層和多層感知機(MLP)層進行“張量化”(tensorizing),使用特定張量網絡(Tensor Network)結構;通過控制鍵維度(bond dimension)精確截斷模型中的相關性(correlations),從而大幅減少參數數量和內存佔用;壓縮後,通過多 GPU 分佈式再訓練(稱爲“healing”過程)恢復精度,確保模型在更小規模下仍保留高級推理能力。
測試顯示,CompactifAI 最高可將模型體積減少 95%,精度損失僅控制在 2%~3% 以內。相比之下,行業標準的壓縮技術在進行 50%~60% 的壓縮時,精度卻出現了 20%~30% 的大幅下降。
這一方法不僅顯著降低訓練和推理時間(訓練時間可縮短 50%、推理時間縮短 25%),還極大減少了 GPU-CPU 數據傳輸開銷,使其特別適合分佈式訓練場景。CompactifAI 可獨立使用,也可與其他壓縮技術結合,進一步放大效果。
HyperNova 60B 2602 是基於 OpenAI 開源模型 gpt-oss-120B 的 50% 壓縮版本。原始模型大小約 61GB,新模型僅爲 32GB,參數規模降至約 60B,同時大幅降低了內存佔用和推理延遲。
相比 1 月份的初版 HyperNova 60B,本次更新聚焦於工具調用(tool calling)和代理式編碼(agentic coding),這些正是推理成本較高的核心場景。
公司表示,更新版在真實開發者反饋基礎上進行了針對性優化,相對於前版,其具體基準均有顯著提升:代理工具使用能力(Tau2-Bench)提升 5 倍、代理編碼與終端使用性能(Terminal Bench Hard)提升 2 倍,函數調用(BFCL v4)能力也是原來的 1.5 倍。
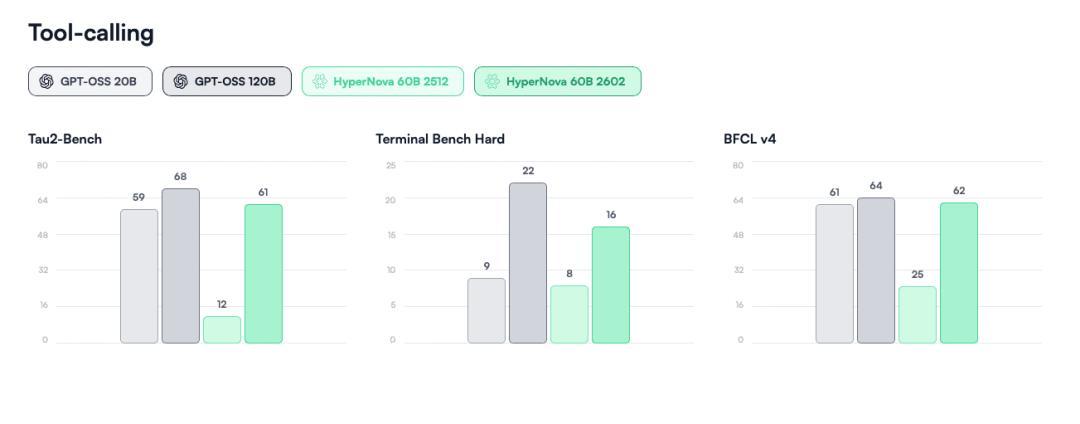
(來源:Multiverse)
整體而言,HyperNova 60B 2602 在工具調用能力上已經接近原始 120B 開源模型的水平,大小卻只有原來的一半。這一成果驗證了壓縮技術在生產級 AI 部署中的可行性:開發者可在資源受限環境下實現前沿級代理工作流,同時無需承擔鉅額基礎設施開銷。
Hugging Face 模型頁面進一步提供了完整基準、技術文檔和集成指南,支持 8-bit 精度和 mxfp4 量化,適用於 vLLM 等高效推理框架。
歐洲主權 AI 的曙光
目前,Multiverse Computing 已在美國、加拿大及歐洲多地設立辦公室,服務包括西班牙能源巨頭伊維爾德羅拉電力公司(Iberdrola)、德國工業巨頭博世(Bosch)以及加拿大銀行等在內的 100 餘家全球企業客戶。
Multiverse 強調,HyperNova 系列專爲真實世界部署設計,覆蓋企業系統、研究機構、公共部門,以及邊緣設備和終端級應用。通過開源策略,組織可在承諾大規模實施前輕鬆評估性能、安全性和運營適配性,只需最小化集成工作即可獲得更高控制權和獨立性。
2025 年,公司完成約 1.89 億歐元(約合人民幣)的 B 輪融資,西班牙技術轉型局(SETT)等機構參與投資。據相關消息,公司正在今年 2 月推進新一輪約 5 億歐元(約合人民幣)的融資談判,估值可能超過 15 億歐元。考慮到 Multiverse 曾宣稱可“在 AI 全棧提供主權解決方案”,這一增長勢頭或與歐洲對“非美科技替代方案”的迫切需求密切相關。
近期,公司還與西班牙東北部阿拉貢地區政府達成合作,進一步強化其在歐洲主權 AI 生態中的位置。
未來,這一壓縮技術將大幅降低模型使用的准入門檻,開發者不再受海量 LLM 基礎設施的制約,可自由測試、迭代和部署高級 AI;此外,還有望引發一場成本與能耗革命:用更低的算力、內存和功耗保留“智能”,實現更綠色、更經濟的 AI。
最後,在 AI 競爭中已經不佔優勢地位的歐洲地區,壓縮技術有望支持私有云、on-premise 或邊緣部署,幫助歐洲及全球企業減少對外部巨頭的依賴,保障數據安全與技術自主。
正如公司 CEO Enrique Lizaso Olmos 所言,“HyperNova 60B 2602 的推出展示了壓縮作爲迭代改進過程而非一次性優化的本質。每代壓縮模型都推動高效 AI 的邊界。”公司計劃在 2026 年持續發佈更多不同尺寸的開源壓縮模型,進一步拓展從企業級到設備級的應用場景。
開發者現可訪問以下鏈接免費試用:
HyperNova 60B 2602 模型頁:https://huggingface.co/MultiverseComputingCAI/Hypernova-60B-2602
公司 Hugging Face 空間(含全部發布、基準與指南):https://huggingface.co/MultiverseComputingCAI
參考資料:
https://techcrunch.com/2026/02/24/spanish-soonicorn-multiverse-computing-releases-free-compressed-ai-model/
https://multiversecomputing.com/resources/multiverse-computing-opens-full-access-to-hypernova-60b-2602-on-hugging-face
https://arxiv.org/abs/2401.14109
運營/排版:何晨龍



