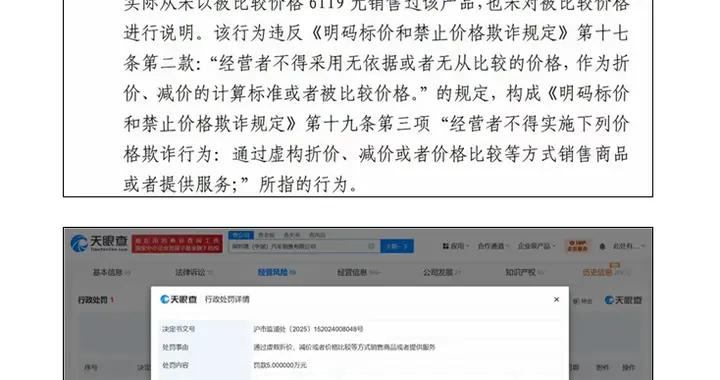
“它不僅看得見、聽得到,還記得你說過的話,知道什麼時候做出反應。”
去年的谷歌 I/O 開發者大會上,多模態 AI 助手 Project Astra 首次亮相。當時它更像是一種概念驗證。
而在今天的谷歌 I/O 大會上,Project Astra 以一種更令人驚歎的方式進化了,谷歌 DeepMind 展示了它在實時感知、語境理解、邊緣設備運行等方面的全新能力:它能通過手機或智能眼鏡識別物體、追蹤用戶語音指令,並對環境中的動態變化做出快速反應,真正融入人類的現實生活。
“Astra 可以根據它看到的事物選擇何時說話。”DeepMind 研究總監 Greg Wayne 表示,“實際上,它一直在持續觀察,然後發表評論。”
這意味着:它能夠代表你完成任務,即使你沒有明確要求;它還可以根據所看到的內容選擇性“發言”,比如指出作業中的錯誤。
Project Astra 仍然是一個試驗項目,公衆或許很久都沒有機會體驗它,但它的升級,代表着谷歌的 AI 戰略野心。它的背後,是谷歌正在以 Gemini 爲核心,構建一個貫穿搜索、創作、辦公、助手系統的 AI 應用世界。

圖 | 圍繞 Gemini 的更新(來源:谷歌)
從文本生成圖像與視頻,到智能回覆郵件和工作流整合,再到與用戶實時對話的語音交互——Gemini 已不只是聊天工具,而是逐漸成爲谷歌全產品線的大腦。
因此,在 I/O 2025 大會上,谷歌用來打頭陣的就是 Gemini。
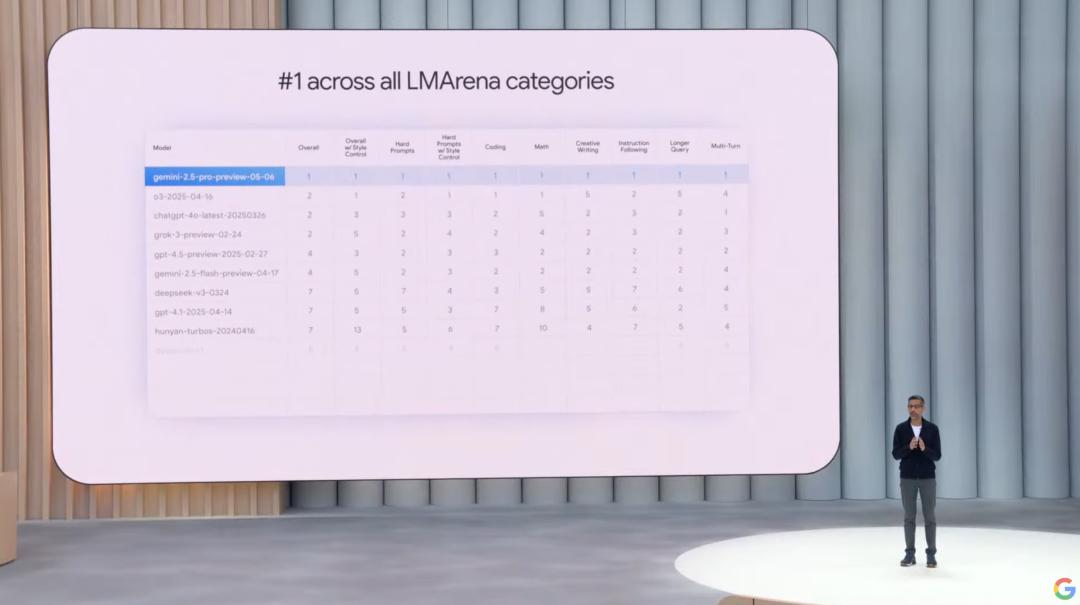
圖 | 谷歌 CEO 展示 Gemini 2.5 Pro 模型排名(來源:谷歌)
谷歌CEO Sundar Pichai 表示,最新的 Gemini 2.5 Pro 模型(preview-05-06 版)已經在 LMArena“屠榜”,所有測試均排第一。
同時,谷歌還帶來了新的模型升級。Gemini 2.5 Pro 新增了一種名爲 Deep Think 的強推理模式,該模式專爲與數學和編程相關的複雜查詢而設計,能夠在回應前"考慮多種假設",但目前僅向可信測試者開放。
開啓 Deep Think 模型的模型在多模態推理測試 MMMU 中獲得了 84% 的準確率。
該公司還補充說,該模式在 2025 年美國數學奧林匹克競賽 (USAMO) 中取得了“令人印象深刻的成績”,但並未公佈確切分數。
此外,上個月發佈在 Pixel 手機上的 Gemini Live 應用將登陸所有兼容的 Android 和 iOS 設備,可通過 Gemini 應用程序使用(谷歌透露該應用已擁有超過 4 億月活躍用戶)。
該應用允許用戶詢問 Gemini 關於截圖的問題,以及手機攝像頭正在捕捉的實時視頻內容。

Gemini 重塑搜索體驗
另一個新進展是,谷歌宣佈將 Gemini 進一步集成到 Chrome 瀏覽器中。
從5 月 21 日開始,Google AI Pro 和 Ultra 訂閱用戶可以看到 Chrome 中的 Gemini 按鈕,以跨網頁總結信息,並幫助他們更好地瀏覽網站。谷歌計劃今年晚些時候讓 Gemini 能夠同時處理多個標籤頁。
在此基礎上,谷歌宣佈了搜索引擎將加入新功能,AI Mode。
這項功能位於單獨的標籤頁中,旨在處理比傳統搜索更復雜的查詢。用戶可以利用它比較不同品牌的同類商品,或尋找最便宜的門票。該功能將首先向美國用戶開放。
AI Mode 還爲購物功能帶來了重大升級。用戶很快就能上傳一張自己的照片,來虛擬試穿衣服,查看服裝在真實人物上的效果。谷歌正在測試這一新功能,該功能利用“瞭解人體和服裝細微差別”的 AI 模型來實現試穿效果。
據谷歌透露,每月已有超過15 億人次看到 AI 生成的搜索概覽(AI Overviews),而且絕大多數用戶都以有意義的方式與之互動。
AI Mode 將使用 Gemini 2.5 模型,並將很快能夠根據特定查詢生成自定義圖表和圖形。它還能夠處理後續問題,使搜索體驗更加連貫自然。
同時谷歌還推出了名爲 Search Live 的功能,允許用戶通過選擇 AI Mode 或 Lens 中的 Live 圖標,實時討論手機攝像頭看到的內容。這項功能未來將從谷歌 Astra 項目中汲取靈感,進一步擴展搜索引擎的能力範圍。
作爲安全增強措施,Chrome 的密碼管理器也將得到更新。如果 Chrome 檢測到您的密碼已被泄露,瀏覽器將很快能夠“生成強大的替代密碼”,並在支持的網站上自動更新它(如果用戶同意)。此功能將於今年晚些時候推出。

AI 創作工具升級:Imagen 4、Veo 3 和 Flow
接下來,谷歌宣佈了圖像生成和視頻生成模型的更新。
AI 創作工具是本次大會的另一大亮點。谷歌推出了全新圖像生成模型 Imagen 4,在輸出圖像的細節、構圖和風格控制上“實現了明顯提升”,更擅長處理布料和毛皮等精細細節。

圖 | Imagen 4 生成的圖片 (來源:谷歌)
“Imagen 4 可以創建各種寬高比的圖像,分辨率高達 2k,更適合打印或演示。它在拼寫和排版方面也得到了顯著提升,讓用戶可以更輕鬆地創作自己的賀卡、海報甚至漫畫。”谷歌表示。
而新一代視頻生成模型 Veo 3 不僅提高了生成質量,而且首次可以生成帶有音頻的視頻,包括城市街道場景背景中的交通噪音、公園裏鳥兒的歌唱,甚至人物之間的對話。

圖 | Veo 3展示(來源:谷歌)
結合上述模型的進步,谷歌還推出了一款名爲 Flow 的新型 AI 電影製作應用,類似於 OpenAI Sora。
它是 VideoFX 的升級版,使用 Veo、Imagen 和 Gemini 來創建基於文本提示和/或圖像的視頻片段。該工具還提供場景構建工具,可將剪輯拼接在一起,創建更長的 AI 視頻。
Flow 具備攝像機移動和透視控制等功能,允許編輯和擴展現有鏡頭,還能將 Veo 模型生成的 AI 視頻內容融入更復雜的項目中。
Flow 從今天開始向美國的谷歌 AI Pro 和 Ultra 訂閱用戶開放,很快將擴大到其他市場。
爲了幫助用戶確定內容是否由 AI 工具生成,谷歌設計了一種工具,名爲 SynthID Detector,它可以掃描圖像、音頻、視頻或文本中的 SynthID 水印,並讓用戶知道哪些部分可能帶有水印。早期測試人員將從今天開始嘗試使用這一工具。

Project Aura:新的 XR 眼鏡
谷歌還展示了自己在 Android XR 領域取得的新進展。

圖 | Project Aura 新智能眼鏡(來源:谷歌)
Android XR 平臺是谷歌爲增強現實、混合現實和虛擬現實開發的平臺,希望能複製 Android 系統在智能手機領域的成功。
基於此,谷歌宣佈了第二款官方 Android XR 設備:Project Aura,一款智能眼鏡。
Xreal 和谷歌正在合作開發 Project Aura,它將是一款使用 Android XR 平臺的新型智能眼鏡。目前關於這款眼鏡的信息不多,但它將集成 Gemini,擁有大視場,預計將使用高通芯片,以及內置攝像頭和麥克風。

圖 | 新眼鏡演示(來源:谷歌)
在 Android XR 的演示中,谷歌展示了實時翻譯功能,但使用的是與三星共同開發的智能眼鏡(Project Moohan)於今年初公佈的)。
除了上述大更新外,谷歌還在生產力場景中加入了 AI 技術。
Gmail 將大規模引入基於 Gemini 的智能回覆功能,可從用戶過往郵件、谷歌雲盤文件中提取背景信息,生成更精準、定製化的回覆內容。用戶在閱讀郵件時,也可調出 Gemini 側邊欄,獲取總結、要點提取和後續操作建議。
谷歌 Workspace 中的 Docs、Sheets、Slides 等工具也將陸續集成 Gemini,幫助用戶更高效地處理長文檔、製作數據報告或撰寫內容提案。
谷歌還宣佈了一個新的 3D 視頻會議項目,Google Beam。目前僅面向企業客戶。
這套系統也集成了 AI 技術。它使用光場顯示技術,不需要佩戴任何特殊設備,而是通過六個攝像頭陣列捕捉不同角度,然後用 AI 將這些圖像拼接在一起,使用頭部跟蹤功能跟蹤用戶的動作,並以每秒最高 60 幀的速度傳輸。
最後,谷歌推出了高達每月 250 美元的 AI Ultra 訂閱計劃。這個價格比 OpenAI 的 200 美元 Pro 計劃還要貴。
谷歌表示,該計劃將包括對其最新 AI 工具的早期訪問權限,以及無限使用對谷歌來說成本高昂的功能,如 NotebookLM、Deep Research 和最新推出的 Flow,都將解除使用次數上限。此外,它還提供 30TB 的存儲空間,以及 YouTube Premium 服務。
可以看出,與嘗試統治 AI 代理生態系統的微軟不同,谷歌在此次 I/O 大會上更多展示的是應用層面的更新,將以 Gemini 爲核心的 AI 技術全面拓展到自家產品中。
對於普通用戶而言,這樣或許能夠更直觀地感受到 AI 帶來的價值。
參考資料:
https://io.google/2025/
https://deepmind.google/models/project-astra/
https://www.theverge.com/news/669408/google-io-2025-biggest-announcements-ai-gemini
https://www.engadget.com/ai/google-io-2025-recap-ai-updates-android-xr-google-beam-and-everything-else-announced-at-the-annual-keynote-175900229.html
排版:初嘉實