

近日,美國弗吉尼亞大學教授沈聰和團隊提出一種多示例自適應僞標註方法——MAPLE(Many-Shot Adaptive Pseudo-LabEling)。它是一種專門用於提升大語言模型在多示例學習中表現的新機制,特別適用於只有少量標註數據、但有很多未標註數據的情況。

圖 | 沈聰(來源:沈聰)
在傳統的大語言模型應用中,往往需要大量人工標註的數據,這既昂貴又耗時。研究團隊的工作想解決的是:如何充分利用這些“還沒標註”的數據,幫助模型更好地完成任務?爲此研究團隊設計了兩個關鍵技術:
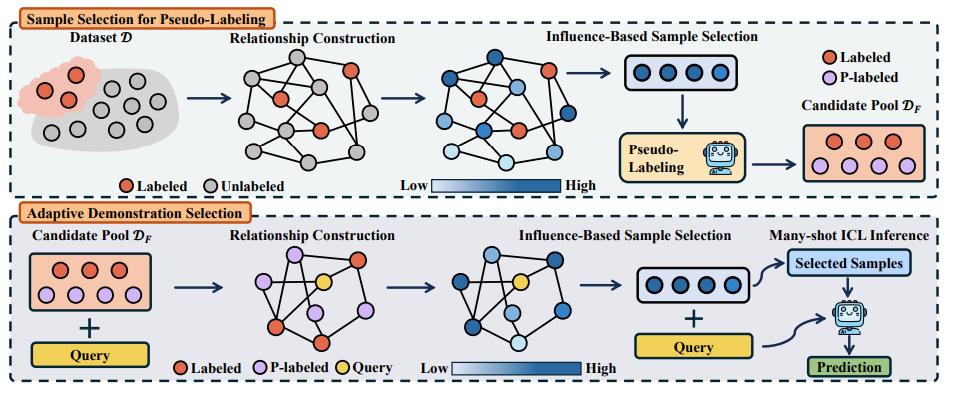
1. 僞標籤樣本的挑選方法:他們通過構建一個圖,把已標註和未標註的數據聯繫起來,挑選出對任務最“有影響力”的未標註樣本,並使用大語言模型給它們打上“僞標籤”。這樣一來,模型就能從這些有代表性的樣本中學到更多。
2. 自適應示例選擇策略:對於每個測試問題,他們會根據它的特點,從標註樣本和僞標籤樣本中智能地挑選出最相關的幾個示例,而不是用一套固定模板。這樣能更有效地提高模型的準確性和泛化能力。
研究團隊做了大量實驗,證明這種方法不僅能減少對昂貴標註數據的依賴,還能在多個真實任務中表現優異。對於相關論文,審稿人認爲本次研究爲大語言模型在低標註場景中的應用提供了一條可行路徑。
這一成果可被用於需要智能處理文本、但缺少大量人工標註數據的場景中,能夠爲多示例學習生成大量僞標註的數據。
舉例來說:
首先,可用於客服和問答系統:很多公司有着大量的歷史對話數據,但是沒有標註問題類型。本次方法可以利用這些未標註數據,幫助大語言模型更好地理解和回答用戶的問題,而不需要人工標註大量示例。
其次,可用於醫療、金融等專業領域的智能助手:這些領域的標註成本很高,本次方法可以使用少量專家標註數據,再加上大量的未標註案例就能構建更精準的問答系統或摘要系統。
再次,可用於教育類場景:比如自動生成講解或習題反饋。很多題目或學生回答是未標註的,而本次方法可以幫助模型學會更好地給出解釋,進而達到輔助教學的作用。
最後,可用於低資源語言或小語種的AI 應用場景:對於缺乏標註數據的語言,可以通過僞標籤機制挖掘未標註資源,加速這些語言的 AI 系統落地。
總的來說,這項成果可以幫助大語言模型在數據不足的實際環境中“用少量帶動多數”,更高效地發揮作用,讓AI 走進更多行業、更多場景。
(來源:ICML)
據瞭解,上下文學習(ICL,In-context Learning)是讓模型通過提示中的幾個例子學會如何完成任務,而不需要重新訓練它。隨着大語言模型的更新換代,新的模型可以接受更長的文本輸入,這爲上下文學習提供了新的機遇。Google 的研究人員在 2024 年的論文中提到通過增加提示中例子的數量可以提升上下文學習的性能,並將其稱之爲多示例上下文學習(Many-shot ICL)。
本次研究團隊注意到,爲了充分發揮多示例上下文學習在給定任務上的潛力,往往需要一個包含大量屬於該任務帶標註樣本的數據集,而標註大量數據所需的成本有限制了獲取這樣的數據集的難度,特別是在一些新領域或者較難的任務下。基於以上原因,研究團隊進行了這次研究。他們希望充分利用大語言模型的能力來獲得僞標註數據,從而用於多示例上下文學習。特別地,研究團隊考慮了這樣一個問題:在擁有少量標註數據的情況下,如何選擇未標註的數據進行僞標註,從而讓僞標註數據和少量真實標註的數據可以爲一起多示例上下文學習提供高質量的例子。
與此同時,在本次研究之中,研究團隊還解決了以下兩個問題:
第一個是關於模型穩定性的問題。最初研究團隊的設想非常理想化:希望只用一些未標註的數據(只提供問題),再加上一小部分標註數據,直接作爲多示例輸入給大語言模型進行學習。這樣的方法從資源角度看是最節省的,他們也覺得這纔是“最純粹”的方式。但是,實驗做下來卻發現效果非常不穩定,有時候能提升,有時候反而拖後腿。爲此,沈聰和學生們試了很策略但都無法根本解決這個問題。後來,他們做了一個艱難的決定——“退而求其次”轉向使用僞標註的方式來輔助選樣。雖然不如原先設想得那麼“優雅”,但是確實讓模型的性能提升變得更加可控、更加穩定。“這也讓我的學生們第一次意識到,爲了解決實際的問題,理想化的思路和實際限制之間經常要做權衡和取捨。”沈聰表示。
第二個是研究團隊找到最終選樣方法的靈感來源。其實他們一直在尋找一個既高效又有效的方法來從未標註數據中選出“關鍵樣本”。有一次在組內討論時,突然有學生聊到他之前曾推導過一些圖結構中影響力相關的理論,但因爲當時項目方向不同,這一部分一直沒用上。研究團隊研究了他的推導記錄,發現這些思想其實可以完美應用在這一問題中——只要做一些針對性的調整。於是學生們修改推導、搭建實驗,沒想到真的跑出來了不錯的結果。
這兩個經歷一個是現實妥協下的選擇,一個是偶然中的“靈光一閃”,但它們都讓沈聰的學生們對於科研有了更多敬畏和更多熱愛。
最終,相關論文以《MAPLE:多輪自適應僞標記上下文學習》(MAPLE:Many-Shot Adaptive Pseudo-Labeling In-Context Learning)爲題發在第 42 屆國際機器學習大會(ICML,International Conference on Machine Learning)上 [1]。

圖 | 相關論文(來源:ICML)
後續:
第一,研究團隊希望進一步提升僞標籤的質量和魯棒性。雖然現在的方法已經能選出對於模型推理有幫助的未標註樣本並進行僞標註,但仍然存在一些誤標或不穩定的情況。特別是他們觀察到在一些任務上使用更多僞標註的數據會導致性能的下降,其認爲這可能是僞標註的標籤引入的噪聲所導致的。接下來他們會探索是否可以引入不確定性估計、集成模型,或者藉助大語言模型自身的反饋機制,來判斷哪些僞標籤更可信,從而提升整體效果。
第二,研究團隊想把這套機制拓展到跨任務或跨領域的場景中。現實中很多任務來自不同的數據分佈,比如金融、醫療、教育等,如能使用一個任務中少量的標註,配合另一個任務的未標註數據,仍然能夠實現有效的多示例學習,就會極大提升大語言模型的實際適應能力,而這也涉及到如何在任務之間遷移影響力建圖策略和示例選擇策略。
參考資料:
1.https://arxiv.org/abs/2505.16225



